前言
简单介绍下在2D-detection场景下常用的网络Backbone:
- VGG-Net
- Inception
- ResNet
- FPN
- DetNet
VGG-Net
VGG网络由Oxford的Visual Geometry Group提出,其价值在于探索了卷积网络深度和性能的关系,用更小的卷积核与更深的网络结获得了较好的效果,可以认为是卷积结构上一个比较重要的网络,对于一些要求网络灵活度高,速度快的场景依然有比较多的应用.
VGG-Net采用的卷积核基本都是3X3,相对于5X5卷积核,其拥有同等感受野的同时,参数量更少,且3X3卷积核组合的拟合能力比单个5X5卷积核更强.VGG的网络结构如下:
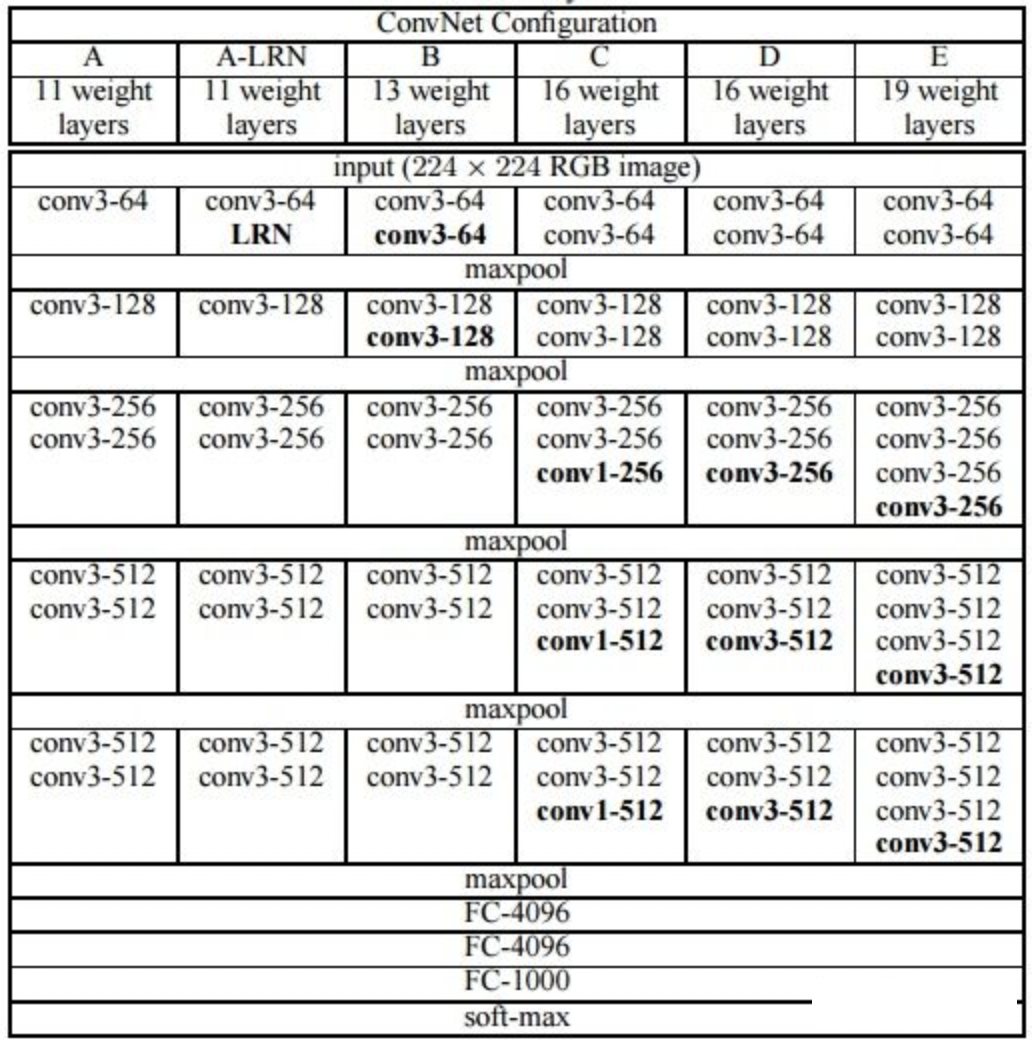
VGG网络结构的缺点在于其参数量很大(主要在于全连接层),且随着网络的继续加深,VGG like的网络结构会逐渐出现训练瓶颈.
Inception
Inception系列网络包含了Inception V1, Inception V2, Inception V3, Inception V4, Inception-ResNet-V2等
Inception V1
Inception V1和VGG同一年提出,相较于VGG网络加深网络,Inception V1采用的是加宽网络:卷积核的合并(Bottleneck Layer):
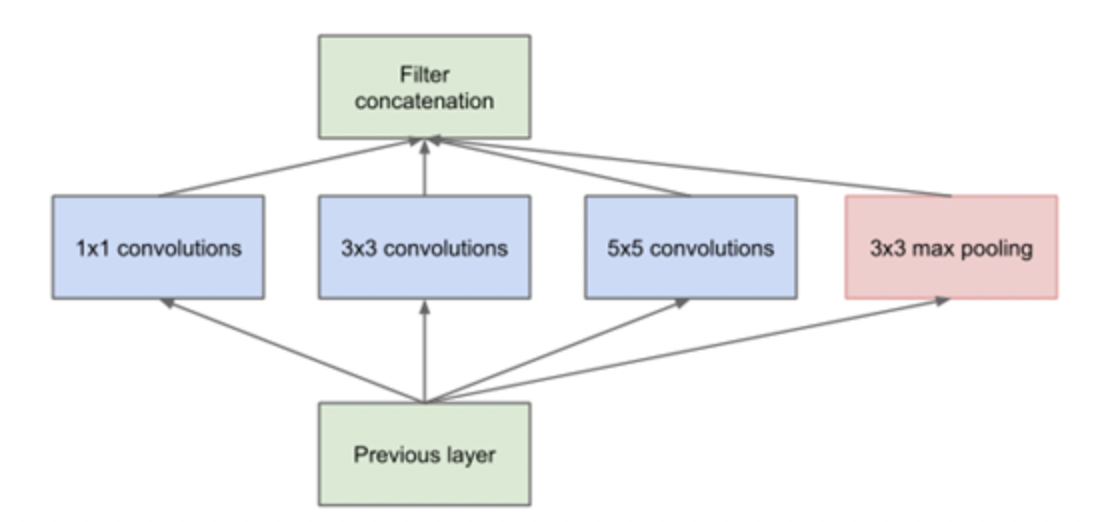
上述结构核心在于单个block内采用不同尺度的卷积核,对将不同稀疏程度上的特征进行合并,提高了网络对尺度/感受野上的适用性.但是上述结构仍然存在计算量大的问题,基于上述结构还可以进一步优化,可以通过1X1的卷积核进行降维操作,从而减少参数量,最终采用的block结构如下:
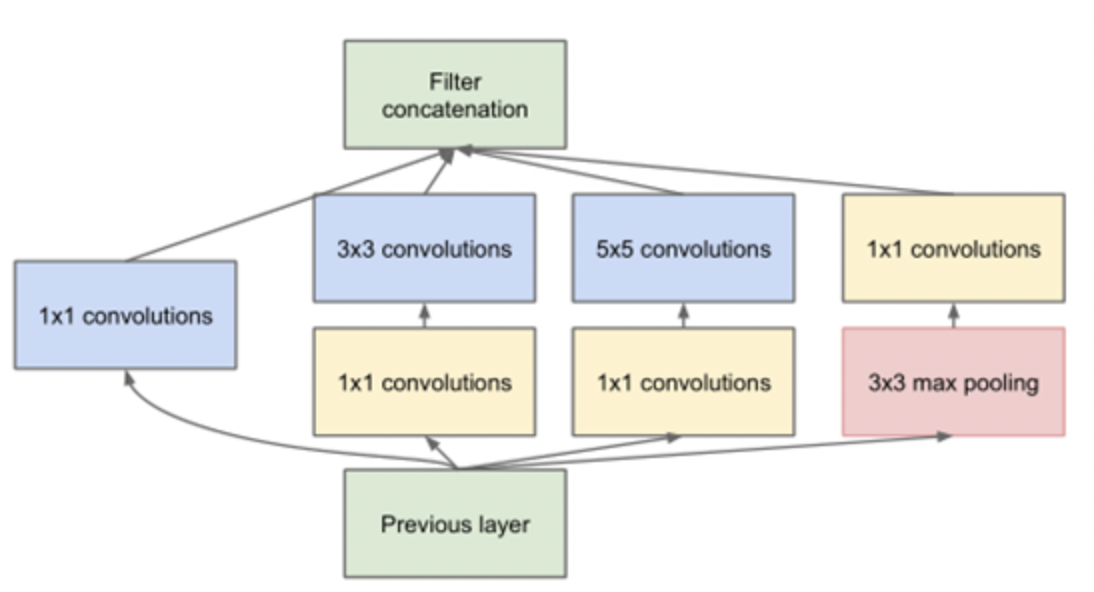
Inception V2 && V3
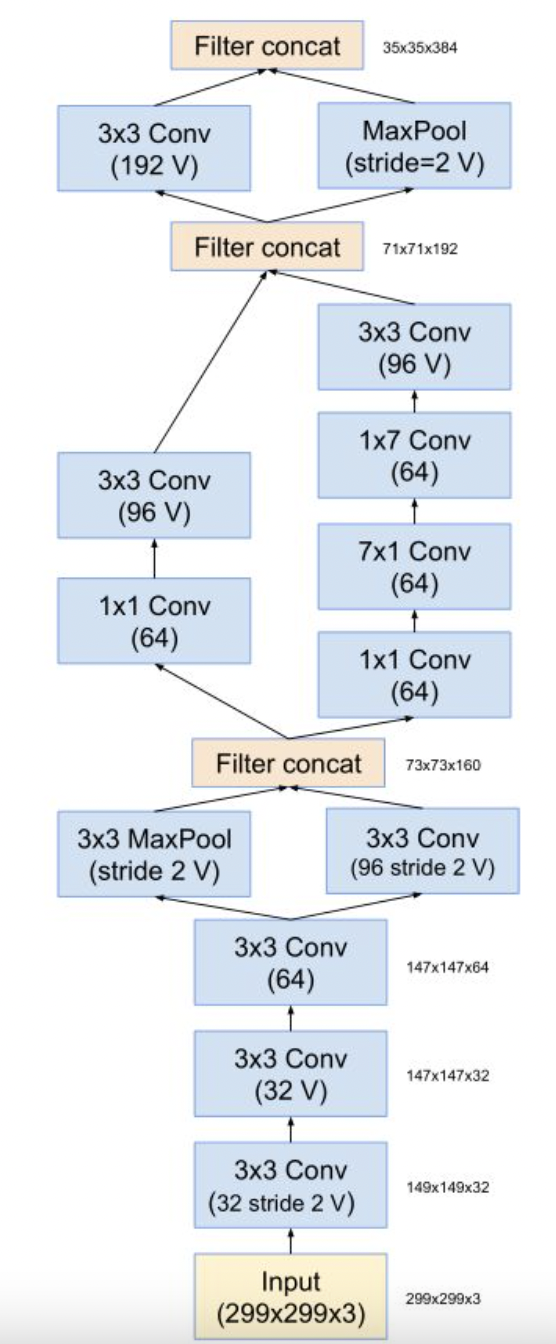
Inception V2对Inception V1结构的改进如下:
- 使用BN
- 2个3X3卷积替代5X5卷积
- 引入1*n和n*1非对称卷积替代n*n的对称卷积
最后采用的Inception V2的结构如下:
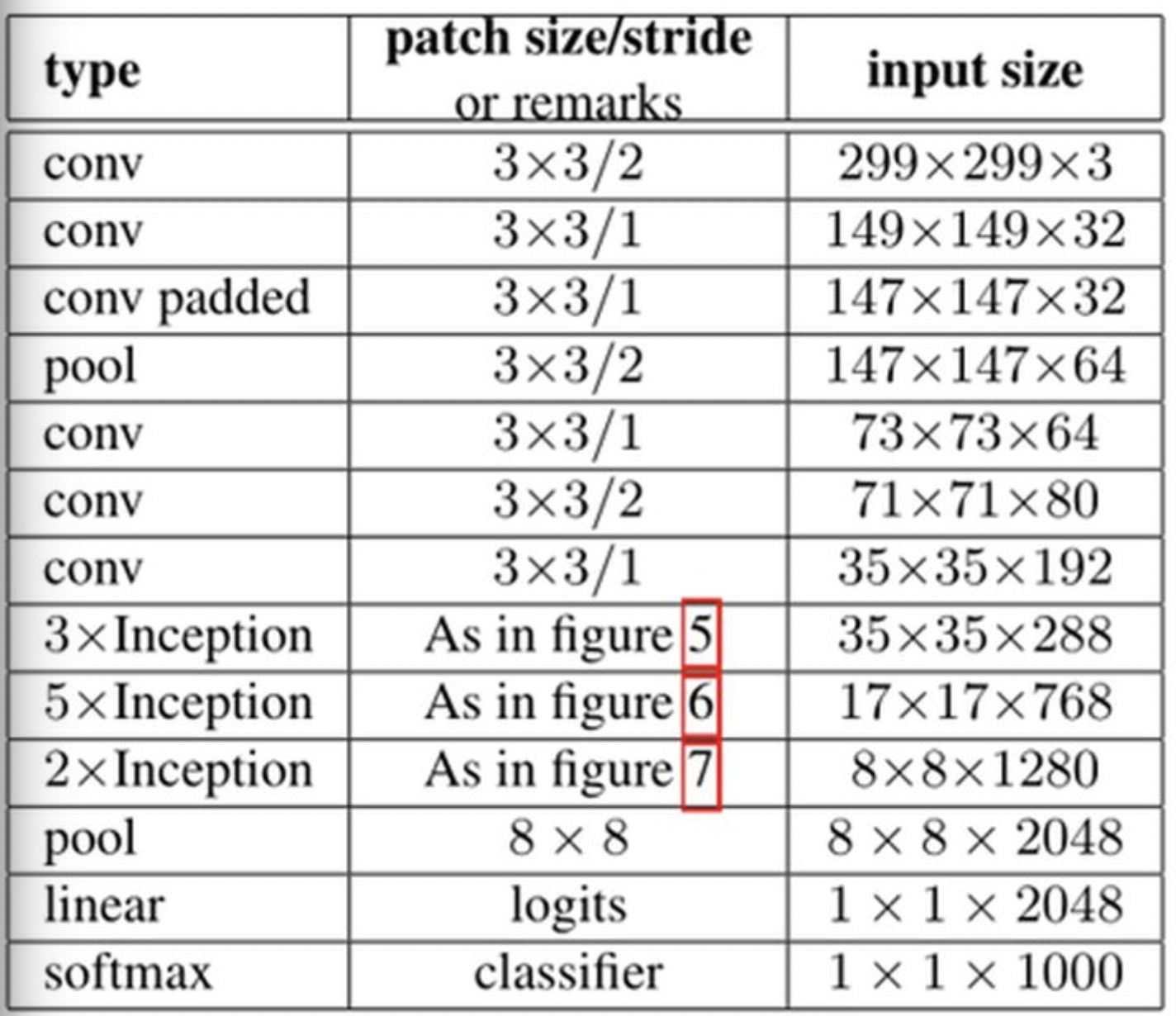
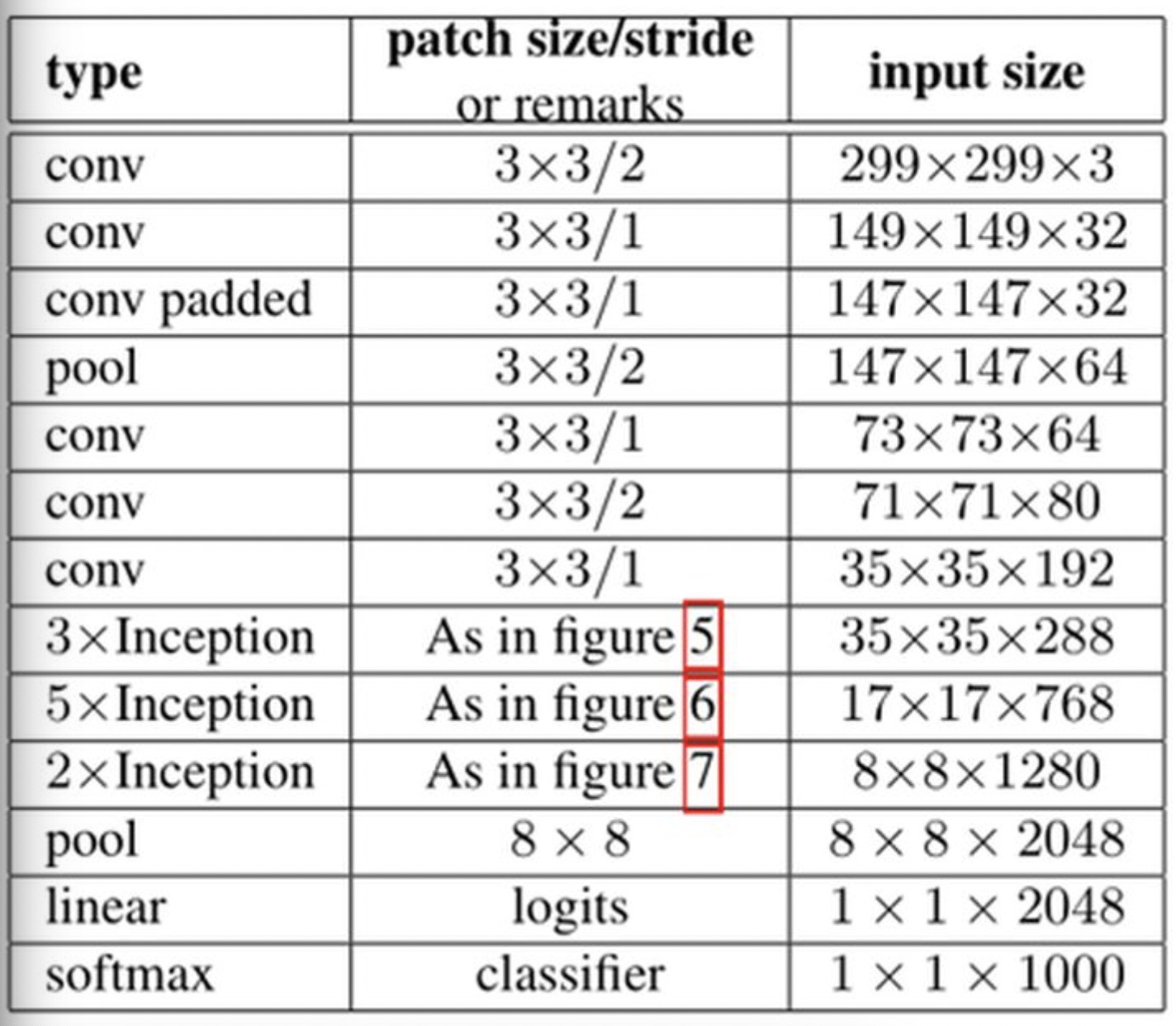
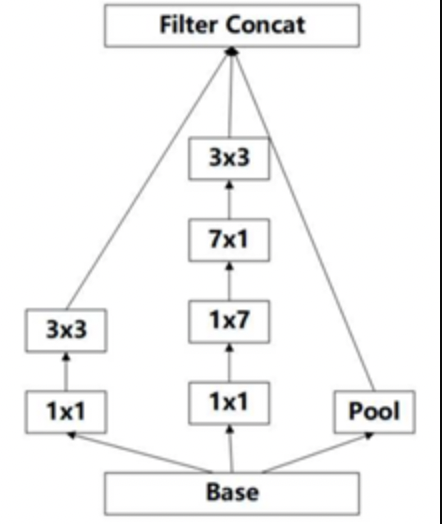
Inception V3网络相对于V2改动不大,主要改进在于采用了一种并行的降维结构:
另外Inception V3还采用了RMSProp优化器,且采用了标签平滑技术.
Inception V4
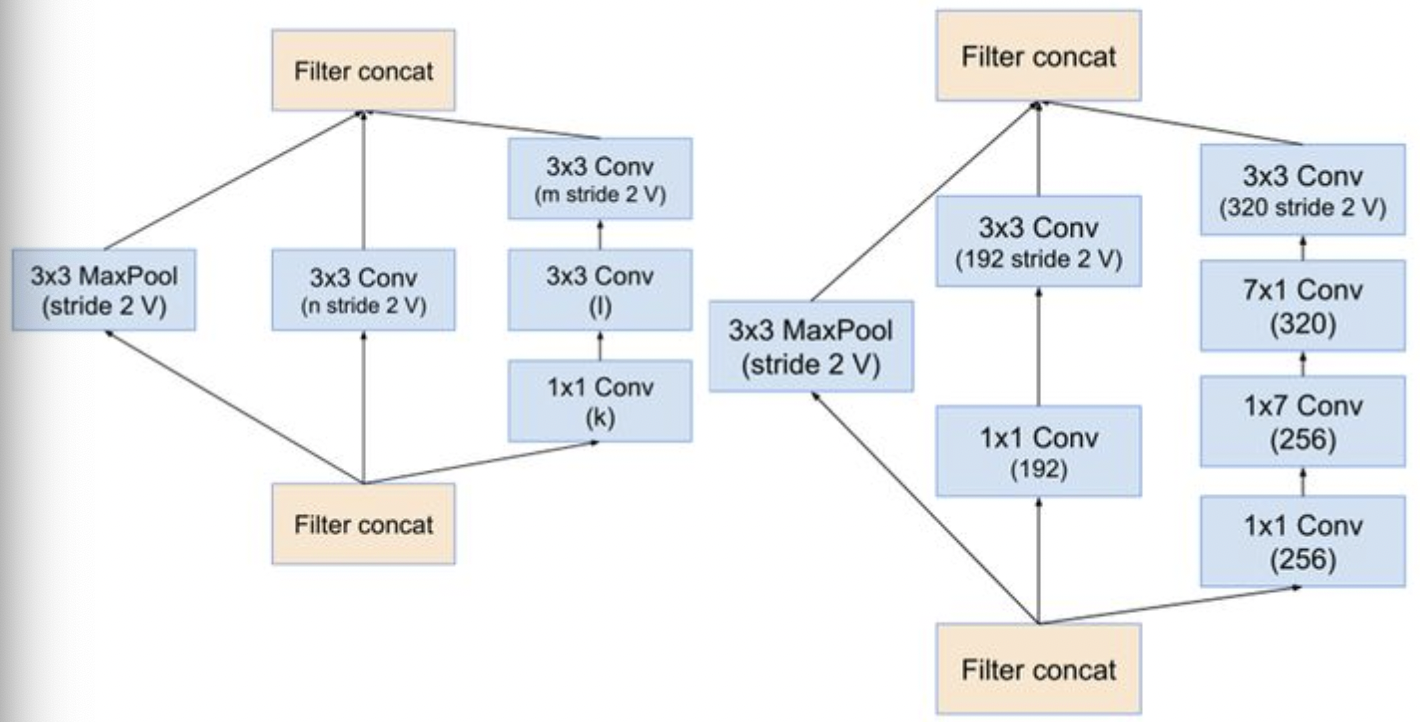
Inception V4的主要改进在于通过stem模块替换前置的卷积,池化的顺次连接,stem的模块结构如下:
stem结构之后便是inception 结构和reduction结构:
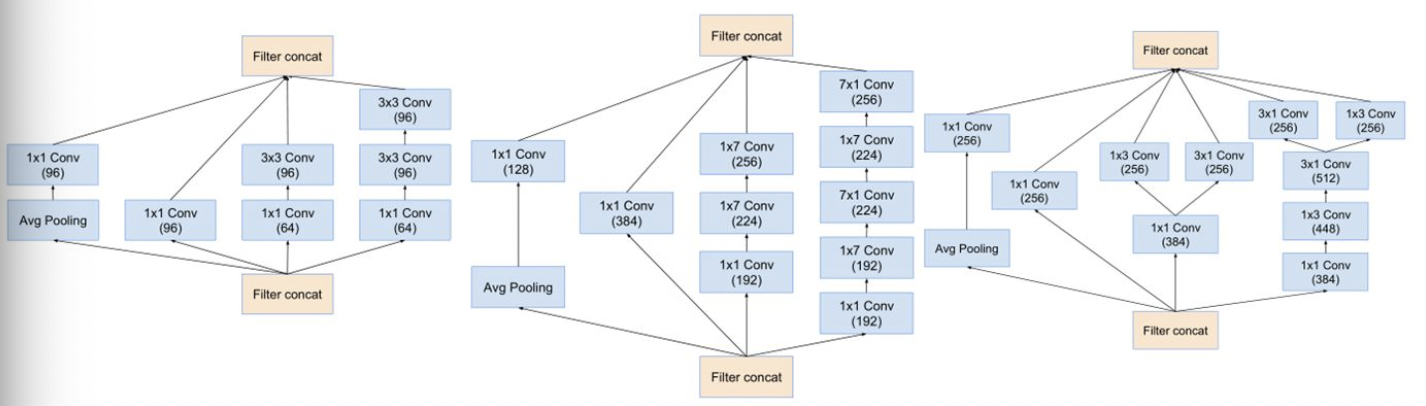
最后的Inception V4结构:
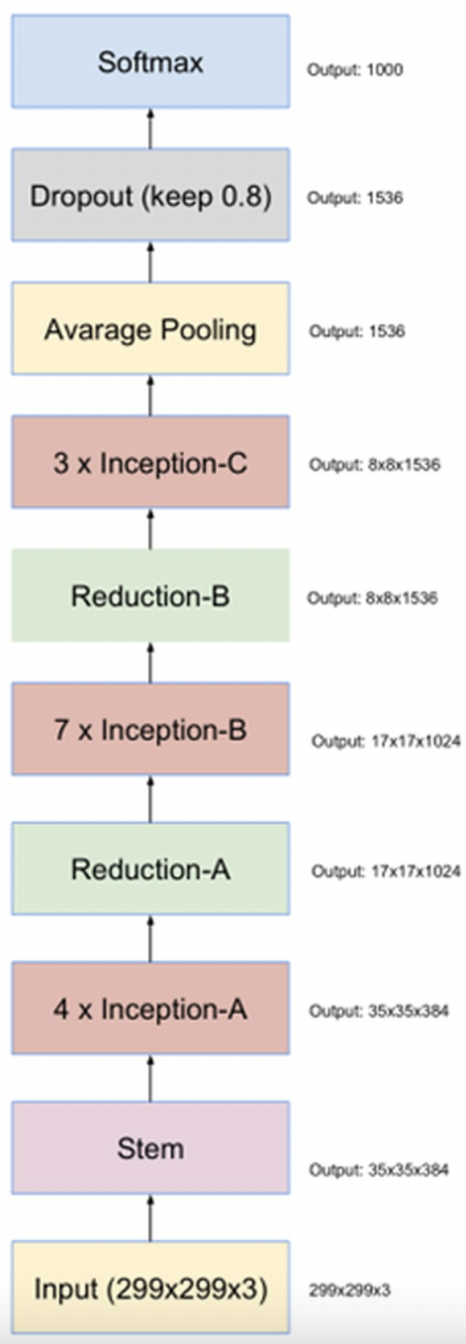
Inception ResNet V2
Inception-resnet有V1,V2两个版本,V2表现更好更复杂,所以仅谈V2.其关键设计在于引入了残差结构:
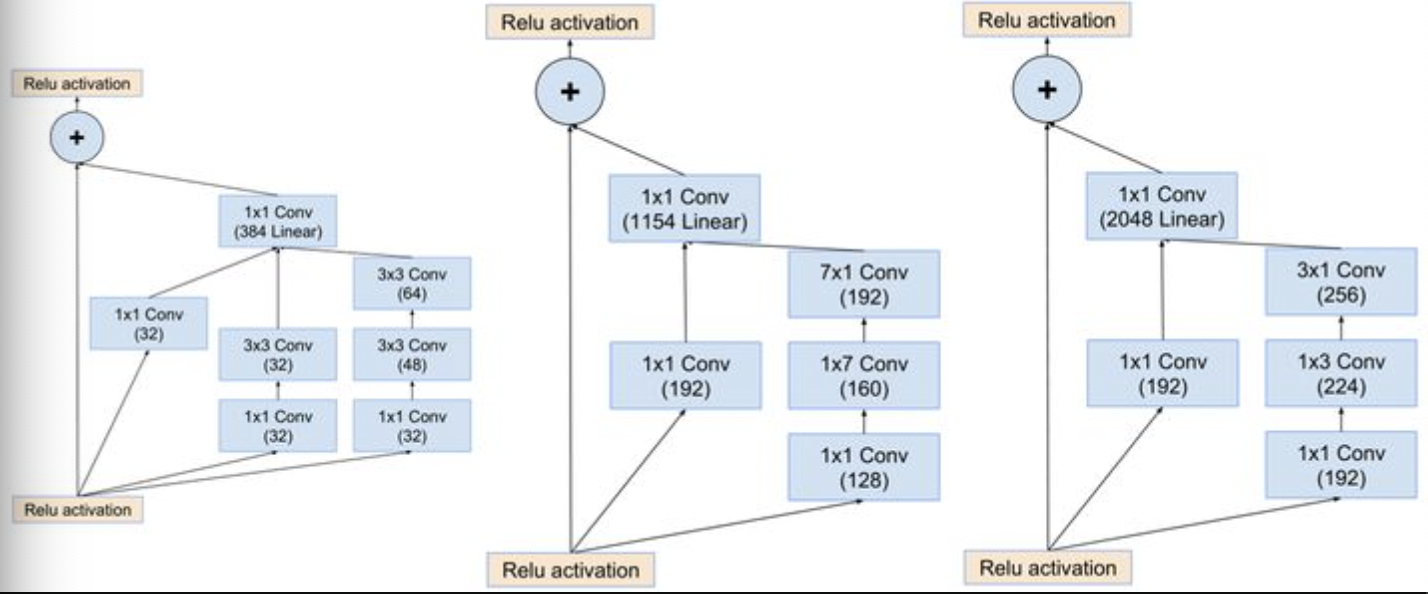
reduction-resnet模块与Inception V4模块相近:
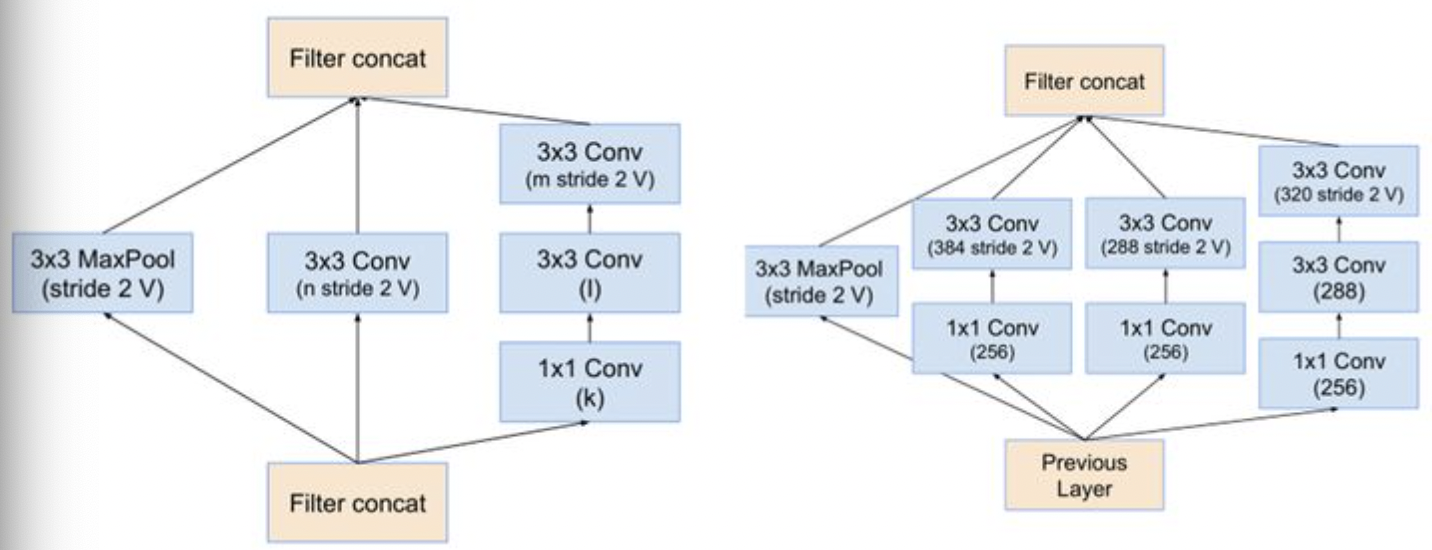
最终得到的Inceotion-renset V2模块如下:
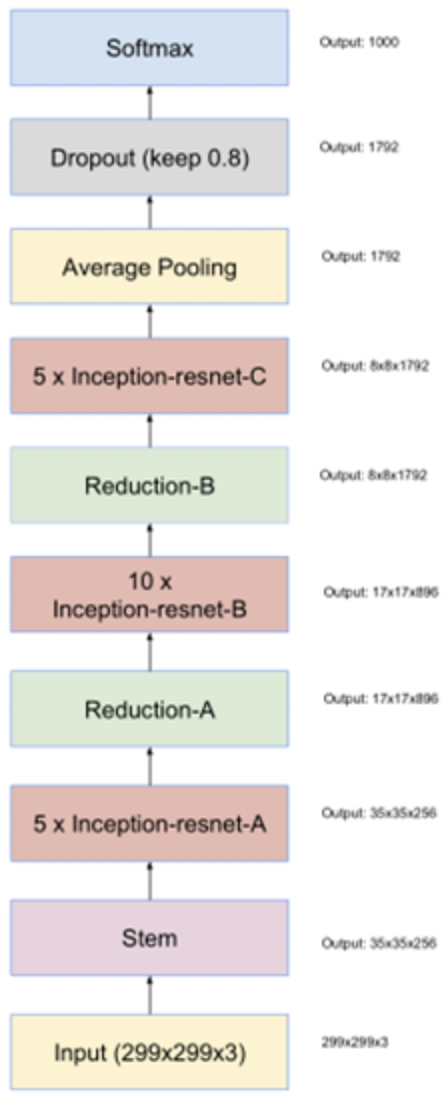
ResNet
上文VGG,Inception采用更深/更宽的网络,但是随着网络的加深/加宽,网络训练会越来越难,一方面会产生”梯度消失”,同时越深的网络返回的梯度相关性也越差.
Resnet的出现较好地解决了这个问题,其思想在于引入残差结构,具体结构如下(左侧为浅层模型残差结构,右侧为深层模型残差结构):
其核心分为三个部分:
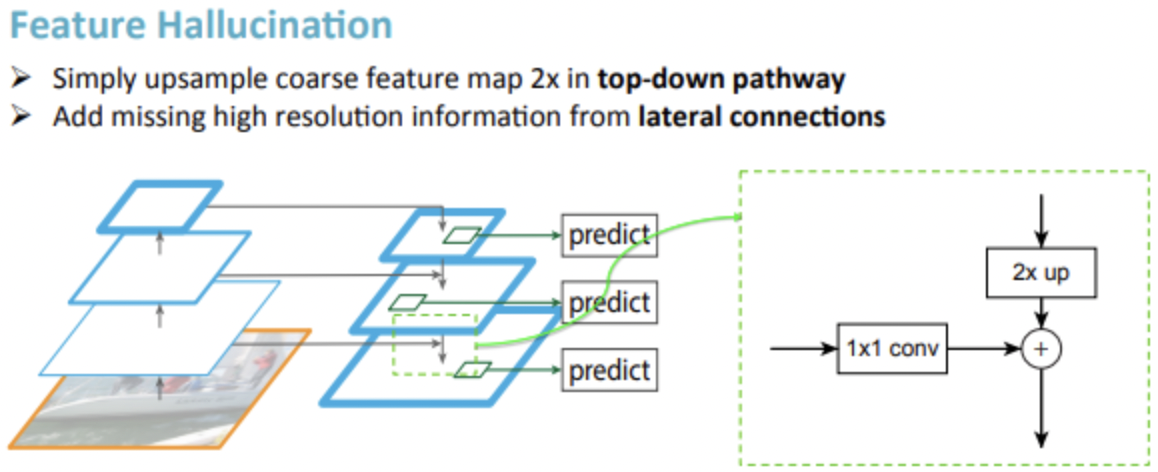
- 自底向上:网络前向infer过程,不包含上下层的特征融合
- 自顶而下和横向连接:进行上下层的特征融合,其中高层特征会进行2倍上采样,然后和浅层特征进行融合(需要先进行1X1的卷积核转换,目的是为了使通道数一致).融合方式为元素相加的方式,融合之后的特征图需要再通过3X3卷积来消除上采样的混叠效应(aliasing effect).
- 中间层:融合前需要先通过1X1卷积核进行链接,目的是为了减少特征图数量
DetNet
之前大部分的Backbone都是基于分类任务设计的,直接应用于检测任务的特征提取会存在一些问题:
- Pretrain问题,backbone的Pretrain通常都是基于分类任务数据集,如ImageNet等.但是实际应用于检测任务时,backbone通常会有其他设计,如:FPN,RetinaNet等添加了额外的步骤还进行不同尺度检测上的优化,但是这些额外的部分是没有经过pretrain的
- 大目标的弱可见性:检测网络中大物体通常在更后的stage,更小的feature map上检测,因为更后的feature map通常有更大的感受野.但是,更深的feature map由于stride过大,物体的边缘会过于模糊,检测中精准的回归难度也会越大.
- 小目标的不可见性:随着网络的层数的变大,空间分辨率的降低,小物体的信息会被不断弱化.FPN一定程度上提升了小物体上的性能,但是浅层的信息还是不够丰富,性能存在一定瓶颈.
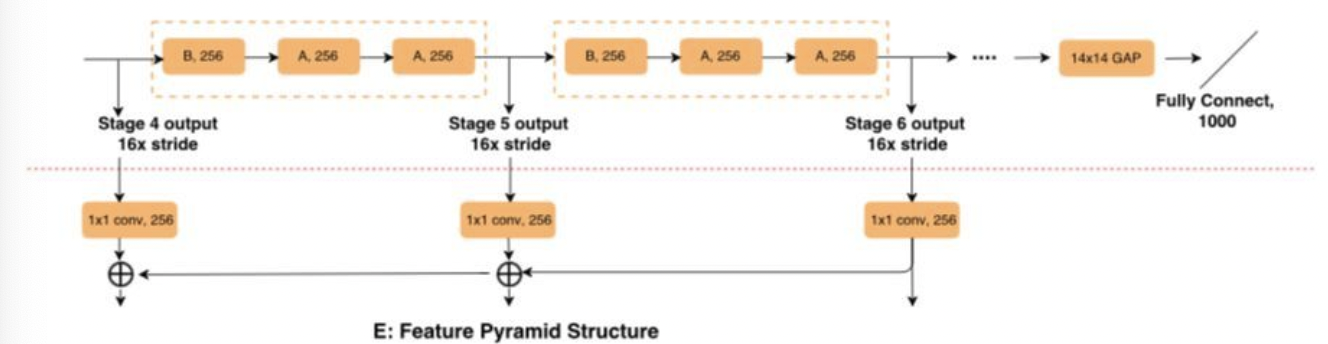
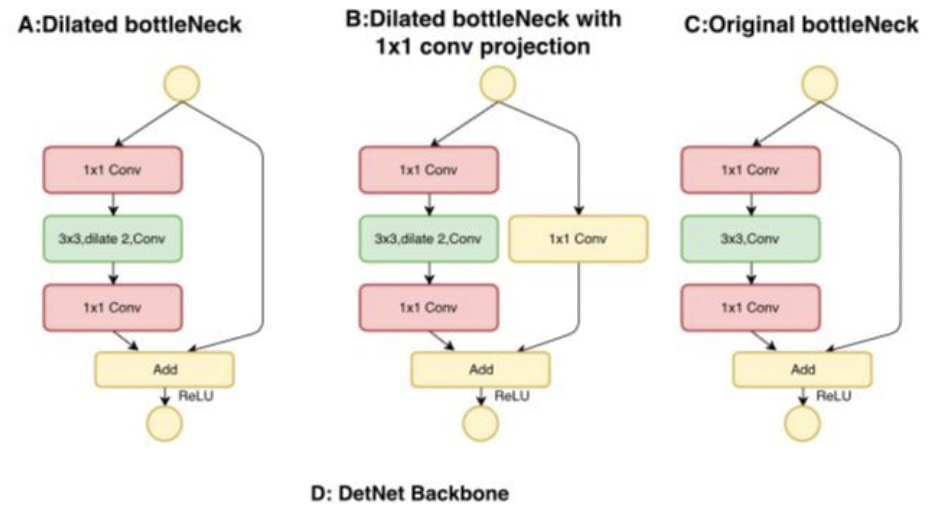
DetNet基于上述问题,进行了一系列的改进(基于ResNet50),主要包括以下几个方面:
- 原始stage5采用特殊设计的bottleneck结构,且输入尺寸保持和stage4一致,但是采用空洞数为2的3X3卷积来替代步长为2的卷积,使其在保持feature map大小一致的情况下仍然有比较大的感受野
- 引入了stage6,提取更高维度的特征用于物体检测
- 保持FPN结构,且由于stage4-stage6的feature map大小一致,避免了上采样的信息损失和计算量,同时也有利于小物体检测
其中,采用了空洞卷积后的bottleneck结构如下:
DetNet的整体结构如下: