文章背景
In-Datacenter Performance Analysis of a Tensor Processing Unit 发表于ISCA2017,主要介绍Google TPU的架构。
摘要
Google从2013年发现,大量的DNNs网络用于语音识别搜索,对算力的需求为当前数据中心的一倍。而大量传递运行深入学习的网络需求对当时的CPU/GPU来说,成本较高。
Tensor Processing Unit(TPU): Google自2015年开始开发,专注于NN网络的推理加速,属于一种ASIC(专用集成电路)。
芯片基本规格:
- MAC矩阵单元:65,535 8-bit
- Accumulator:4MiB 32bit,用于处理MMU乘积后得到的16bit运算结果
- Weight FIFO:MMU从on-chip Weight FIFO获取数据,FIFO的数据从off-chip DRAM Weight Memory(推断为只读Weight)。FIFO深度为4个tile。计算中间值存储在24MB的on-chip Unified Buffer(UB)当中,同时UB可以作为MMU的输入。UB与主存通过DMA传输数据。
- On-chip memory:28 MiB 片上内存
The heart of the TPU is a 65,536 8-bit MAC matrix multiply unit that offers a peak throughput of 92 TeraOps/second (TOPS) and a large (28 MiB) software-managed on-chip memory.
性能比较:除了部分网络外,TPU吞吐率为对应GPU/CPU的15X - 30X,能耗比(TOPS/Watt)则达到30X - 80X。
Despite low utilization for some applications, the TPU is on average about 15X - 30X faster than its contemporary GPU or CPU, with TOPS/Watt about 30X - 80X higher.
具体比较结果:
对比网络需求主要为三类网路:MLP/LSTM/CNN
比较结果:
重点关注推理的反应时间,比较对象:K80 GPU/Haswell CPU
在功耗更低/芯片更小的情况下,TPU的MACs(8-bits mul)为K80的25倍,on-chip memory为K80的3.5倍,推理速度为K80 GPU和Haswell CPU的15X - 30X
4/6 NN apps在TPU上的性能存在memory-bandwidth limited的问题,如果实现类似K80 GPU类似的memory system,性能能达到30X - 50X。
设计方案
设计初衷: 类似于GPU,集成了PCIe/IO总线,能够直接插入现成服务器设备中,但是TPU不具备从内存取指令的能力,而是服务器将指令发送到片上存储中。下图为设计架构图以及硬件布局图。 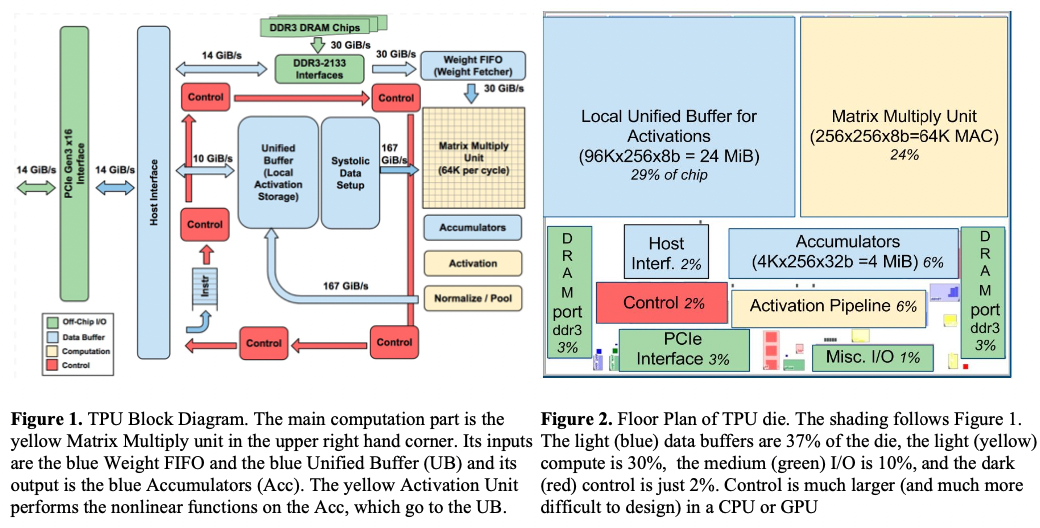
架构设计:主要计算单元为矩阵乘法单元Matrix Multiply,输入包含两个部分:FIFO(权重矩阵)/UB(输入数据),其输出为累加器单元(Accumulators)。同时还有专门的非线性单元/Normalize/Pool单元。
硬件布局:UB占据了29%的面积,计算单元(Matrix/Activitation)占据了30%的面积,其余主要为其他数据总线/交互接库/累加器。 关键特性:double buffer/暂时不支持稀疏特性,DRAM/FIFO构成矩阵权重数据存储单元,UB作为矩阵输入数据存储单元。核心思路是通过计算流水掩盖其他计算/数据搬运流水。
TPU架构的设计哲学: The philosophy of the TPU microarchitecture is to keep the matrix unit busy.
但是由于从SRAM中读取数据消耗的功率比算术运算要大的多,所以TPU使用统一缓存区来减少读和写。采用“脉动运行(systolic execution)”来减少能耗,其原理是不同方向的数据以固定的间隔时间到达阵列中的单元,然后在单元中组合数据,其数据流如下图: 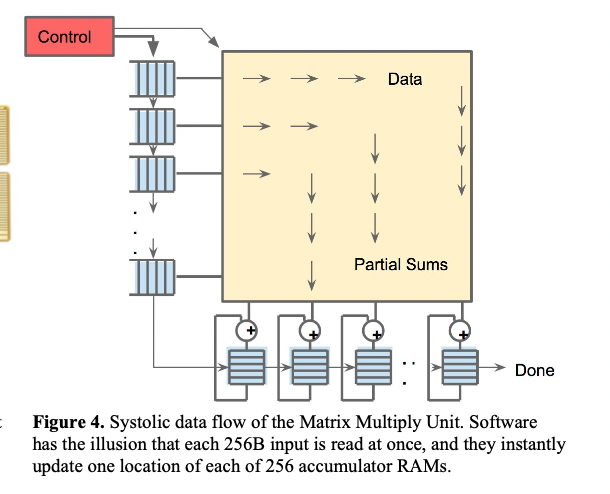
上述数据流中,给定的256-element(数据大小存在对齐限制)乘加操作在矩阵中以对角波(diagonal wavefront)向前运动。权重是提前加载的,能够立即更新每一个256累加器的每个为止。矩阵的脉动阵列对于软件是透明的,方面代码编写。
TPU指令通过PCI传递,设计上按照CISC的设计思路,平均CPI在10到20之间,大概包含了10+,其中关键指令如下:
- Read_Host_Memory:从CPU主存当中读取数据到UB
- Read_Weights:从Weight Memory当中读取数据到Weight FIFO中作为MMU输入
- MatrixMultiply/Convolve:使MMU进行一次矩阵乘法/卷积操作,数据来自UB结果存入Accumulators。一次矩阵操作抓去B*256个输入(B可变),并产生B*256个输出,在B个流水线周期内完成。
- Activate:执行神经网络的非线性激活操作,包括ReLU/Sigmoid等。输入从Accumulators中来,输出写入到UB当中,也可以进行池化操作。
- Write_Host_Memory:将UB当中的数据写入主存。
指令的设计思路是:尽可能提高MMU的利用率,因此采用4段流水线的CISC指令,每个指令阶段独立的工作。
性能结果
具体网络应用情况:在Inception V2网络上优势较大,但是对于AlexNet/VGG网络性能则较差。
Ironically, deploying and measuring popular small DNNs like AlexNet or VGG is difficult on production machines. However, one of our CNNs derives from Inception V2, which is widely used.
下表显示了CPU/GPU(Boost mode disable)/TPU参数/性能/功耗对比: 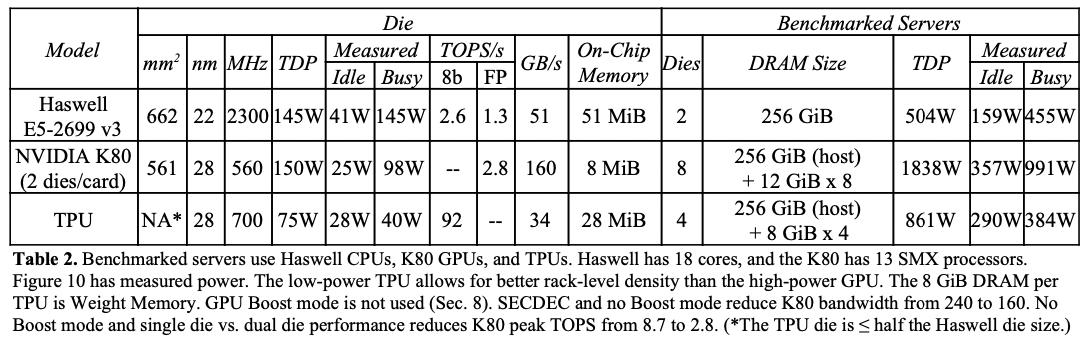
下图显示了模型的roof-line,其中关于计算强度可以参考Tops介绍-知乎: 核心知识点:
- 横轴为运算强度,即读入单位数据,能支持多少运算操作
- 纵轴为单位时间的计算量,或者理解为每秒吞吐量
- 分为两个区域,左边为上升区,表示随着运算强度的加大,吞吐量能够不断上升,斜率表示带宽;右边为饱和区,表示即使不断加大运算强度,也无法带来性能提升,达到算力瓶颈。
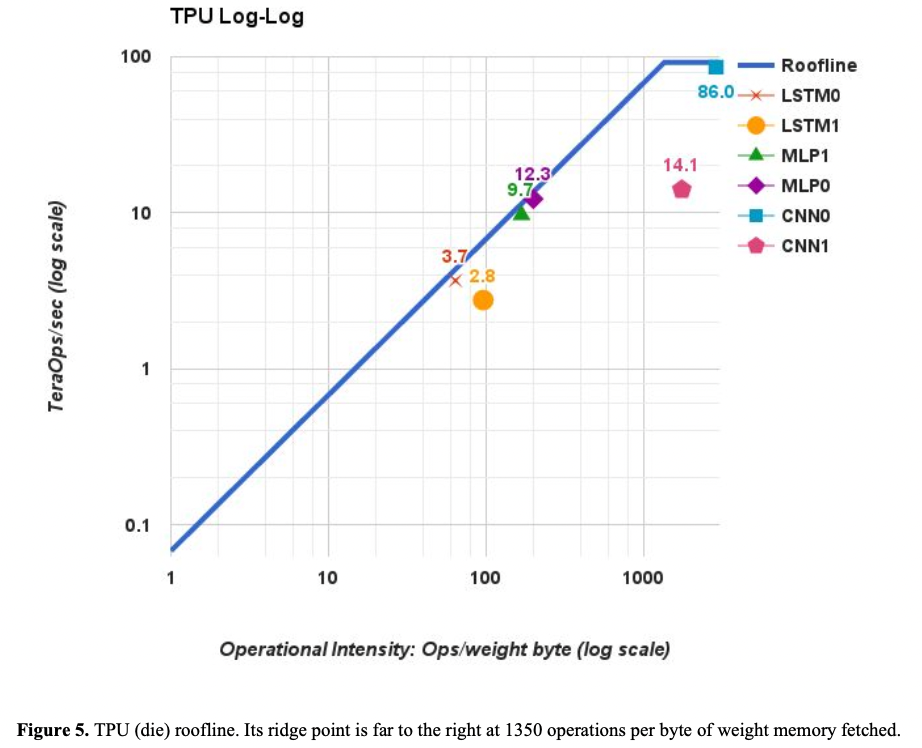
论文给到了6个模型的roofline model,可以看到:MLP/LSTM都受限于运算强度低导致性能不佳,但是CNN1的性能问题主要是其feature map深度小,导致计算单元需要等待权重搬入(35%时间),未完全发挥算力。
下图集中比较了TPU/CPU/GPU的roofline/performance && Watt/Watts && Workload的对比。另外不同不同负载下的芯片耗能不同,且大部分情况芯片都是非100% work load的: 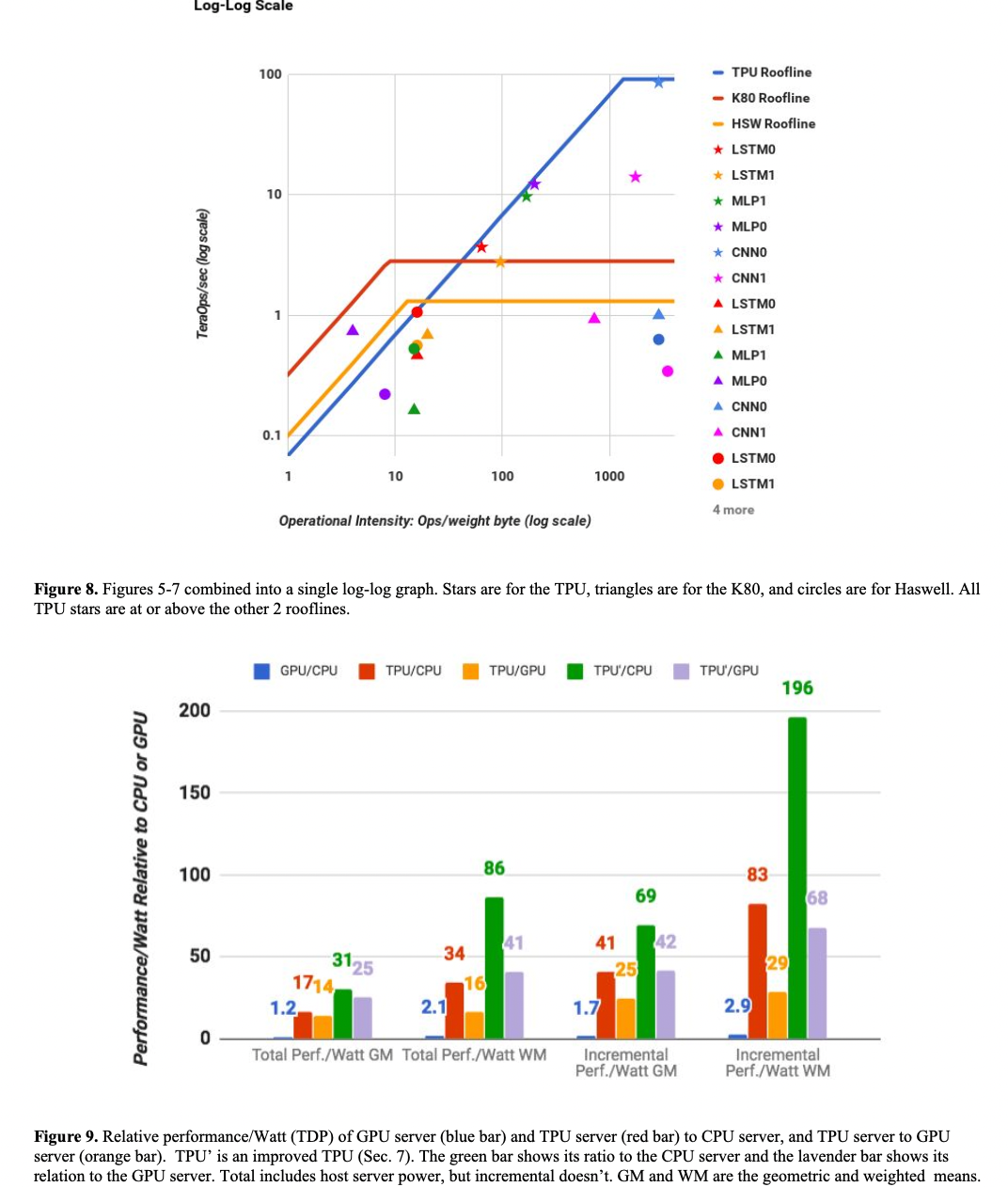
同时分析当前网络的性能瓶颈,可发现增大memory带宽对性能的收益最大: 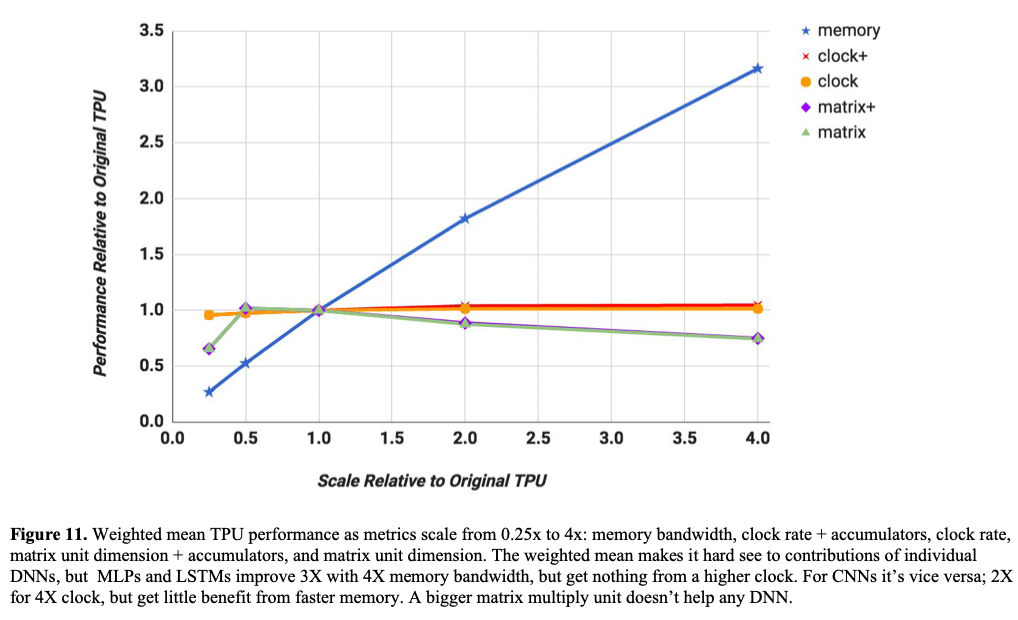
Discussion && Conclusion
文章强调了 reponse time 的重要性,且认为TPU相对于GPU存在优势:
Given their throughput-oriented architectural approach, it may be more challenging for GPUs to meet the strict latency limits.
总结观点:
- TPU的优势:尽管带宽受限,但得益于其架构设计,TPU仍然在性能上存在优势:在相对较小的芯片面积上集成了更多的算力和片上内存,同时相对GPU(K80)消耗不到一半的功率。当前TPU架构的核心特性:
- 适当大小的矩阵计算单元
- 独立在device侧的推理过程,减少对CPU的依赖
- 省略了一些通用设计(取指令,多线程等),为数据通路和存储节省面积
- 8bit整型量化应用
CNN的实际工作负载仅占了5%,MLPs/LSTMs需要更多关注。
- 实际应用中,需要关注host侧和device侧的时延
最后总结TPU的整体优势:相对更大的矩阵运算单元/更大软件可控的片上存储/完全device侧的模型推理能力(减少host cpu的依赖);即本身定位为放弃了通用特性,但是实现了小型化/低功耗,但是datapath/memory更大的专用芯片,能够作为“domain-spcific architectures”的芯片原型。
个人观点
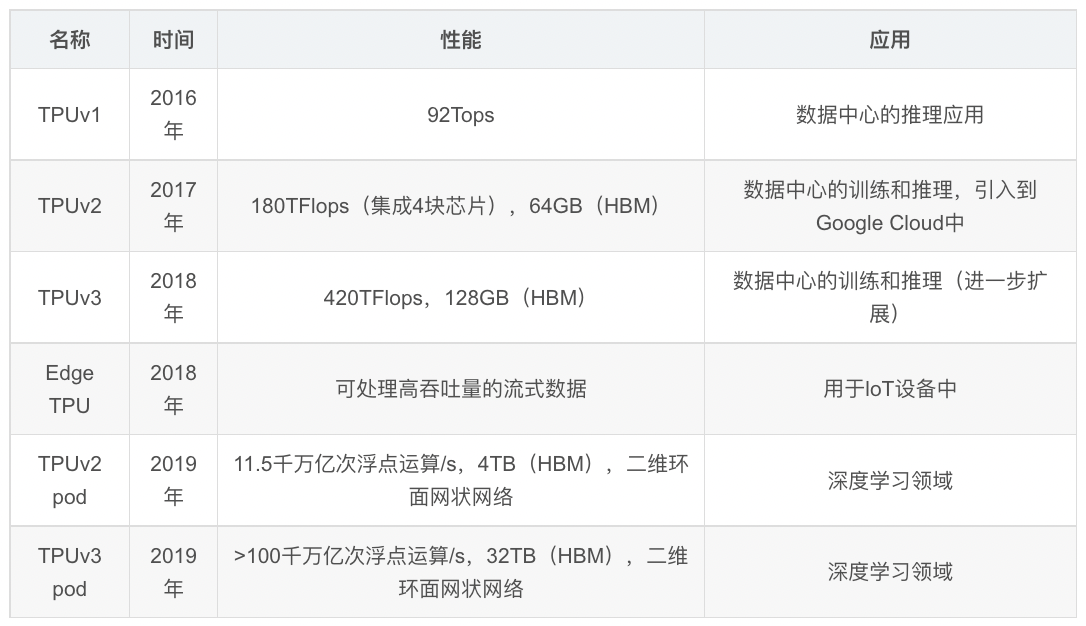
- 对比的GPU为K80,并不是性能较好的一款GPU,对比结果缺乏足够说服力,当前TPU后续也有v2,v3,后续芯片发展可见下图
- 文中也提到:增加memory bandwidth对TPU的增长是关键的
- response time在论文中重点强调了,但是目前最新的GPU框架貌似影响很小了