目录
RoarNet: A Robust 3D Object Detection based on RegiOn Approximation Refinement
论文背景以及基本思想
出发点:思想类似于F-ConvNet,认为直接通过2D图片得到3D proposal是不准确的,还可能受不同传感器间的时间不同步的问题,所以提出spatial scattering来对proposal区域进行扩充。
算法基本流程
算法思路:
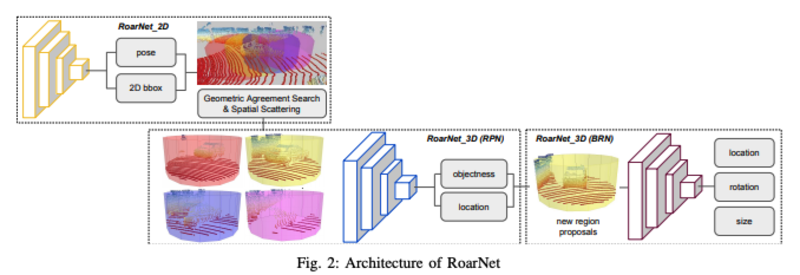
RoarNet的整体思路与F-PointNet以及F-ConvNet有点类似。先通过2D的RGB图片通过2D detector进行ROI的提取,但是本文设计的RoarNet在提取ROI之后通过Det+Pose CNN网络进一步进行3D空间内的3D box的预测,得到了一个粗略估计的3D Box。
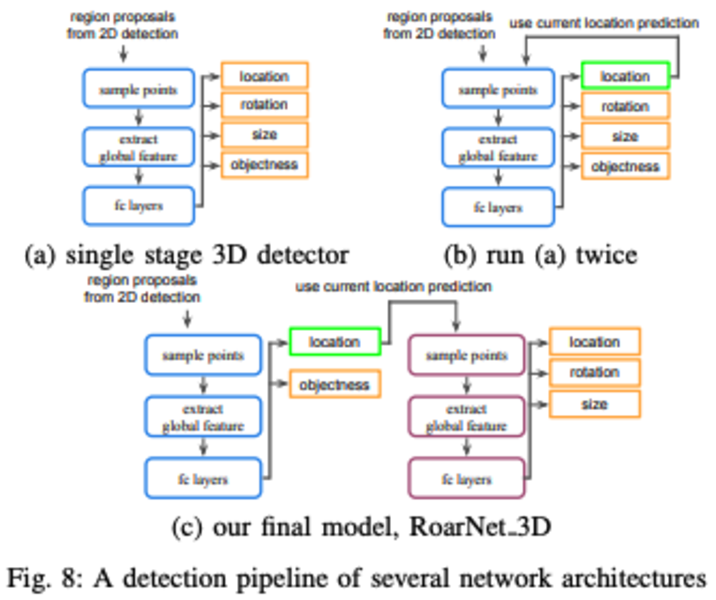
因为直接由RGB图估计得到的3D位置不精确,作者通过Spatial scattering的方式(对得到的prediction box进行一定的缩小和放大,从而得到一系列远近大小不同的box 估计,类似于F-ConvNet的视锥)。之后提取这些Proposal的点云数据(sample 256 point clouds for training, 512 for prediction)进行最终3D box的位置的预测。不同于F-ConvNet的run twice操作(文中证明这样也是有性能提升的),本文采用的方式是利用两个结构一致的Poinet简化网络,先对3D box进行location和objectness的估计,再进行location的精调以及rotation和size的估计
算法框架:

核心点:
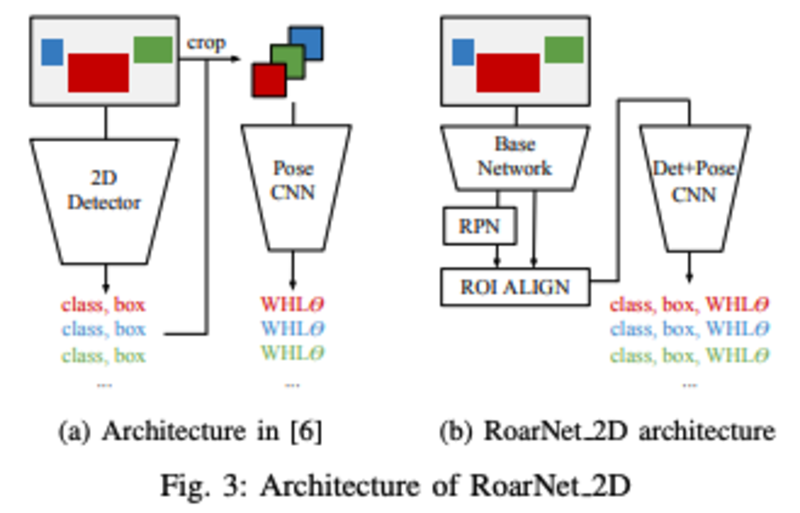
- 设计了RoarBNet_2D进行图片内所有物体的2D_box和pose的粗略估计
- 通过投影关系和spatial scattering进行3D propasal的获取和扩充
- 通过two-stages的Point-Net进行3D box的回归和预测
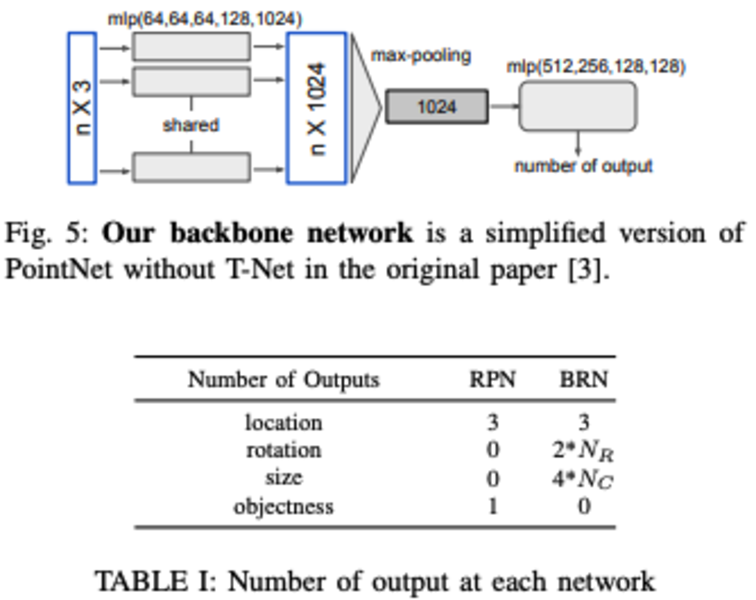
算法细节
- 关键点:
- 进行了前置2D detector的设计
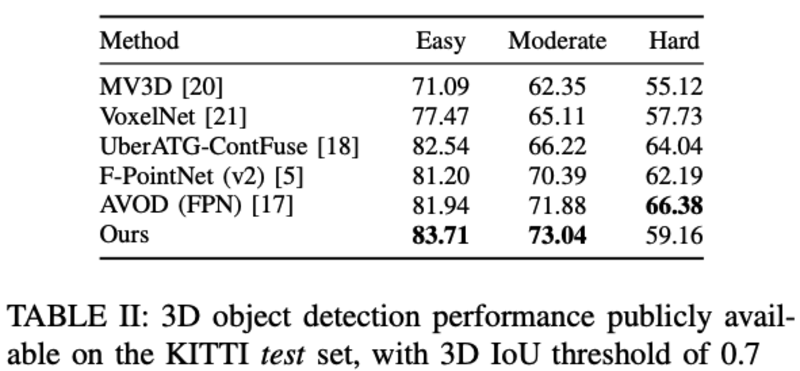
- 验证了3D点云的位置预测采用two-stage方式效果更好
- 三种方式的AP:54.3%,59.9%,74.02%:
- 三种方式的AP:54.3%,59.9%,74.02%:
- spatial scattering能够改善时间不同步带来的预测精度问题
- 实验结果: