前言
深度学习网络的加速问题包含两部分内容:网络结构侧的加速和工程侧的加速。工程层面的加速,网络结构基本是不变的,更多从网络推理角度探讨如何在不损失精度(或者损失较小)的前提下,提高模型的推理速度(吞吐率)。
详细介绍
工程加速
Distillation
Distillation是一项常用于模型加速的技术。Ditillation通常包含两个模型:Teacher Model/Student Model, 其中Student Model的模型结构通常更加简单,速度更快。但是通过Distillation可以利用Teacher Model的中间输出结果来“指导”Student Model的训练,从而能够使得在Student Model的高速度的前提保持和Teacher Model基本一致的精度。
Distillation的基础原理在于提取Teacher model的高维度的输出作为Student model的训练输入,能够让Student model更好的学习。其中高维度的输出包括logits(soft-label)和hint feature(softmax前的feature)。同时通过控制T来实现不同平滑程度的分布(softmax前除以T)。Distillation的开山之作为:Distilling the Knowledge in a Nerural Network,文章第一次定义了Distillation,并且提出了基于神经网络的训练方方法。典型的Distillation框架如下:
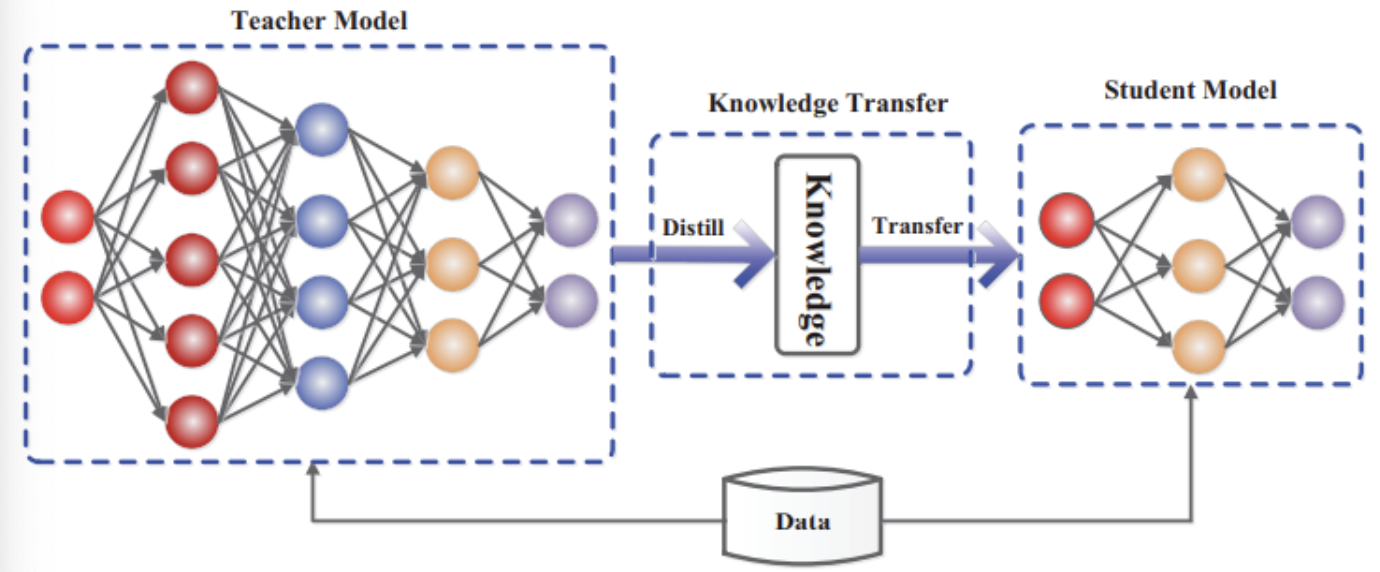
Distillation在一些简单的任务上通常有不错的效果:如分类;但是对于一些比较复杂的任务,如检测任务Distillation则不一定生效。因为Distillation的核心是通过Teacher Model的中间Feature来指导Studentnt Model的训练,使其能够更容易学习到一些高维特征。但是对于检测任务来说,其比较注重局部目标物体(bbox/class),特征更难学习。
MultiTask
MultiTask顾名思义是将多个Task合并为一个Task,是一项实践过程中较为常用的技巧。通常对于一些关联性较强的任务(如检测人体的多个部位),可以通过MultiTask的方案进行合并,即基本的网络设计如下:
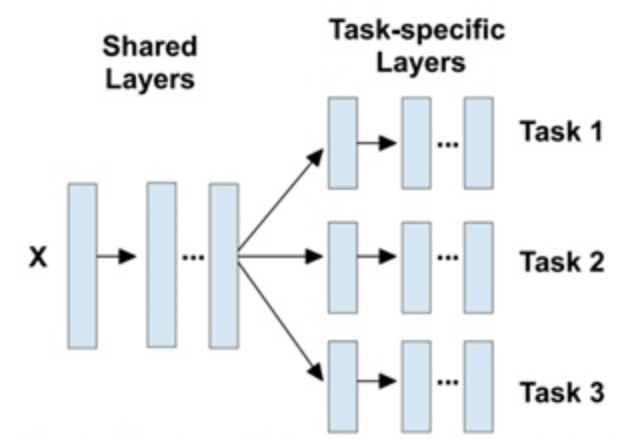
个人理解,MultiTask的核心在于共享前置层的基本特征,通过采用不同branch的方式实现不同Task的实现(不同Task属于较为接近的Task)。对于分类Task来说,最简单可以采用不同的fc层来实现不同task的分离,对于检测,因为只对backbone进行参数共享,所以需要对后置的anchor generator以及Det-head进行不同的配置。细节层面,在训练时需要解决不同类型数据只对对应的branch参数进行梯度回传。通常task越多,性能下降越多,往往需要进行task的combine操作(即减少总的branch,而增加单个branch的Task数目)。
量化
模型的量化一般是真实模型部署场景不可获取的一个环节:通常模型训练的时候为了减少精度损失,通常基于FP32精度(或者混合精度)训练,但是基于FP32精度的模型通常占用存储,运行效率也偏低,在移动端的部署上就会显得力不从心。 该需求背景下,量化便应运而生了。量化意义在于能将FP32数据转化为低精度数据(常见如INT8)。因为模型推理过程中,模型的权重都是固定的,且对于收敛较好的模型INT8数据类型通常能够表达FP32数据的大部分输出范围,从而保持比较好的精度。 目前业界最常用的便是NVIDIA TensorRT的量化方案:8-bit Inference with TensorRT。其核心原理是将原始FP32的各层的激活值通过INT8进行表达:转换为基于 KL-divergence 的最优化问题。当然大部分情况是无法无损映射的,通常会有一定的精度损失(尤其是边界值)。
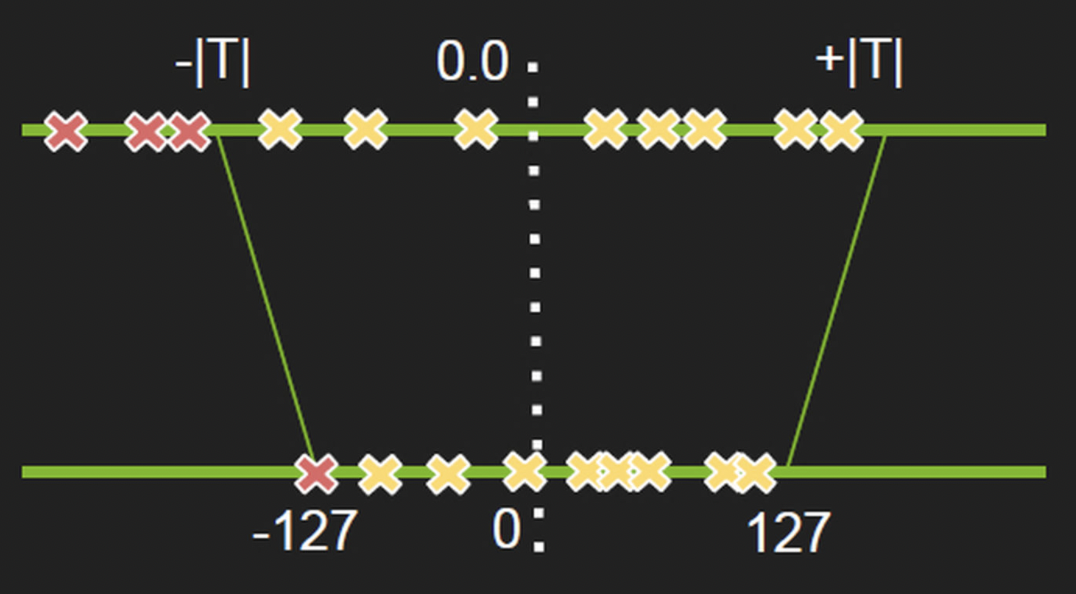
TenRT会通过校验集来优化上述环节,校验集可以认为是真实场景的一个子集,可以基于此维持在真实场景尽可能高的精度。其基本流程如下:
- 基于校验集数据得到各层的激活值直方图
- 基于不同阈值产生不同的量化分布
- 基于每个分布和原始分布的相对熵,然后选择熵最少的量化阈值
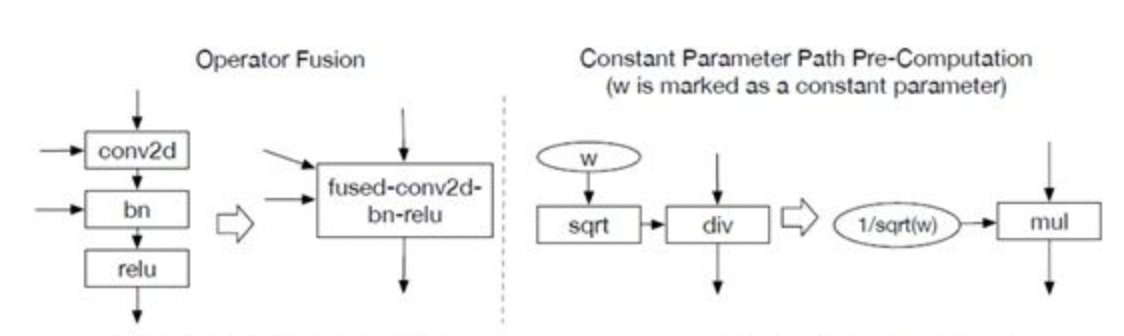
算子/图融合
深度模型的推理通常是基于计算图来实现网络结构的表达,即算子和网络结构通过计算图中的节点和图关系来进行表达。通常来说,算子复合度对模型的计算性能影响是正相关的,即算子的复合度越高,其模型的计算性能也是越高的;但是算子复合度越高,其表达能力越差,简单来说,原本很多小算子可以通过不同的组合构建复杂多变的网络结构,但是当这些小算子合并为几个大算子,那其表达能力就会下降。
所以,通常来说,构建模型以及模型训练过程中,通常都是基于复合度低的算子来实现多样的模型的,但是在实际推理的过程中,由于模型的结构和权重都是固定的,那么就可以通过提高算子的复合度来提高模型的性能,即算子/图融合。 算子/图融合通常和底层硬件相关,如GPU的CUDA算子库中便集成了大量的图算融合的逻辑来加速模型的推理;另外其他硬件如NPU(如HUAWEI的Ascend系列)也各自开发适应其自身的图算融合算法。 图算融合的核心是将一些可以连续/并行计算的算子通过融合算子或者优化底层计算逻辑来实现性能优化,最常见的算子融合的样例便是Conv+BN的合并,其合并原理为:训练后的BN参数是固定的,相当于对输出数据进行线性运算,而该线性运算是可以在卷积操作中实现。
当前一些流行的AI编译器(如TVM)便会基于各种硬件后端生成优化规则,对模型进行优化操作。TVM主要通过支配树(Dominator Tree)来实现算子融合,其基本策略是从各节点出发,确认其和支配点Node是否符合融合规则(pattern),如果符合则将这些节点替换为融合算子。