前言
深度学习网络的加速问题包含两部分内容:网络结构侧的加速和工程侧的加速。网络层面的加速主要从网络结构上进行优化,关注点在于网络的计算量和参数量上。
详细介绍
网络加速
对于图像检测领域来说,网络侧速度的瓶颈更多还是在于其Backbone上,所以很多网络加速Tricks都是基于Backbone开展的,以下介绍三种常用的轻量级网络:SqueezeNet,MobileNet,ShuffleNet。
从中可以了解轻量级网络设计上的一些通用策略。另外这里补充了另一个网络:OneNet,该网络主要探讨了物体检测的 去NMS 方案。最后,补充一种即插即用的网络加速策略:网络剪枝。
SqueezeNet
SqueezeNet于2017年发表于ICLR,当时发表时声称性能于AlexNet相近,但是模型参数量只有AlexNet的1/50。其核心结构为 Fire module ,整体网络基于该模块组合而成: 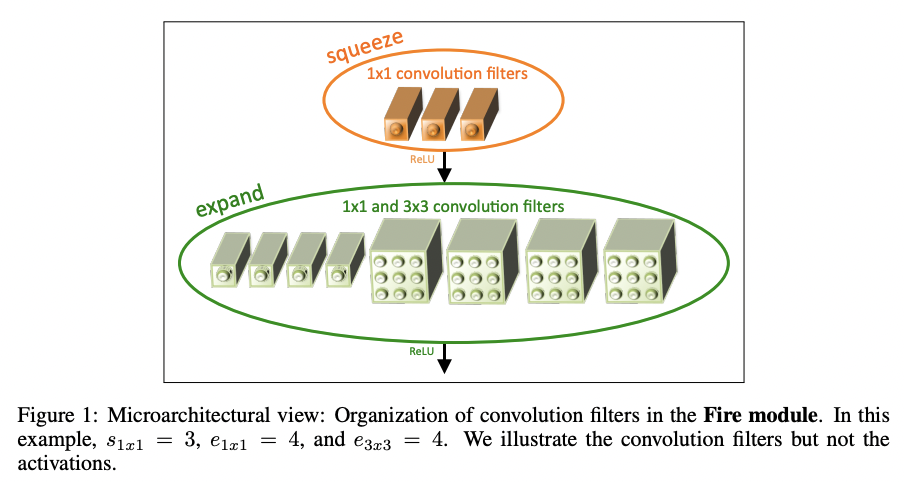 该模块包括两个部分:
该模块包括两个部分: squeeze 和 expand :
其中squeeze层的作用是通过1x1卷积进行通道降维,达到压缩的目的。然后expand层并行包含两类卷积:3x3和1x1卷积,其目的在于获得不同大小的感受野。最后再将expand层获得所有feature map进行concat得到最终的feature map输出。可以看到SqueezeNet的关键在于两个方面:
- 减小卷积核: 从AlexNet到SqueezeNet,可以发现尽量避免使用大的卷积核,或者可以采用多个小卷积核操作替换大卷积核操作(感受野一样,但是参数量更少,且效果更好)
- squeeze-expand操作:squeeze的操作在于减少计算量,expand操作在于减少精度下降。在后续的Inception系列的网络上都可以看到此类操作的影子(Inception系列可参考:2D_Detection-BackBone)。
MobileNet
MobileNet是轻量化网络的经典之作,其关键在于提出了 可分离卷积 ,对于可分离卷积在2D_Detection-基本深度学习单元中有所介绍。
其核心在于将普通卷积分为两个部分: 深度卷积 和 点卷积 ,其卷积方式演化为:先对输入的feature map(假设channel数为M)的每个channel进行单独的卷积操作,然后concat得到中间状态的featuemap,然后再通过点卷积(1x1xMxN)得到chnnel数为N的最终feature map。普通卷积和可分离卷积的计算量比值为$1/N + 1/(D_k*D_k)$,$D_k$对应的是深度卷积采用的卷积核大小(一般为3),因为N值一般较大,所以最终的计算量比值接近1/9。其核心结构图例如下: 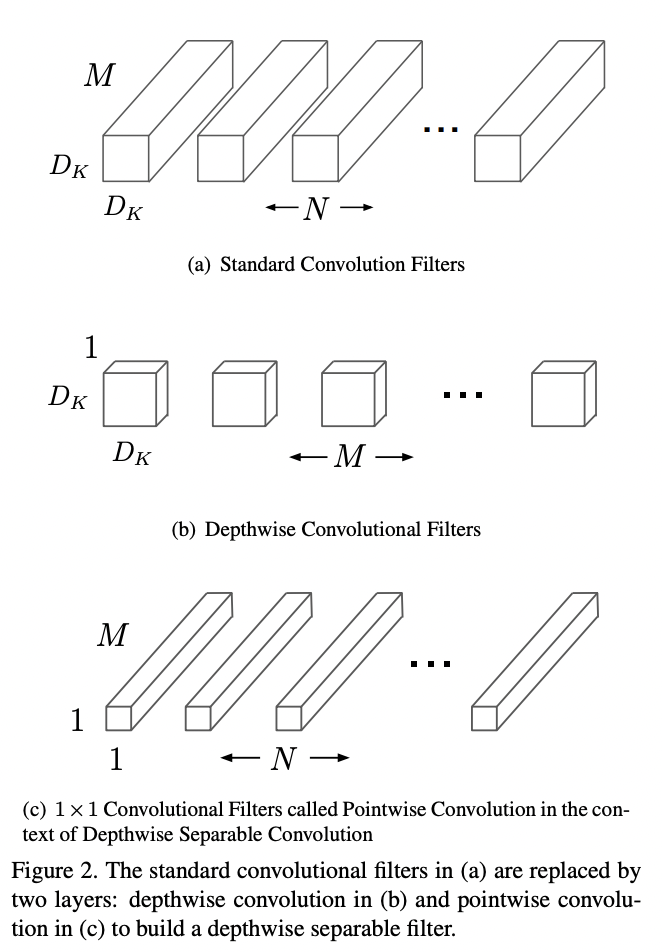
当然采用可分离卷积还是有一定的精度损失,后续MobileNetV2,MobileNetV3也在V1基础上进行了一系列的优化,目的是维持其轻量化的前提下提升其精度,后续的提升手段包括: MobileNetV2:
Inverted Residual Block: 其核心为两个部分:残差结构+沙漏结构。残差结构参考ResNet,沙漏结构的关键同样利用了1X1网络结构来进行升维和降维操作,顺序为:1x1升维->可分离卷积->1x1降维。ReLU6: MobileNetV1采用ReLU6函数: $relu6(x)=min(max(x, 0), 6)$。该激活函数的优势在于限制了ReLU的输出值范围,使得在移动端设备上的FP16低精度模式上依然能有很好的数值分辨率。但是该激活函数的问题是其对特征输出带来的损失,因为其在两端都做了截断处理。尤其在低维特征上,损失更为明显。因此MobileNetV2采用的损失函数策略是:高维特征输出(1x1升维和可分离卷积输出)仍然采用ReLU6激活函数,但在降维后直接采用线性激活函数。
MobileNetV3:
精调网络结构:作者主要对尾部结构进行网络结构的调整,核心思想还是基于1X1卷积网络进行维度变化,减小feature map,从而降低计算量:

引入SE模块:即插即用的模块,其核心是添加了通道的注意力模块。作者在引入该模块的适合采用了一定的技巧,减少SE模块的时间消耗:将SE模块放在深度卷积后,且现将池化后的channel特征通过fc缩小4倍然后再经过fc回去,再和深度卷积后的特征按照位相加:
激活函数:核心是
sigmoid激活函数较慢,采用h-swish激活函数,该函数基于ReLU实现,速度更快,兼容性更好些。
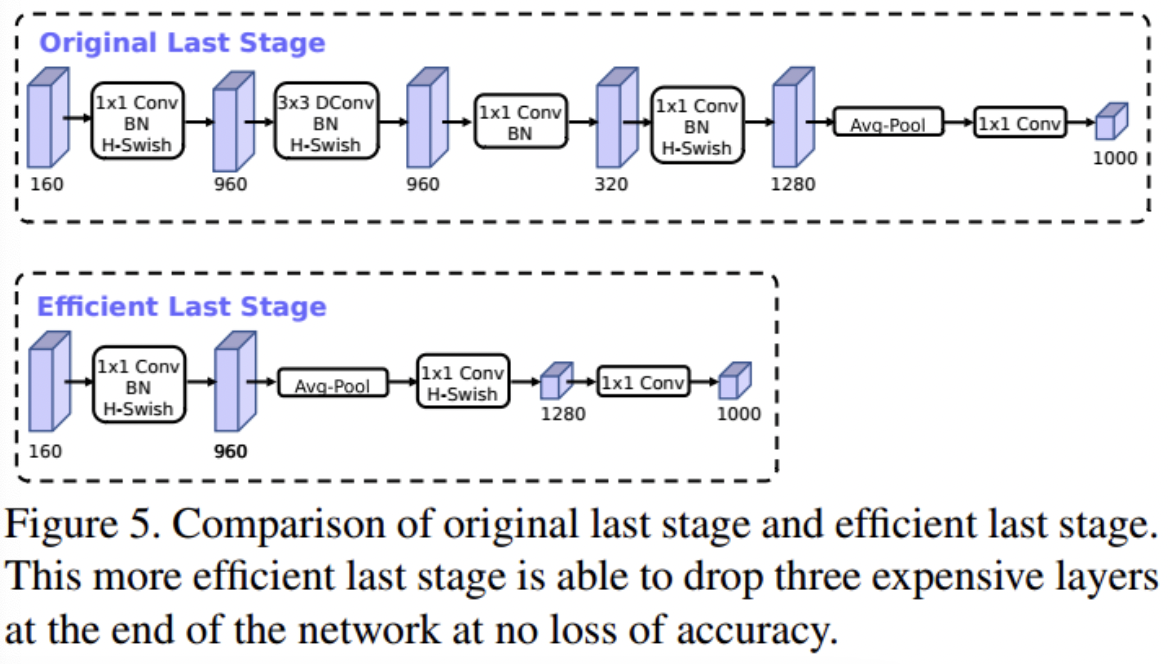
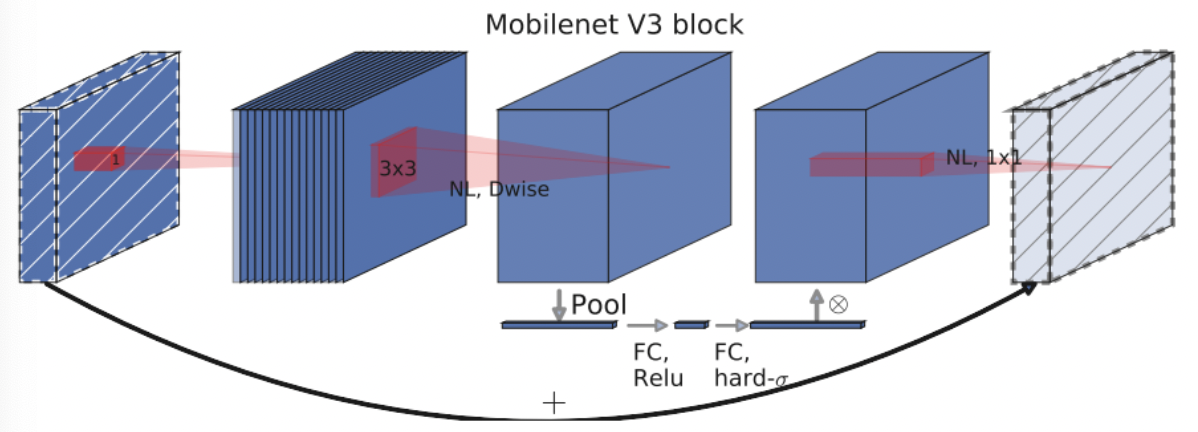
ShuffleNet
ShuffleNet系列论文包括两篇:ShuffleNetV1和ShuffleNetV2。个人认为ShuffleNet系列最大启发点包含两个部分:
- 提出了
Channel shuffle的概念,且该操作可以基于常规张量操作实现,一定程度上提供了一个更轻量化的channel内特征融合的方案(对比基于1x1卷积的channel融合方案)。 - 从实际硬件推理角度(应该是GPU?)探讨了高性能网络设计的基本规则,有一定借鉴意义。
ShuffleNetV1的核心在于 Channel shuffle 概念的提出,在可分离卷积的基础上设计了更加轻量化的网络结构:通过1x1组卷积+Channel shuffle替换原始点卷积实现channel间的特征融合: 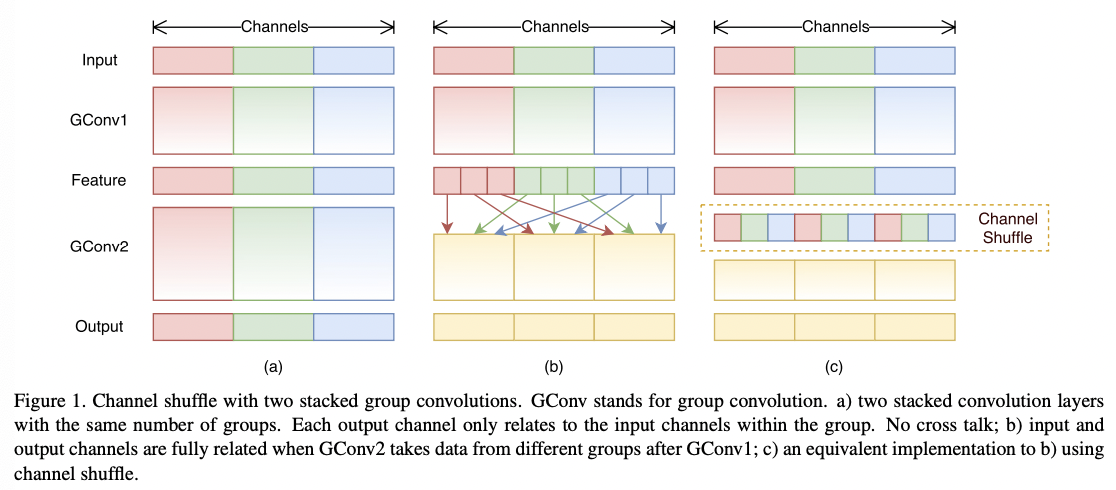
ShuffleNetV2其实一定程度上推翻了ShuffleNetV1的设计方案(个人观点),作者从模型推理角度发现同样的网络FLOP(单次推理计算次数)下,模型的推理速度也是不尽相同的,影响模型推理速度的还有两个关键指标:内存访问时间(Memory Access Cost, MAC)和网络并行度。基于此,作者提出了建立高性能网络的4个基本原则:
- 网络的输入和输出特征相同时,MAC最小,速度最快
- 过多的组卷积会增大MAC
- 网络的碎片化过大,如分支过多,会影响速度
- Element Wise操作的FLOPS很低,但是MAC较高,也会影响速度
基于此,作者发现ShuffleNetV1存在一些不合理的设计,并以此设计了新的ShuffleNetV2结构: 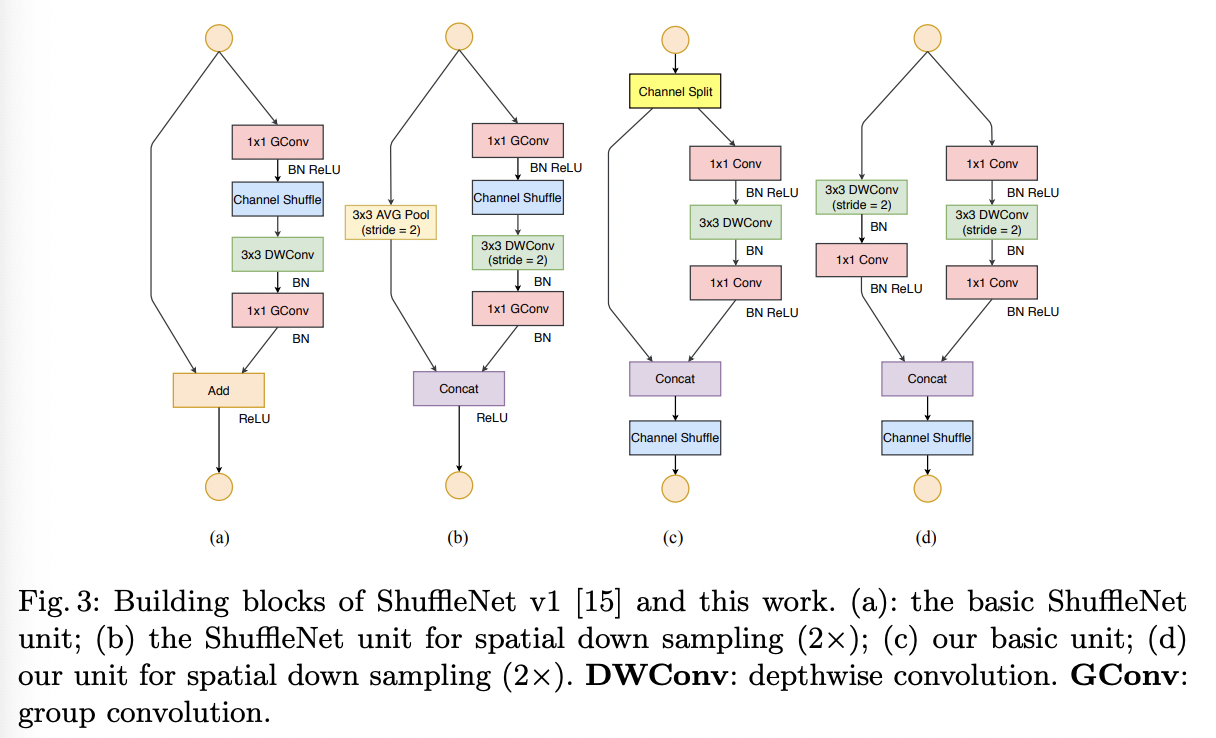
OneNet
前文更多介绍Backbone层面上的网络加速策略, OneNet则是在检测网络层面设计了Non-NMS的网络检测方案,从整体方案角度其优势在于:
- 全卷积网络
- 无NMS/self-attetion模块
OneNet的核心在于其训练过程的样本匹配策略,即如何让网络学习到 one-to-one 的匹配策略。
OneNet的样本匹配策略基于 minimum cost 方法实现,具体实现是在模型训练进行样本匹配过程中先计算样本的loss值,然后基于loss计算cost,最后选取cost最小的样本作为match的对象。其cost定义为样本和gt的classfication loss和location loss之和: 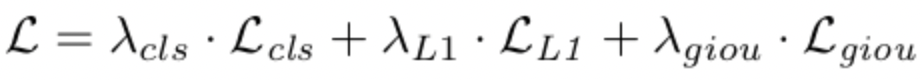
作者在论文中提到classification loss是去掉NMS的关键,而类似Faster-RCNN/SSD/YOLO/FCOS等基于box IoU,point distance,object scale等,都只考虑了location cost。
网络剪枝
网络剪枝其实可以认为是一种通用的网络加速策略,一般用在网络方案确定后的网络加速。微软开源的NNI工具提高了一些常用模型剪枝和量化策略。
网络剪枝的原理在于深度模型的过度参数化,也可以认为是其过拟合的一种表现。网络剪枝按照原理上可以分为两类:一类是结构化剪枝;一类是非结构化剪枝:
结构化剪枝通常是高层次的模型裁剪,常见的层次有:Channel-level,Vector-level,Filter-level。个人认为其一定程度上依赖于经验,前文中一些网络结构上的设计一定程度也可以归于结构化剪枝。另外,基于NAS(Neural Architecture Search)的模型结构搜索通常也可以应用模型剪枝结构的搜索。
非结构化剪枝则是从更细粒度上进行模型权重的裁剪:将原本稠密的参数矩阵裁剪为更为稀疏的参数矩阵。其一般流程为:
- 先正常训练得到一个大模型
- 确定需要剪枝的网络层,设计参数;基于设计参数对网络模型中权重较小的参数进行剪枝
- 基于裁剪后的网络进行finetune
通常来说,结构化剪枝能够带来明显的网络提速,但是可能会有精度损失(如果资源够的话,基于NAS的search方案通常更有效);而非结构剪枝不一定会带来精度损失,但是由于其稀疏矩阵的不连续性,在真实部署的时候不一定能提速。