硬件篇
GPU
GPU(Graphics Processing Unit),全称为图形处理器,是一种在个人电脑、工作站和一些移动设备上做图像和图形相关运算的微处理器。最早由NVIDIA公司在1999年8月发表GeForce 256芯片时提出的概念。早先,GPU的功能更多地应用在图像计算(尤其是三维绘图运算),如硬件坐标转换、立体环境材质贴图等。GPU根据接入方式可以划分为独立GPU和集成GPU。独立GPU一般封装在独立的显卡电路板上,拥有独立显存;而集成GPU通常会和CPU共用资源,如系统内存。根据应用端区别,GPU可以分为PC/服务器/移动端GPU。
当前传统GPU市场(PC/服务器侧)基本被国外厂商垄断,前三厂商Nvidia/AMD/Intel的营收收入基本占据了整个GPU行业收入,其中INtel的营业收入主要来源于集成显卡。移动端GPU,如手机/平板GPU,头部厂商主要为ARM/高通/苹果。就行业而言,GPU在过去的20多年来的主要需求来源于视频加速、2D/3D游戏;但是随着GPU在并行处理和通用计算上的优势,在人工智能、边缘计算领域等逐渐迎来爆发。就NVIDIA而言,2021年营收收入为167亿美元,其中游戏收入占比47%,数据中心收入占比40%,专业视觉/自动驾驶业务占比9%。对于计算产业而言,衡量GPU的维度主要是通用性、易用性和高性能:即硬件框架需要足够灵活;开发门槛低,易于上手;芯片基本性能和性价比高。 国产GPU发展相对滞后,最早的GPU芯片JM5400最早由景嘉微于2014年开发。其他较为知名的厂商包括:壁仞科技、芯原股份、登临科技、海思等。
NVIDIA
对于大型数据中心、人工智能、超算领域,高端GPU逐渐成为算力刚需。NVIDIA在高端GPU的市场份额占比超过90%。截止当前,NVIDIA已经推出了Volta、Ampere、Hopper等用于高性能计算和AI训练架构,对应的GPU包括V100、A100、H100等,面向向量的双精度浮点运算能力从7.8TFLOPS到30TFLOPS。下文重点介绍下NVIDIA最新的Hopper架构。NVIDIA近10年的GPU微架构演变为:Tesla->Fermi->Kepler->Maxwell->Pascal->Volta->Turing->Ampere->Hopper。
介绍Hopper架构之前,先简单介绍下NVIDIA GPU的基本单元SM(streaming-multiprocessor),其基本结构如下(不同架构下的SM单元组成存在部分区别):
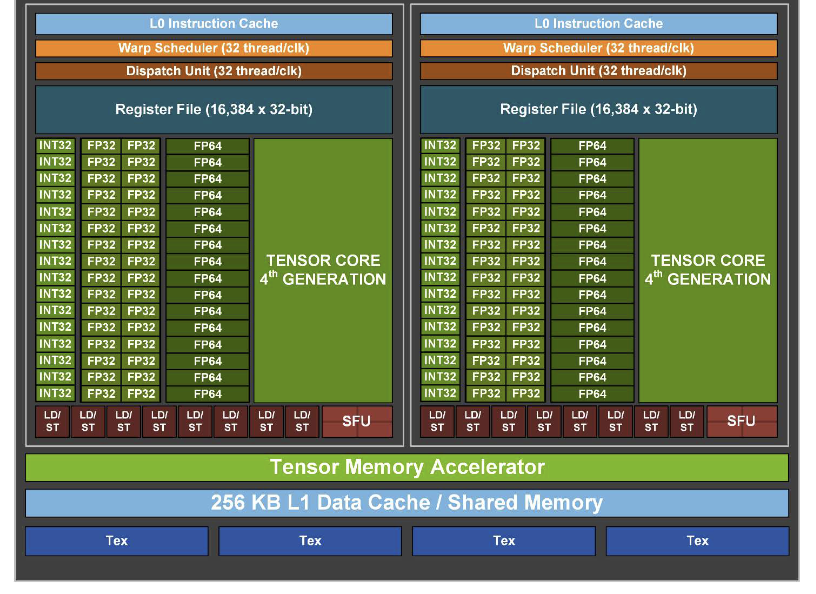
SM单元被认为是GPU的心脏,几个核心单元包括:
- CUDA Core: Fermi架构前也被称之为SP(scalar processor core),为通用计算单元,能够通过单指令实现“乘加运算”。根据支持的数据类型,分为INT32、FP32、FP64 Cuda Core单元。
- Tensor Core: Volta架构后引入,主要用于矩阵运算(MMA),支持FP16/FP32混合精度
- LD/ST: 全称Load/Store Unit,访存单元
- SFU:全称Special function unit,特殊数学计算单元,如sin/cos
- Warp Scheduler: warp为NVIDIA线程调度基本单位,每个SM都有wrap scheduler用于wrap调度
- Dispatch Unit: 负责将wrap scheduler指令送往core(cuda core/tensor core/LD/ST/SFU)执行
- L0 Instruction Cache: SM单元内置缓存
- Register File: 寄存器资源,被切分到每个SM单元
SM单元外是张量内存加速器(TMA,Tensor Memory Accelerator)/L1缓存/Shared Memory。其中TMA可以在全局内存和共享内存之间高效地传输大块数据、异步复制数据等功能。
NVIDIA Hopper架构在NVIDIA架构白皮书上有更为详细的说明,这里做重点内容的梳理。
- 4nm工艺,H100而言,SXM4外形尺寸下功耗为700W,内存带宽3TB/s,相对A100,H100时钟速度增加30%,SM数量增加1.2倍
- SM单元关键特性:每个SM单被组织为4个象限,每个象限包含16个INT32单元,支持混合精度的INT32/INT8/INT4处理;32个FP32单元,支持FP16/FP32混合精度;16个FP64单元;384个32位寄存器;8个LD/ST单元;4个SFU单元;1个Tensor Core
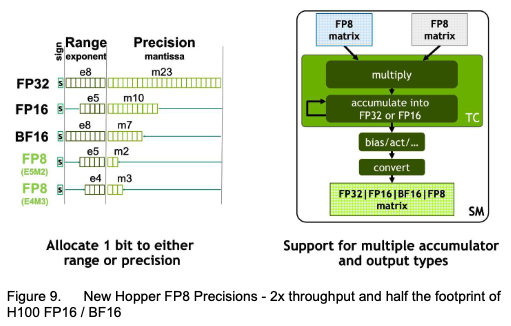
Tensor Core关键特性:采用了第四代Tensor Core架构,运算吞吐量提升一倍。Tensor Core支持FP8/FP16/BF16/TF32/FP64和INT8 MMA数据类型。其中,FP8 Tensor Core为新增数据类型,能够支持多个累加器数据类型和输出类型(参考下图),同时可通过Transformer引擎进行FP8/FP16精度选择,保持精度的同时提升吞吐量(~2倍)。

- shared memory/L1 Cache:H100 L1 Cache为256KB/SM,A100为192KB/SM,共享内存最大到228KB
- 综合性能对比:结合1中的时钟频率和SM数量,3中的Tensor Core算力提升和transformer引擎,H100相对A100的算力提升约6倍。
壁仞科技
国产GPU相对公开的资料较少,以壁仞科技为例,当前BR100系列包含BR100、BR104两款芯片。BR100核心参数如下:
- 2048 TOPS INT8/1024 TOPS BF16/512 TOPS TF32+/256 TOPS FP32
- PCIe 5.0接口 128GB/s,BLink(对标NvLink)
- 300+MB缓存,2.3TB/s外部I/O带宽,64路编码,512路解码,2.5D CoWoS封装 7nm工艺 550W功耗
芯片架构整体框架图如下,主要包含几个部分:计算单元、2Dmesh片上网、HBM2e存储系统、媒体引擎、PCIe 5.0接口、BLink互联接口:

芯片中的核心计算单元SPC,类比GPU的SM单元,每个SPC包含16个EU(Execution Unit),每个EU单元含有16个通用计算核(V-core),和一个Tensor core,指令集层面采用的是SIMT,同时采用类NVIDIA的C-Warp协作并发,因此兼容CUDA。采用分布式shared L2cache,通过片上网连接

XPU
Google-TPU
Google从2016年起,第一次提出了第一代TPU(Tensor Processing Unit),其定位为:AI accelerator application-specific intergrated circuit(ASIC)。截止2022年,TPU已经发布到TPUv4: 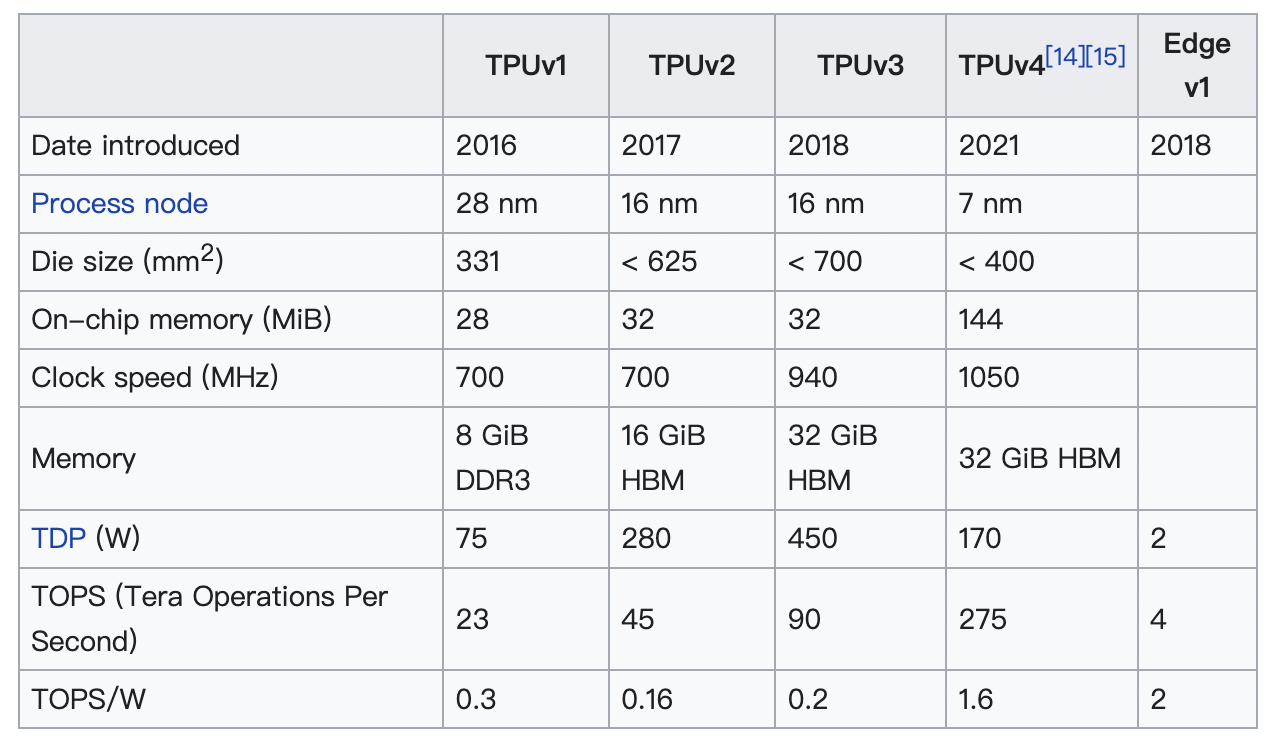
Google TPU最早发布于2017年,详细介绍可参照Google-TPU论文解读。其结构设计如下:主要计算单元为矩阵乘法单元Matrix Multiply,输入包含两个部分:FIFO(权重矩阵)/UB(输入数据),其输出为累加器单元(Accumulators)。同时还有专门的非线性单元/Normalize/Pool单元。TPU架构的设计哲学: The philosophy of the TPU microarchitecture is to keep the matrix unit busy.
TPU v4的设计框架如下:
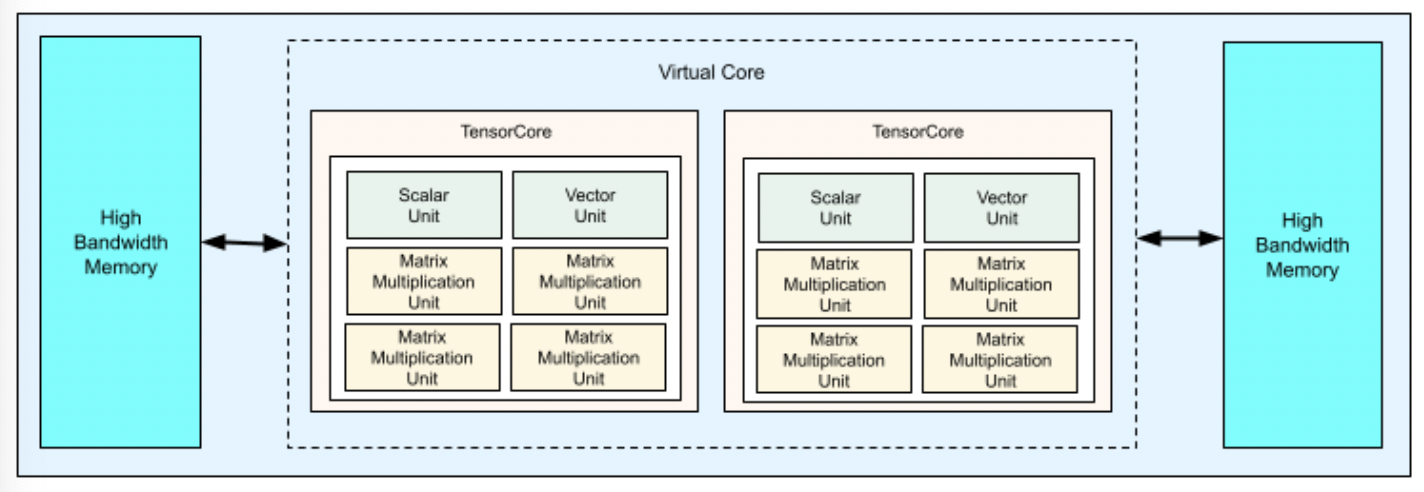
每个 v4 TPU 芯片包含两个 TensorCore。每个 TensorCore 都有四个 MXU、一个矢量单位和一个标量单位。
晟腾
晟腾AI加速卡当前主要有Atlas 300I Duo/Atlas 300I Pro/ALtas 300V Pro三类卡。以300I Duo卡为例:
- 7nm工艺,280 TOPS INT8,140 TFLOPS FP16,LPDDR4x 48GB,总带宽408GB/s,支持ECC,编解码能力 很强 ,PCIe Gen4.0,兼容3.0/2.0/1.0
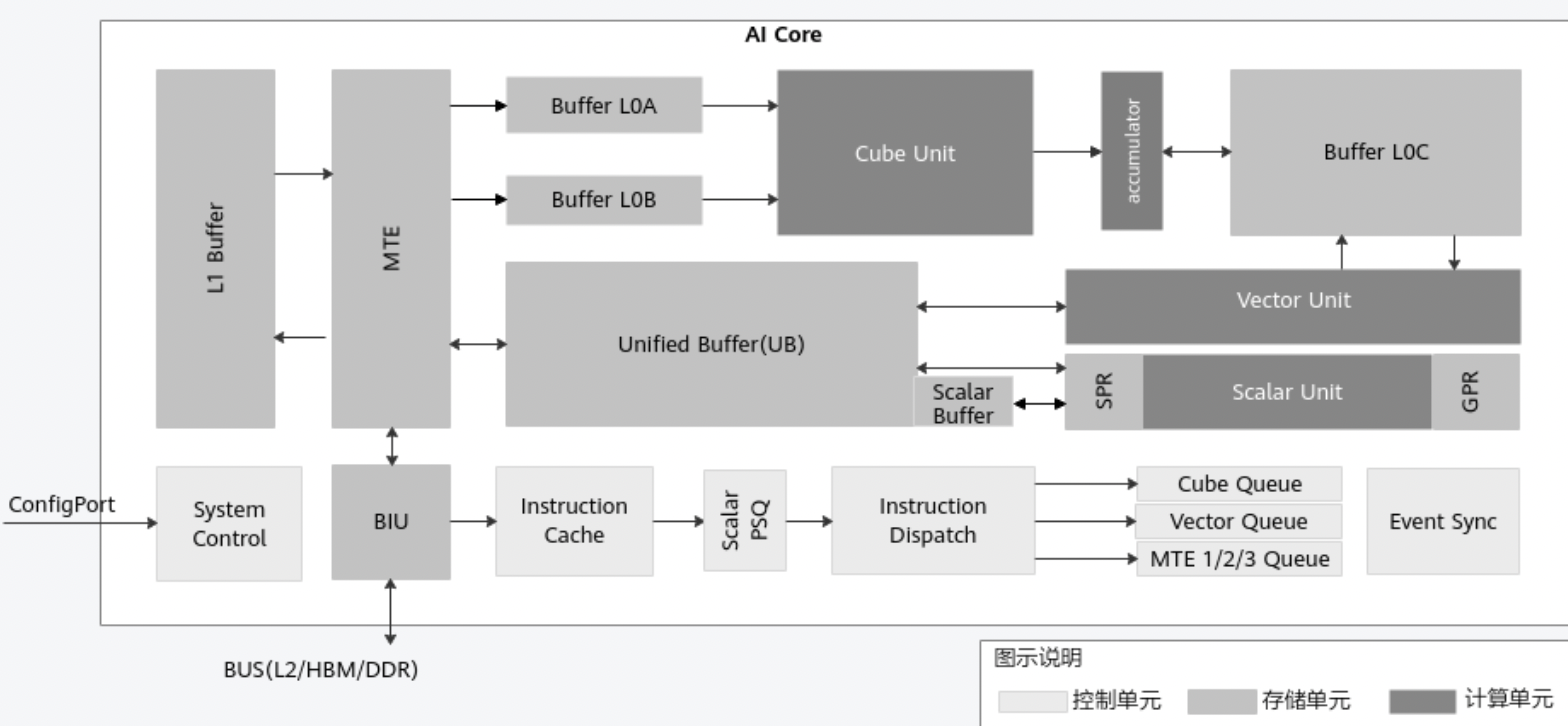
架构层面采用的是自研的达芬奇架构,核心点在于计算单元设计(Cube/Vector/Scale Unit)和多级缓存设计(UB/L1/L2),和TPU设计思路”不谋而合:
昆仑
昆仑芯片当前XPU-K/XPU-R两个架构(材料可参考:Baidu Kunlun An AI processor for diversified workloads):
- 第一代架构:XPU-K K200为例:14nm工艺,256 TOPS@INT8算力 64TFLOPS@FP16 PCIe 4.0x8 HBM高速显存,512GB/s内存带宽
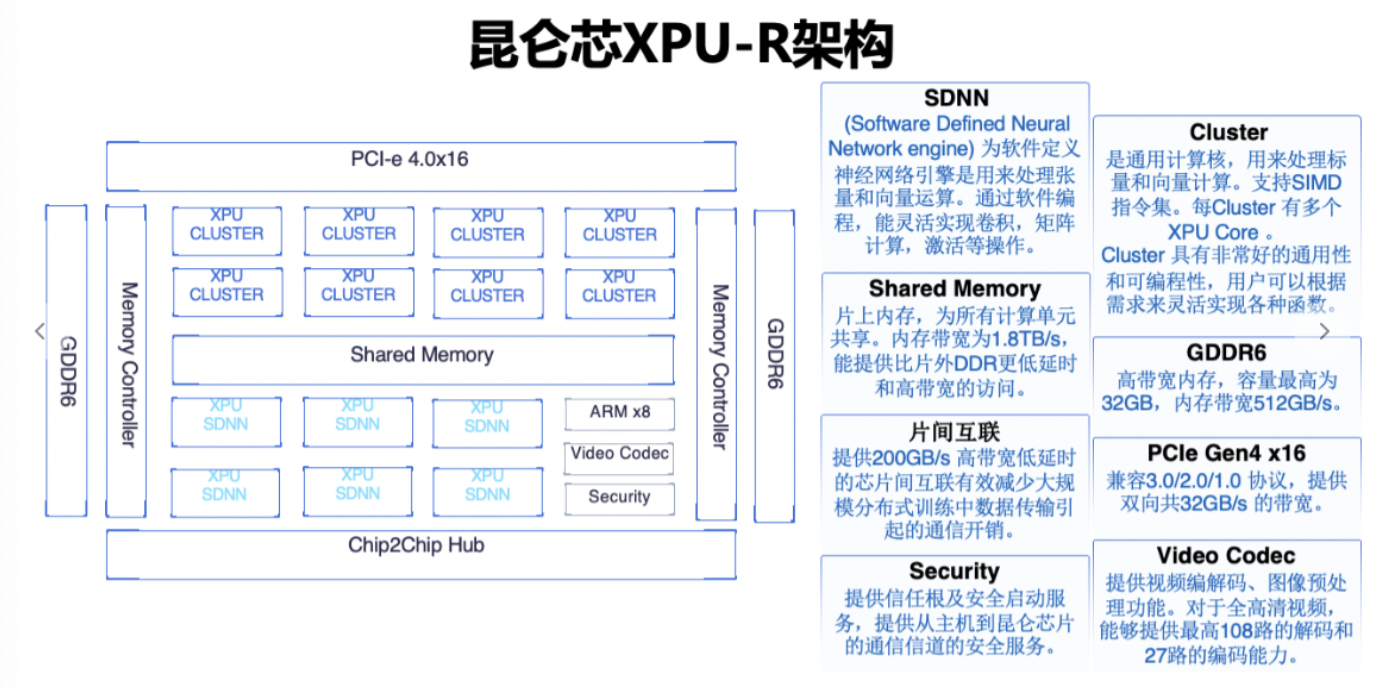
第二代架构:XPU-R R200为例:7nm工艺,256 TOPS@INT8算力 128TFLOPS@FP16 GDDR6高性能显存 PCIe 4.0x16 XPU-R架构如下:
寒武纪
寒武纪芯片截止当前(2022/11),官网当前加速卡共有三代产品:思元1xx/思元2xx/思元3xx,最新的思元370芯片相关参数信息如下:
- 思元370:7nm工艺,256 TOPS@INT8算力,MLUarch3框架,支持LPDDR5,MUL-Link互联
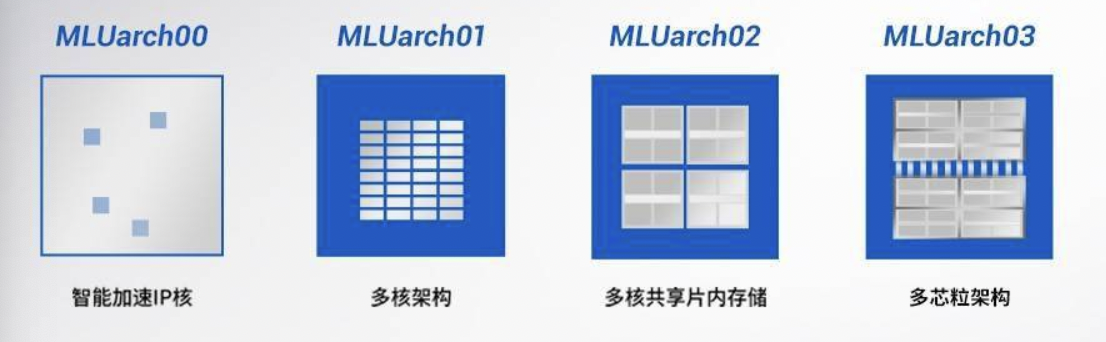
对于MLUarch3架构,资料较少,其架构演变过程如下:
芯粒技术(Chiplets)是涉及芯片设计制造的一种技术:将功能拆分为小块,拥有可重复使用的IP区块,可以进行模块化组合;能够增加其良品率,降低生产成本。该技术被部分厂家认为是延续摩尔定律的关键。当前很多芯片厂家都提出了各自的芯粒技术,如台积电的无凸起的系统整合单晶片(System on Integrated Chip),AMD的Zen2架构,Intel的Foveros的3D堆叠技术的异构系统集成方案。
设计架构层面,寒武纪自2014年发布了多个架构,分别为:
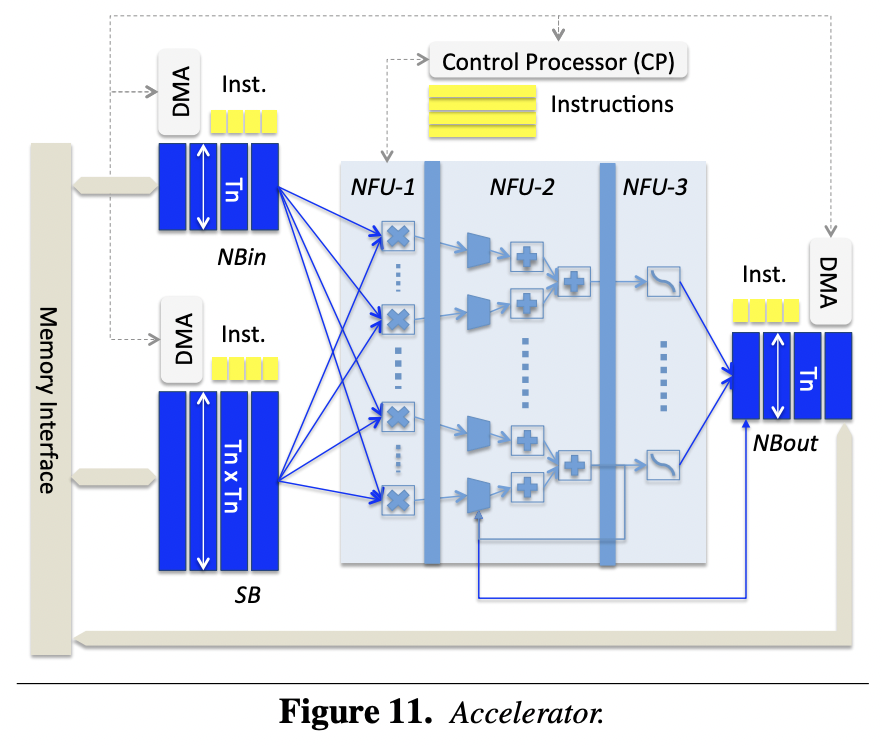
DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning 首次提出了NFU(Neural Function Units)结构,包括三个部分:NFU-1,全乘法单元;NFU-2,加法树;NFU-3,激活单元。另外还有三个Buffer,分别存储输入数据、权重、计算结果。
- DaDianNao: A Machine-Learning Supercomputer 为DianNao的多核版本,通过多片设计,将大模型放在芯片内存上运行。
- ShiDianNao: Shifting Vision Processing Closer to the Sensor 集成了视频的编解码等操作
- PuDianNao: A Polyvalent Machine Learning Accelerator DianNao收官之作,支持了7种机器学习算法:神经网络、线性模型、支持向量机、决策树、朴素贝叶斯、K临近和K类聚。
- Cambricon-X: An Accelerator for Sparse Neural 添加了对稀疏网络的支持
软件篇
NPU的schedule和传统CPU的schedule策略存在很大的区别,而实现的NPU高性能计算的目标便是:基于NPU策略来得到最大程度的加速。其中涉及的内容包括:内核驱动、内存管理、系统调用、上下文切换等操作系统相关的知识。很多遇到的问题也是类似的:cache利用率、DDR latency等。
TODO 核心内容
参考
深度学习的异构加速技术(三):互联网巨头们“心水”这些 AI 计算平台
英伟达NVIDIA为何可以在高性能计算GPU中处于不败地位?