ONNX的模型优化与量化细节
ONNX基本介绍
什么是ONNX?
ONNX全称为 Open Neural Network Exchange,是一种与框架无关的模型表达式。ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。
ONNX的数据格式是怎么样的?
ONNX本质上一种文件格式,通过Protobuf数据结构存储了神经网络结构权重。其组织格式核心定义在于onnx.proto,其中定义了Model/Graph/Node/ValueInfo/Tensor/Attribute层面的数据结构。整图通过各节点(Node)的input/output指向关系构建模型图的拓扑结构。
ONNX支持的功能?
基于ONNX模型,官方提供了一系列相关工具:模型转化/模型优化(simplifier等)/模型部署(Runtime)/模型可视化(Netron等)等。
ONNX自带了Runtime库,能够将ONNX Model部署到不同的硬件设备上进行推理,支持各种后端(如TensorRT/OpenVINO)。
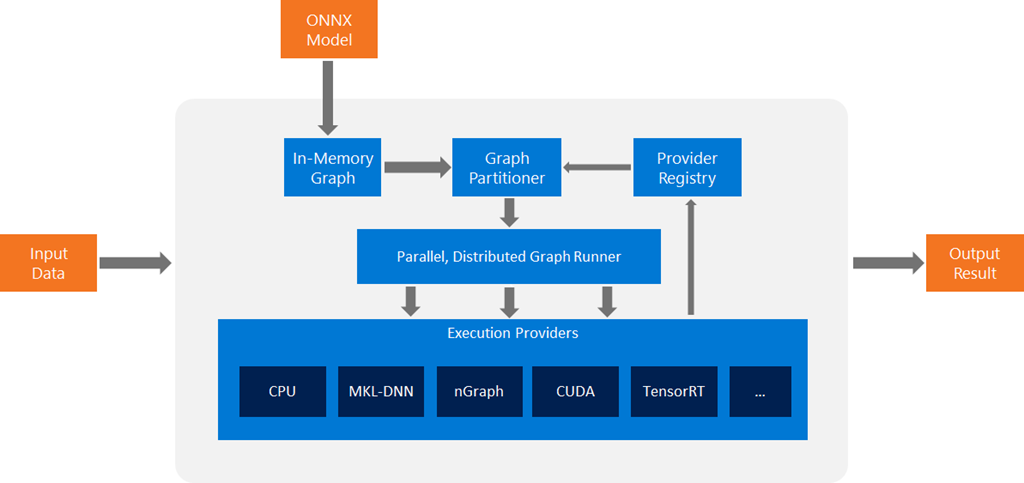
基于ONNX Model的Runtime系统架构如下,可以看到Runtime实现功能是将ONNX Model转换为In-Memory Graph格式,之后通过将其转化为各个可执行的子图,最后通过GetCapability() API将子图分配到不同的后端(execution provider)执行。
ONNX模型优化
onnx_simplifier的核心功能如下:
ONNX Simplifier is presented to simplify the ONNX model. It infers the whole computation graph and then replaces the redundant operators with their constant outputs.
simplify的基本流程如下:
- 利用onnxruntime推理计算图,得到各个节点的输入输出的infer shape
- 基于ONNX支持的优化方法进行ONNX模型的优化(如
fuse_bn_into_conv) - 对ONNX模型的常量OP进行折叠:
- 基于
get_constant_nodes获取常量OP - 基于
add_features_to_output将所有静态节点的输出扩展到ONNX图的输出节点列表中(主要为了后续步骤方便获取常量节点输出) - 将1.中得到的常量OP从图中移除(断开连线),同时将其节点参数构建为其他节点的输入参数
- 清理图中的孤立节点(3.中断开连线的节点)
- 基于
其optimize函数定义如下(可以简单看下目前支持的一些优化方法):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def optimize(model: onnx.ModelProto, skip_fuse_bn: bool, skipped_optimizers: Optional[Sequence[str]]) -> onnx.ModelProto:
"""
:model参数: 待优化的ONXX模型.
:return: 优化之后的ONNX模型.
简化之前, 使用这个方法产生会在'forward_all'用到的ValueInfo
简化之后,使用这个方法去折叠前一步产生的常量到initializer中并且消除没被使用的常量
"""
onnx.checker.check_model(model)
onnx.helper.strip_doc_string(model)
optimizers_list = [
'eliminate_deadend',
'eliminate_nop_dropout',
'eliminate_nop_cast',
'eliminate_nop_monotone_argmax', 'eliminate_nop_pad',
'extract_constant_to_initializer', 'eliminate_unused_initializer',
'eliminate_nop_transpose',
'eliminate_nop_flatten', 'eliminate_identity',
'fuse_add_bias_into_conv',
'fuse_consecutive_concats',
'fuse_consecutive_log_softmax',
'fuse_consecutive_reduce_unsqueeze', 'fuse_consecutive_squeezes',
'fuse_consecutive_transposes', 'fuse_matmul_add_bias_into_gemm',
'fuse_pad_into_conv', 'fuse_transpose_into_gemm', 'eliminate_duplicate_initializer'
]
if not skip_fuse_bn:
optimizers_list.append('fuse_bn_into_conv')
if skipped_optimizers is not None:
for opt in skipped_optimizers:
try:
optimizers_list.remove(opt)
except ValueError:
pass
model = onnxoptimizer.optimize(model, optimizers_list, fixed_point=True)
onnx.checker.check_model(model)
return model
ONNX转FP16
ONNX支持FP32模型转换为FP16模型,接口如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
import onnxmltools
from onnxmltools.utils.float16_converter import convert_float_to_float16
# Update the input name and path for your ONNX model
input_onnx_model = 'model.onnx'
# Change this path to the output name and path for your float16 ONNX model
output_onnx_model = 'model_f16.onnx'
# Load your model
onnx_model = onnxmltools.utils.load_model(input_onnx_model)
# Convert tensor float type from your input ONNX model to tensor float16
onnx_model = convert_float_to_float16(onnx_model)
# Save as protobuf
onnxmltools.utils.save_model(onnx_model, output_onnx_model)
具体实现在于float16.py,截断的逻辑:
- 小于最小精度(默认1e-7)映射为最小精度
- 大于最大范围(默认1e4)映射为最大值
- NaN/0/inf/-inf保持原值
核心代码:
1
2
3
4
5
6
7
8
def convert_np_to_float16(np_array, min_positive_val=1e-7, max_finite_val=1e4):
def between(a, b, c):
return np.logical_and(a < b, b < c)
np_array = np.where(between(0, np_array, min_positive_val), min_positive_val, np_array)
np_array = np.where(between(-min_positive_val, np_array, 0), -min_positive_val, np_array)
np_array = np.where(between(max_finite_val, np_array, float('inf')), max_finite_val, np_array)
np_array = np.where(between(float('-inf'), np_array, -max_finite_val), -max_finite_val, np_array)
return np.float16(np_array)