目录
- 前言
- torch.autograd: 梯度计算
- BN & SyncBN: BN与多卡同步BN
- torch.utils.data: 解析数据处理全流程
- nn.Module: 核心网络模块接口
- DP & DDP: 模型并行和分布式训练
- torch.optim: 优化算法接口
- torch.cuda.amp: 自动混合精度
- cpp_extension: C++/CUDA算子实现和调用全流程
前言
主要参考:MMLab知乎源码解读 
torch.autograd: 梯度计算
梯度计算主要涉及以下几个模块:
torch.autograd.function(函数的反向传播)Pytorch中的模块nn.Module通常是包裹了autograd function,以其作为真正实现的部分,如nn.ReLU实际使用的是:torch.nn.functional.relu(F.relu)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from torch.nn import functional as F class ReLU(Module): __constants__ = ['inplace'] inplace: bool def __init__(self, inplace: bool = False): super(ReLU, self).__init__() self.inplace = inplace def forward(self, input: Tensor) -> Tensor: # F.relu实际包裹的函数类型为builtin_function_or_method # 其内部定义了forward,backward函数,描述了梯度前向/反向传播的过程 # 通常使用C++实现(如ATen) return F.relu(input, inplace=self.inplace)
基于
torch.autograd.function中定义的Function类作为基类可以实现自定义的autograd function函数:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Exp(Function): # 此层计算e^x @staticmethod def forward(ctx, i): # 模型前向 result = i.exp() ctx.save_for_backward(result) # 保存所需内容,以备backward时使用,所需的结果会被保存在saved_tensors元组中;此处仅能保存tensor类型变量,若其余类型变量(Int等),可直接赋予ctx作为成员变量,也可以达到保存效果 @staticmethod def backward(ctx, grad_output): # 模型梯度反传 result, = ctx.save_tensors # 取出forward中保存的result return grad_output * result # 使用样例 x = torch.tensor([1.], requires_grad=True) # 注意设置tensor的requires_grad为True ret = Exp.apply(x) # 使用apply方法调用自定义autograd function print(ret) # (tensor[2.7183], grad_fn=<ExpBackward>) ret.backward() # 反传梯度 print(x.grad) # tensor([2.7183])
torch.autograd.functional(计算图的反向传播) Tensor类的backward方法实际调用的是torch.autograd.backward接口。pytorch实现中,autograd会记录生成前variable的所有操作,并建立一个有向无环图(DAG)。反向传播的过程中,autograd会沿着图从当前变量(根结点F)溯源,可以通过链式求导法则计算所有叶子节点的梯度。以下简单实现在计算图上进行autograd:1 2 3 4 5 6 7 8
# 样例仅适用于每个op只产生一个输出的情况,且效率很低 def autograd(grad_fn, gradient): auto_grad = {} queue = [[grad_fn, gradient]] while queue != []: item = queue.pop() gradients = item[0](item[1]) functions = [[x[0] for x in item[0].next_functions]]
torch.autograd.gradcheck(数值梯度检查)torch.autograd.anomaly_mode(在自动求导时检测错误产生路径)torch.autograd.grad_mode(设置是否需要梯度)model.eval和torch.no_grad()torch.autograd.profiler(提供function级别的统计信息)
BN & SyncBN: BN与多卡同步BN
简单谈下BN的优势:
- 防止过拟合:结合mini-batch训练,能够避免对单个样本的过拟合
- 加快收敛:原始是BN的归一化效果
- 防止梯度弥散/爆炸:归一化是输入分布位于激活函数的非饱和区(饱和区的激活函数输出值很小,容易造成梯度弥散/爆炸)
BN的公式: 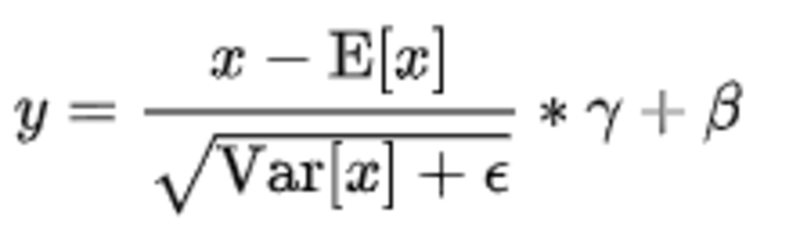
BN实现细节:
- BN默认打开
track_running_stats,因此每次forward时都会依据当前minibatch的统计量来更新running_mean和running_var。更新的方式通过momentum参数进行更新(默认0.1):
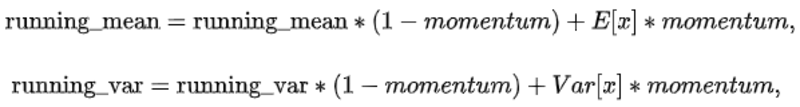
Pytorch 0.4.1后,加入num_batches_tracked属性,目的是统计BN一共forward了多少minibatch。当momemtum被设置为None时,就由num_batches_tracked来控制历史统计量和当前minibatch的影响占比: 
BN的性能和batch size有很大的关系。batch size越大,BN的统计量也会越准。但是对于输入数据量较大的情况,单张显卡的batch size通常较小。解决该问题的一个方案是:SyncBN,即所有卡共享一个BN,得到全局的统计量。 Pytorch的SynBN实现分别在torch/nn/modules/batchnorm.py 和torch/nn/modules/_functions.py 。其中,前者主要负责检查输入的合法性,以及根据momentum等设置进行传参,调用后者。而后者则负责计算单卡统计量以及进程间通信。 具体实现中,单卡上的BN会计算单卡对应输入的均值,方差,然后做Normalize;SyncBN则会得到全局的统计量,其实现的过程为:
- 单卡分别按照各自输入进行sum/square sum
- 进行所有卡的synchronize,得到global mean & std进行同步
- 单卡按照global mean & std进行各自的normalize
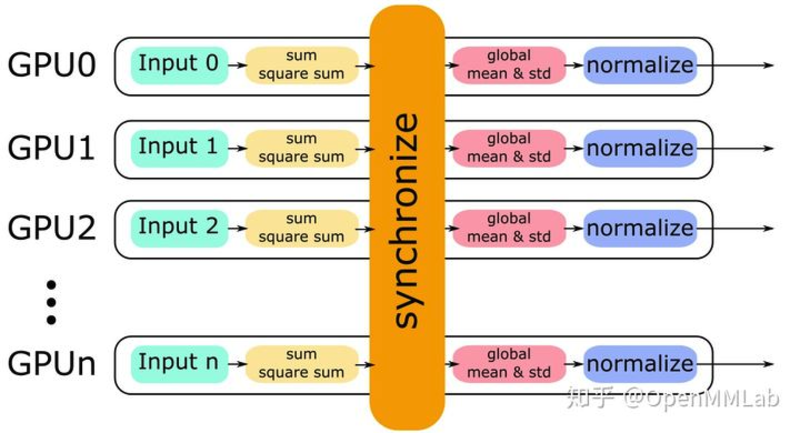
backward,计算weight ,bias 的梯度以及dy , dy/du 计算x的梯度,基本步骤
- all reduce计算梯度之和
- 根据总的size,对梯度计算平均
- backward进行梯度计算
torch.utils.data: 解析数据处理全流程
torch的data模块核心是迭代器。其关键组件包括:
- Dataset:负责对raw data source进行封装,通常包含两种:Map-style datasets和iterable datasets两种,前者通过
__getitem__实现数据获取,后者通过__iter__实现数据获取。Map-style datasets的应用较多,iterable datasets适用的情况是:随机读取的代价很大甚至不可能,且batch size取决于获取的数据。此外还包括:ConcatDatasets/ChainDataset/SubSet/TensorDataset等其他Dataset - Sampler:负责提供一种遍历数据集所有元素索引的方式。可支持用于自定义或者PyTorch提供。
- DataLoader:PyTorch数据加载的核心,复杂加载数据,同时支持Map-style和Iterable-style Dataset,支持单进程/多进程,还可以设置loading order,batch size,pin memory等参数。
- 三者关系:Dataloader负责总的调度,命令Sampler定义遍历索引的方式,然后通过索引去Dataset中提取元素。
几个核心点:
- 批处理(默认True):通过collate_fn实现,主要是将输入样本整理为一个batch,一般做下面三件事情:
- 添加新的批次维度
- 将Numpy数组和Python数值转化为PyTorch张量
- 保留原始数据结构。
- 多进程(multi-process):
- 单进程:num_workers为0,可以显示更多可读的错误跟踪,对于调试很有用。
- 多进程:num_workers控制,dataset,collate_fn,worker_init_fn都会传到每个worker中,每个worker都会用独立的进程。对于map-style数据,shuffle会在主线程完成,然后将用Sampler产生的index传到每个worker中。对于iterable-style数据,因为每个worker都有相同的data复制样本,并在每个进程中进行不同操作,所以需要通过get_worker_info()来进行辅助处理防止每个进程输出的数据重复。另外,由于多进程使用CUDA和共享CUDA张量的时候可能发生问题,建议采用pin_memory=True,以使数据能够快速传输到支持CUDA的GPU,不建议在使用多线程的情况下返回CUDA的tensor。
- Memory Pinning:
- 锁页内存:锁页内存存放的内容在任何情况都不会和虚拟内存进行交换(虚拟内存指硬盘)。非锁页内存则会在内存不足的时候,将数据存放在虚拟内存中。
pin_memory=True时,内存中的Tensor转义到GPU的显存就会更快些。
- 锁页内存:锁页内存存放的内容在任何情况都不会和虚拟内存进行交换(虚拟内存指硬盘)。非锁页内存则会在内存不足的时候,将数据存放在虚拟内存中。
- Prefetch:
- Dataloader通过指定
prefetch_factor(默认为2)来进行数据的预取。其适用于多进程加载。
- Dataloader通过指定
nn.Module: 核心网络模块接口
前置介绍Pytorch中的几个关键名词概念:parameter/buffer,引用自:知乎Pytorch解读。parameter指反向传播需要被optimizer更新的;buffer指反向传播不需要被optimizer更新。 torch的各个组件关系概览: 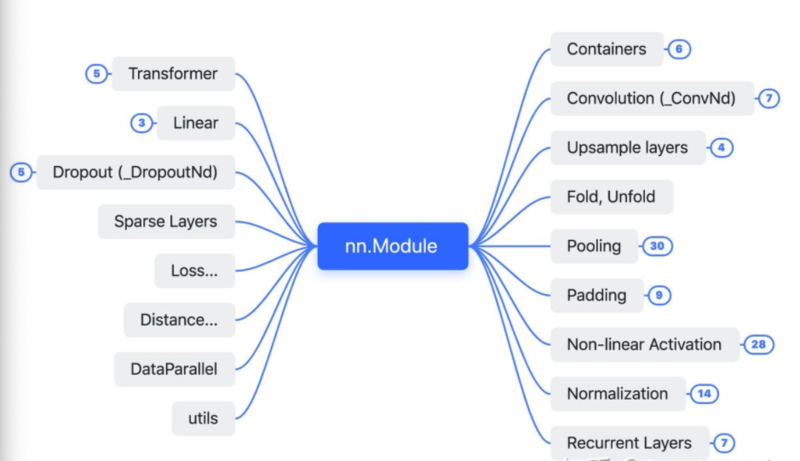 torch模块的组织和实现的几个常见特点:
torch模块的组织和实现的几个常见特点:
- 基类定义接口,通过继承来处理不同维度的输入
- 每个类都有对应的
nn.functional函数,forward函数中将arguments/parameters传给nn.functional的对应函数来实现forward功能。 - 继承
nn.Module的模块主要重载init/forward/extra_repr函数,含有parameters的模块还会实现reset_parameters函数来初始化参数。
nn.Module 实现:
- 常用接口:
__init__:初始化一系列重要的成员变量- 状态转化:通过
self.training来区分训练/测试两种状态 - 参数转化/转移:包括CPU/GPU的转移以及不同类型的转化,主要通过
self._apply(function)来实现的。self._apply包括三个步骤:self.children()来实现递归调用对self._parameters中的参数及其gradient通过function进行处理对self._buffers中的buffer逐个通过function进行处理。
- 属性的增删改查:
- 属性修改包含三个函数:
add_module(增加子神经网络模块)/register_parameter(增加通过BP更新的parameter)/register_buffer(增加不通过BP更新的buffer)。常用的方式为:self.xxx = xxx来进行属性的增加/修改,本质上是调用nn.Module重载的函数__setattr__;但是需要注意的是:self.xxx = torch.Tensor()是一种不被推荐的行为,因为该行为新增的attribute不属于self._parameters/self._buffers,而是被认为是普通的attribue,在进行状态转化时,self.xxx会被遗漏而导致device或者type不一样的bug。 - 属性删除:
__delattr__实现,会挨个检查self._parameters,self._buffers,self._modules和普通的attribute并将name从中删除。
- 属性修改包含三个函数:
- Forward & Backward
- Hooks:nn.Module类实现了3个通用的hook注册函数,用于注册被应用于全局的hook。该三个函数分别注册进3个全局的OrderedDict:_
global_backward_hooks/_global_forward_pre_hooks/_global_forward_hooks。同时,nn.Module也支持注册应用于自身的forward/backward hook:self._backward_hooks/self._forward_pre_hooks/self._forward_hooks。各个hook的调用顺序如下:
- Hooks:nn.Module类实现了3个通用的hook注册函数,用于注册被应用于全局的hook。该三个函数分别注册进3个全局的OrderedDict:_
- 模块存取:
- Hooks:
_register_state_dict_hook:在self.state_dict()的最后对模块导出的state_dict进行修改;_register_load_state_dict_pre_hook:在_load_from_state_dict中最先被执行。 - 实现细节:
state_dict()可用于获取模型当前的状态信息。其中,版本信息(_version)存于metadata中。数据保存通过_save_to_state_dict()实现,保存内容包括self._parameters以及self._buffers中的persistent buffer。load_state_dict()函数用于读取checkpoint。本质上是调用_load_from_state_dict函数来加载所需权重。每个子模块可以重定义自身的_load_from_state_dict函数,来避免BC-breaking(向后兼容)等问题。
- Hooks:
DP & DDP: 模型并行和分布式训练
- DP:
- 基本使用:
model=nn.DataParallel(model). - 原理:DP基于单机多卡,其中device[0]负责梯度整合和传播。包含三个核心过程:各卡分别计算损失和精度;所有梯度整合到device[0];device[0]进行参数更新,同时其他卡拉取device[0]参数进行参数更新。其中各卡计算损失和精度的过程是并行的。
- 实现:前向传播时,通过Scatter函数将数据从device[0]分配并复制到不同的卡,后用Replicate函数将模型从device[0]复制到不同的卡,然后各卡分别调用forward计算损失和梯度。反向传播的时候,通过gather函数将梯度收集到device[0]然后在device[0]更新参数。
- 基本使用:
- DDP:
- 基本使用:
1
2
3
4
5
6
7
8
# 初始化后端
torch.distributed.init_process_group(backend='nccl', world_size=ws, init_method='env://')
torch.cuda.set_device(local_rank)
device = torch.device(f'cuda:{local_rank}')
model = nn.Linear(2, 3).to(device)
# 这里通过规定device_id采用了单卡单进程
model = DDP(model, device_ids=[local_rank], output_device=local_rank).to(device)
1
2
3
4
5
- 原理:DDP也是数据并行的方式,即每张卡中都有模型和输入。通过Reducer来管理梯度同步。通过构建时注册autograd hook来进行梯度同步,当一个梯度计算好后,相应的hook会通知DDP进行规约。当某一梯度值满后(对应单个bucket),Reducer会启动异步的allreduce去计算所有进程的平均值。整个过程中,DDP可以边计算边通信,提高效率。当所有的bucket的梯度都完成计算后,Reducer会等所有allreduce完成,然后将得到的梯度更新:写到param.grad。
- 实现:backend通常采用NCCL,不过只支持GPU Tensor的通信。具体组成主要包含了三个部分:
- constructor:负责将rank 0的state_dict()广播,保证网络的初始状态一致;初始化buckets,控制parameters在buckets的逆序排列,提高桶通信的效率;为每个parameter加上grad_accumulator以及在autograd_graph注册autograd_hook,负载在backward时进行梯度同步
- forward:包含了正常的forward操作以及检查unused_parameters的操作:DDP会在forward结束时对traverse autograd graph找到没用过的parameters并标记为ready:开销很大,但是在动态图中是很有必要的,因为动态图可能会发生改变。
- autograd_hook:挂在autograd graph中负责在backward时负责梯度同步。 ```
torch.optim: 优化算法接口
基本概念:
- 组成部分: 优化器:训练阶段模型可学习参数的更新策略。 学习率:lr
- 调用过程:
optimizer.zero_grad()清空梯度->loss.backward()反向传播->optimizer.step()更新模型参数。
简单的调用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import torch
import numpy as np
import warnings
warnings.filterwarnings('ignore') # ignore warnings
x = torch.linspace(-np.pi, np.pi, 2000)
y = torch.sin(x)
p = torch.tensor([1, 2, 3])
xx = x.unsqueeze(-1).pow(p)
model = torch.nn.Sequential(
torch.nn.Linear(3, 1),
torch.nn.Flatten(0, 1)
)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-3
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
for t in range(1, 1001):
y_pred = model(xx)
loss = loss_fn(y_pred, y)
if t % 100 == 0:
print('No.{: 5d}, loss: {:.6f}'.format(t, loss.item()))
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 梯度下降法更新参数
No. 100, loss: 26215.714844
No. 200, loss: 11672.815430
No. 300, loss: 4627.826172
No. 400, loss: 1609.388062
No. 500, loss: 677.805115
No. 600, loss: 473.932159
No. 700, loss: 384.862396
No. 800, loss: 305.365143
No. 900, loss: 229.774719
No. 1000, loss: 161.483841
实现细节:
- optimizer:
- 支持的optimizer:SGD/ASGD/Adadelta/Adagrad/Adam/AdamW/Adamax/SparseAdam/RMSprop/Rprop/LBFGS
- 基类Optimizer:公用方法包括:add_param_group/step/zero_grad/state_dict/load_state_dict。其中step方法由子类(具体的optimizer类)实现。
- lr_scheduler:
- 支持的lr_scheduler:StepLR/MultiStepLR/ExponentialLR/ReduceLROnPlateau/CyclicLR/OneCycleLR/CosineAnnealingLR/CosineAnnealingWarmRestarts/LambdaLR/MultiplicativeLR
- 基类_LRScheduler:公用方法包括:step/get_lr/get_last_lr/print_lr/state_dict/load_state_dict。其中get_lr需要子类实现,state_dict和load_state_dict可能子类会重写。step函数为核心方法,该方法的调用逻辑为:last_epoch进行自增,然后调用子类的get_lr方法获得该epoch时的学习率,并更新到optimizer的param_groups属性之中,最后记录下最后一次调整的学习率到
self._last_lr。
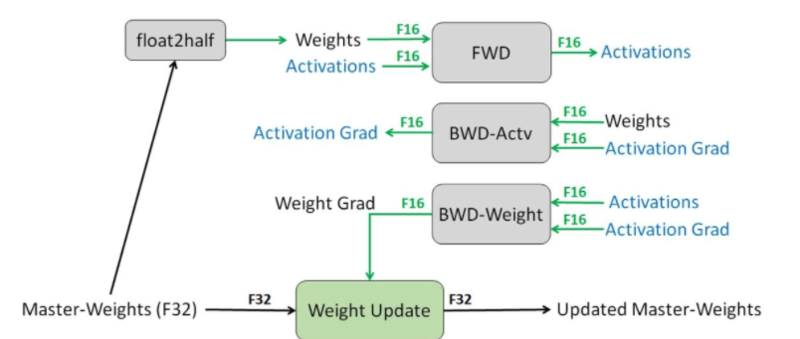
torch.cuda.amp: 自动混合精度
自动混合精度训练:训练FP32模型时,一部分算子操作精度为FP16,其余算子精度为FP32,而具体哪些算子用FP16还是FP32,通过amp自动安排实现。该方案的优势是:不改变模型,不降低模型训练精度的前提下,可以 缩短训练时间,降低存储要求 。因此能够支持更多的batch size/更大模型和尺寸更大的输入进行训练。
- 混合精度训练机制
- amp机制包含两个核心功能:自动选择合适的数值精度/对于FP16的梯度数值溢出问题,提供梯度scaling操作。
- autocast作为Python上下文管理器和装饰器来使用,用于指定脚本中某个区域,或者某些函数,按照自动混合精度来运行。其操作过程如下(训练过程中拷贝为FP16模型,FP16算子基于FP16数据进行操作,FP32算子输入输出仍为FP6,计算精度为FP32,之后基于混合精度进行反向传播得到FP16梯度,最后将FP16梯度和FP32参数进行参数更新):
scaling操作:FP16精度的表示范围较窄,存在问题是大量非0梯度会遇到溢出问题。解决方案为:对梯度乘2N系数,称之为scale factor,将梯度shift到FP16的表示范围。该操作通过GradScaler实现,其功能在于反向传播前给loss乘scale factor,然后在梯度更新前进行unscale操作。最终amp的训练流程可归纳为:
- 维护一个FP32数值精度模型的副本
- 在每个iteration
- 拷贝并且转换为FP16模型
- 前向传播(FP16的模型)
- loss乘scale factor s
- 反向传播(FP16的模型参数和参数梯度)
- 参数梯度乘 1/s(unscaling)
- 利用FP16的梯度更新FP32的模型参数
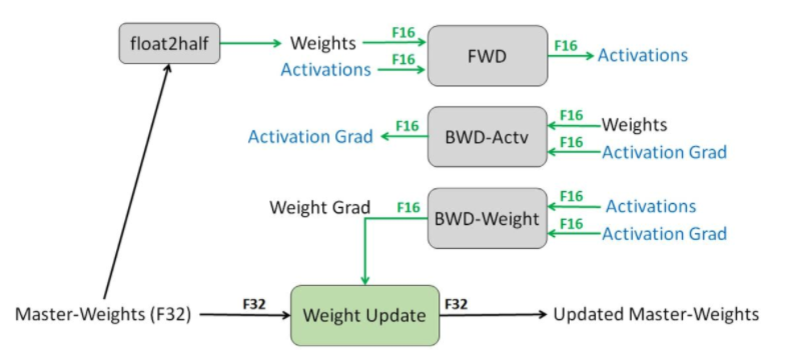
对于scale factor的选取的动态策略:根据loss动态变化。GradScaler涉及的scale factor每隔N个iteration乘一个大于1的系数,再scale loss;并且每次更新前检查溢出问题(inf/nan),如果有,scale factor乘一个小于1的系数并跳过iteration的参数更新环节,如果没有,则正常更新参数。训练流程如下:
- 维护一个FP32数值精度模型的副本
- 初始化s
- 在每个iteration
- 拷贝并且转换成FP16模型
- 前向传播(FP16的模型参数)
- loss乘scale factor s
- 反向传播(FP16的模型参数和参数梯度)
- 检查有无inf/nan的参数梯度
- 有:降低s,回到步骤1
- 无:继续至6
- 参数梯度乘1/s
- 利用梯度更新FP32的模型参数
- 实现细节
- API调用,基本操作如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
# amp依赖Tensor core架构,所以model参数必须是cuda tensor类型 model = Net().cuda() optimizer = optim.SGD(model.parameters(), ...) # GradScaler对象用来自动梯度缩放 scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() # 在autocast enable区域运行forward with autocast(): # model做一个FP16的副本,forward output = model(input) loss = loss_fn(output, target) # 用scaler, scale loss(FP16), backward得到scaled的梯度(FP16) scaler.scale(loss).backward() # scaler更新参数,会先自动unscale梯度 # 如果有nan或inf,自动跳过 scaler.step(optimizer) # scaler factor更新 scaler.update()
- API调用,基本操作如下:
- autocast类:作为上下文管理器和装饰器来使用,为算子自动安排按照FP16/FP32进行运算。autocast算子包含三类:FP16/FP32/按照FP16-FP32更大精度操作。对于autocast的enable区域 计算 得到的FP16数值精度变量在enable区域需要显示转化为FP32。另外,autocast作为装饰器使用(通常对于data parallel模型),设计为“thread local”,所以在main thread上设autocast区域是不work的。正确的姿势是对forward进行装饰:
1 2 3 4 5
class MyModel(nn.Module): ... @autocast() def forward(self, input): ...
或者在forward函数中设autocast区域:
1 2 3 4 5
class MyModel(nn.Module): ... def forward(self, input): with autocast(): ...
对于用户自定义的autograd函数,需要用
amp.custom_fwd装饰forward函数,amp.custom_bwd装饰backward函数。 - GradScaler类:几个关键方法包括:scale(output)/step/update:
scale:对outputs乘scale factor,并返回,如果enable=False,就原样返回。
step:梯度unscale,如果之前未手动调用unscale方法的话;检查梯度溢出,如果没有nan/inf,就执行optimizer的step,如果有就跳过。
update:在每个iteration结束前调用,如果参数更新则跳过,否则会将scale factor乘以backoff_factor。或者到了该增长的iteration时,将scale factor乘growth_factor,或者用new_scale直接更新scale factor。简单的使用样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
# Gradient clipping scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() with autocast(): output = model(input) loss = loss_fn(output, target) scaler.scale(loss).backward() # unscale梯度,可以不影响clip的threshold scaler.unscale_(optimizer) # clip梯度 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm) # unscale_()之前已被显式调用,scaler正常执行step更新参数,有nan/inf则会跳过 scaler.step(optimizer) scaler.update()
cpp_extension: C++/CUDA算子实现和调用全流程
Pytorch的C++/CUDA扩展能够对功能模块进行加速。下文以nms的实现来解释C++/CUDA算子的调用流程。 调用nms的样例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from mmcv import _ext as ext_module
from torch.autograd import Function
def nms(boxes, scores, iou_threshold, offset=0):
inds = NMSop.apply(boxes, scores, iou_threshold, offset)
dets = torch.cat((boxes[inds], scores[inds].reshape(-1, 1)), dim=1)
return dets, inds
class NMSop(torch.autograd.Function):
@staticmethod
def forward(ctx, bboxes, scores, iou_threshold, offset):
inds = ext_module.nms(
bboxes, scores, iou_threshold=float(iou_threshold), offset=offset)
return inds
@staticmethod
def symbolic(g, bboxes, scores, iou_threshold, offset):
pass # onxx转换相关
NMSop中的核心部分调用了mmcv._ext.nms ,存在于mmcv/_ext.cpython-xxx.so 文件中,通过 MMCV_WITH_OPS=True python setup.py build_ext --inplace 编译得到。 其中,setup.py入口为 setup 函数,该函数的一个主要参数为 ext_modules ,通过 get_extensions 函数得到,该函数会分别基于不同环境:C++/CUDA调用不同的拓展:CppExtension/CUDAExtension。两个拓展函数会将系统目录的库/头文件加入默认的编译搜索路径中,同时补充其他编译信息,最后生成gcc/nvcc命令:
1
2
3
4
5
6
7
8
setup(
name='mmcv',
install_requires=install_requires,
# 需要编译的c++/cuda扩展
ext_modules=get_extensions(),
# cmdclass为python setup.py --build_ext命令指定行为
cmdclass={'build_ext': torch.utils.cpp_extension.BuildExtension}
)
编译完成后,需要进行将C++/CUDA的二进制文件和Python进行连接,主要通过pybind11库实现,该库是用于在C++代码中创建Python的连接的库。pybind.cpp中的核心代码如下:
1
2
3
4
5
6
7
8
9
10
#include <torch/extension.h>
// 函数声明,具体实现在其他文件
Tensor nms(Tensor boxes, Tensor scores, float iou_threshold, int offset);
// TORCH_EXTENSION_NAME在编译命令中传入为_ext,表示了声明了名为_ext的Python module
// nms定义为_ext下的子模块
PYBIND11_MODEL(TORCH_EXTENSION_NAME, m) {
m.def("nms", &nms, "nms (CPU/CUDA)", py::arg("boxes"), py::arg("scores"),
py::arg("iou_threshold"), py::arg("offset"));
}
接下来便是实现具体的C++/CUDA算子,以下示例C++实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <torch/extension.h>
using namespace at; // ATen(A Tensor Library),为python扩展c++负责声明和定义Tensor运算的相关逻辑库
Tensor nms_cpu(Tensor boxes, Tensor scores, float iou_threshold, int offset) {
// 仅显示核心代码
for (int64_t _i = 0; _i < nboxes, _i++) {
// 遍历所有检测框,称为主检测框
if (select[_i] == false) continue;
for (int64_t _j = _i + 1; _j < nboxes; _j++) {
// 对每个主检测框,遍历其他检测框,称为次检测框
// 这里只用遍历上三角元素即可,节省计算
if (select[_j] == false) continue;
auto ovr = inter / (iarea + area[j] - inter);
// 如果次检测框和主检测框iou过大,则去除次检测框
if (ovr >= iou_threshold) select[_j] = false;
}
}
return order_t.masked_select(select_t);
}