前言
本文主要简单谈谈深度学习中常用的Loss函数: 从原理和应用两个方面介绍
参考资料: 深度学习-Loss函数 AI初识境
详细介绍
主要从应用领域维度进行介绍:
- 分类任务:如交叉熵损失/KL散度/折页损失等
- 回归任务:如L1/L2损失等
- 检测任务:主要是由分类损失和回归损失两个部分组成,但是基于检测任务进行了优化
分类任务Loss
Cross Entropy Loss
交叉熵损失为分类任务中最为常用的损失函数,交叉熵的关键定义为:
\[y_i * log(1-p_i)\]其中,$y_i$ 表示为label值,$p_i$ 表示为预测值概率。对于二分类,$y_i$ 为0/1;对于多分类则为one-hot变量(仅gt值为1),即只会得到预测的gt值的损失。
DL中一般会通过softmax/sigmoid转换为概率分布后通过交叉熵计算损失,如torch.nn.CrossEntropyLoss
KL散度
KL散度的作用在于衡量两个分布的相似度,KL散度定义为:
\[KL散度 = 信息熵 - 交叉熵\]其中信息熵表述的是正确值(GT)的数据分布:$y^{gt} log(y^{gt})$ , 而交叉熵表述的是正确值和预测值之间的熵分布差异: $y^{gt} log(y^{pre})$ 。对于信息熵来说,其本身可以认为为定值,所以对KL散度的优化问题便可以转化为交叉熵的优化问题。
KL散度最常用的场景是 Distillation 中对 soft-label 使用的 KL divergence ,主要用于衡量两个 Teacher Model 和 Student Model 分布的差异。
其展开后第一项为原始预测分布的熵,为固定项,可以消去;第二项为 $-qlog(p)$ ,即 cross_entroy ,区别在于这里得到的是 loggits 输出为连续概率。
Hinge Loss
Hinge Loss分布如下:
其公式如下:
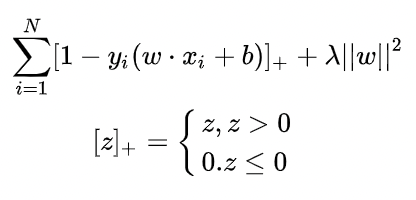
其核心在于区别简单的0-1损失,hinge loss需要正负例之间要有足够的区分度:margin值要足够大,是更严格的损失函数。
指数损失
指数损失定义如下:
\[L(Y, f(X)) = exp(-Yf(X))\]其中,$Y$ 为预测结果,$f(X)$ 为预测概率值 应用场景: Adaboost
回归任务Loss
MAE Loss
MAE,全称为“Mean Absolute Error”,为平均绝对值误差,即L1 Loss,其定义如下: 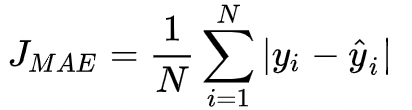
该loss适合 模型输入于真实值误差如何拉普拉斯分布(u=0, b=1) ,拉普拉斯分布结果如下: 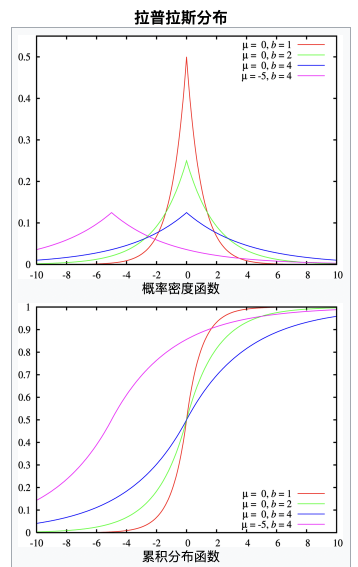
MSE Loss
MSE,全称为“Mean Squared Error”,为均方差误差,即L2 Loss,定义如下:
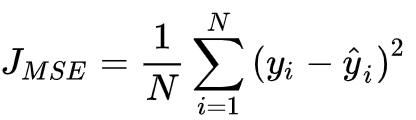
该loss适合 模型输出于真实值误差符合高斯分布情况 ,原理为 最小化均方差损失函数于极大似然估计本质上一致的 。
Smooth L1 Loss
SmoothL1 Loss相较于L1 Loss在x=0时仍然可导,采用的方式是abs(x)<1时采用二次函数进行过渡,可参考:Smooth_L1_Loss_Pytorch ,定义如下:
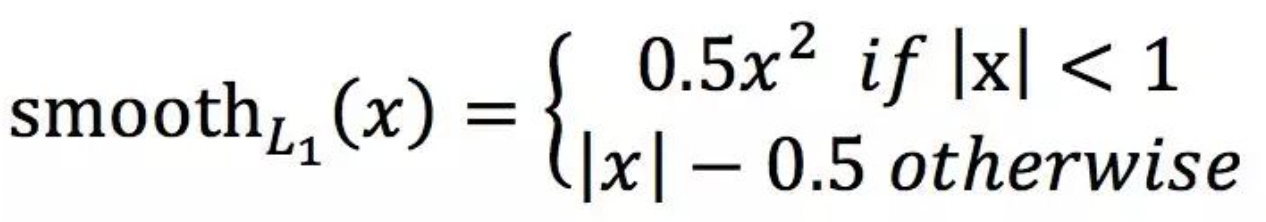
Faster-RCNN中使用Smooth L1 Loss,作者认为其对smooth L1 loss让loss对于离群点更加鲁棒,即:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
Huber Loss
Huber Loss为MSE和MAE Loss的组合,其原理是在误差接近0时,使用MSE,保持可导,梯度稳定;在误差较大的情况下使用MAW,降低异常点影响,维持训练稳定。其定义如下: 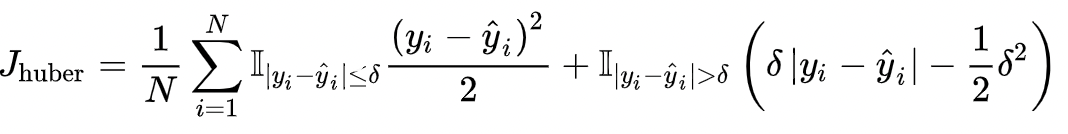
检测任务Loss
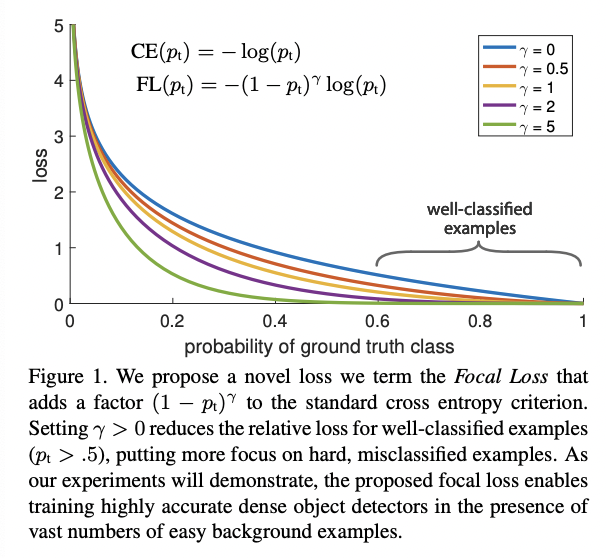
Focal Loss
Focal Loss出自2017 CVPR:Focal Loss for Dense Object Detection,出自何凯明团队,在目标检测领域应用极广,重点解决了检测任务中 正负例样本不均衡 的现象。其函数定义如下:

其中,p表示为预测的置信度。Focal Loss的作用在于能够增大hard case的loss,从而在训练过程中更多得关注困难case,提高模型性能,同时也能加快收敛。Focall Loss是在交叉熵损失上的延伸,两者的区别如下:
QFocal Loss
QFocal Loss出自Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection 其出发点在于:
随着One-Stage检测算法的不断发展,对于检测任务,原始的分类和回归损失分离的方案逐渐显露出一些弊端,同时一些描述定框质量的方法:如centerness/IoU Loss,也带来一些思考:如何将描述框准度和分类损失进行结合,QFocal Loss便是将定框质量和分类损失进行了结合。 QFocal Loss于Focal Loss的区别在于:Focal Loss描述的是离散类别的损失,QFocal Loss描述的是连续Label上的损失(定框质量),其定义如下:
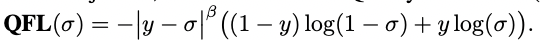
IoU Loss
IoU Loss为检测任务中常用的回归Loss,于传统的L1/L2 Loss相比,IoU Loss于检测任务最终的评估方式对应,能够更好的描述预测框的精度,且具备尺度不变性,通常有更好的性能表现,其基本定义如下:
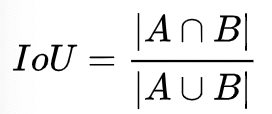
其中,A,B分别表示检测框和GT框。但是IoU损失存在一些问题:
- 无法描述不相交的框的损失
- 无法精确描述框的交互情况:检测框和GT框在不同位置,其IoU可能是一致的。
在IoU Loss的基础上,后续也有一些优化的Loss:
- GIoU Loss:引入外接矩形,不仅仅关注了重叠区域,也关注了非重叠区域,添加了不相交的框的loss描述。
- DIoU/CIoU Loss:DIoU Loss对框间的各点距离进行了更细致的建模,收敛更快。CIoU Loss引入长宽比的相似度。
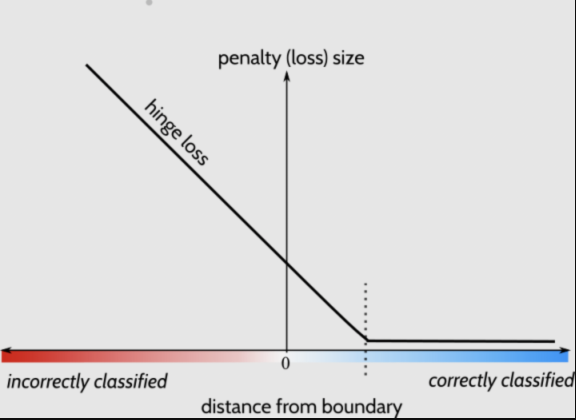
各Loss应用于YOLOv3上的效果如下: