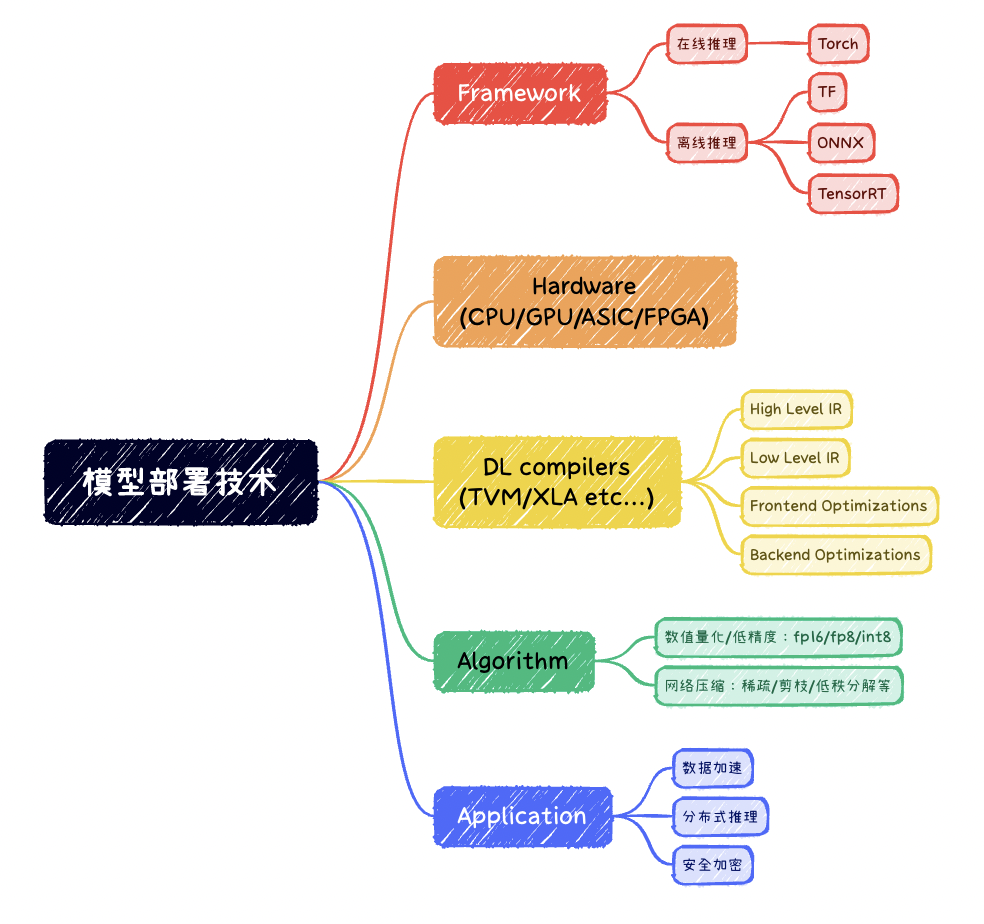
开坑模型离线部署技术相关内容更新 简单梳理技术栈如下(需要持续更新):
PyTorch关键模块解读
ONNX的模型优化与量化细节
AI模型部署硬件综述
Transformer离线部署-GPU优化策略
前言 简单介绍各类AttentionScore优化算法。 FlashAttentionV1 FlashAttention于2022年6月由斯坦福大学、纽约州立大学研究者完成。 FlashAttention的核心思路是:通过重组Attention计算,能够对输入块进行分块,逐步执行softmax的reduction,避免了整个输入块的计算,从而减少了更少的内存访问(HBM),同时中间结果...
前言 参数量 计算量 显存占用 参考资料 前言 本文主要介绍Transformer类大模型训练/推理过程中的计算量/显存占用情况,因为对于大模型推理/训练而言,计算量决定了模型的训练/推理速度,显存占用情况决定了可供训练/推理的数据量(更大的显存能够并行跑更多的数据或者更长的序列)。 对于LLMs(Large Language Models)而言,模型结构整体趋同...
前言 影响LLM推理性能的因素有很多,包括但是不限于:模型配置、硬件类型、数据分布、优化算法、推理策略等。本位旨在综述各类技术点,后续会针对核心技术做详细展开。 算法 LLM 参数建模 大模型计算建模 LLMs位置编码 Transformer FlashAttention系列优化 MoEs算法&&部署概述 量化 LLMs量化算法概述 框架 开源的...
算子编程模型