前言
垃圾回收对于每一门语言来说都是至关重要的,其核心功能是进行“内存管理”,防止”内存泄漏“,所谓”内存泄漏”指的是:程序未能释放已不再使用的内存,通常是因为程序设计上的问题,导致程序失去了对使用过的内存的控制,导致了内存的浪费。 本文重点梳理下 Python 下的垃圾回收机制。
垃圾回收方法
Python 中最常用的是 计数引用 的机制: Python 中一切都是对象,所有的变量都是对象的引用。因此,最直观的想法,便是通过对象的引用计数来进行垃圾回收: 当一个对象的引用计数为0时,说明这个对象不可达,需要被回收 简单用例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
########## 输出 ##########
2
4
2
Python 也可以采用手动进行垃圾回收: del a + gc.collect() ,如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import gc
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
print(a)
########## 输出 ##########
initial memory used: 48.1015625 MB
after a created memory used: 434.3828125 MB
finish memory used: 48.33203125 MB
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-12-153e15063d8a> in <module>
11
12 show_memory_info('finish')
---> 13 print(a)
NameError: name 'a' is not defined
当然,在 Python 中,引用次数为0不是垃圾回收启动的充要条件,原因是: 循环引用 。即函数内,a和b如果互相引用,当函数调用结束后,a/b从程序意义上看,不存在意义,应当被消除,但是实际上这种情况下,内存依然占用,需要手动释放:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import gc
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
show_memory_info('before collected')
gc.collect()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 49.51171875 MB
after a, b created memory used: 824.1328125 MB
before collected memory used: 824.1328125 MB
finished memory used: 49.98046875 MB
显式调用 gc.collect() 可以清理内存,可以看到 Python 下垃圾回收机制除了“引用计数”外还存在其他方式:
- 标记清除(mark-sweep) 标记清除采用的是算法是:单节点出发进行遍历,标记所有可达的节点;遍历结束后,得到所有未标记的节点,作为“不可达节点”。最后,对这些“不可达节点”进行垃圾回收即可。具体实现层面,”Python“采用了一个双链表来实现,且只考虑容器类的对象(只有该对象才存在循环引用)。
- 分代收集(generational) 分代收集在于优化,核心是优化垃圾回收手段。其实现方式:将对象分为三代:刚创立的为0代,每经过一代,则将当代仍然存在的对象移动到下一代。而每代对象的垃圾回收阈值是单独指定的。当来垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这代对象启动垃圾回收。 其设计出发点是:新生的对象更有可能被垃圾回收,而存活越久的对象也有更高的概率继续存活。该方式能够节约计算量,提高Python的性能。
内存泄漏调试
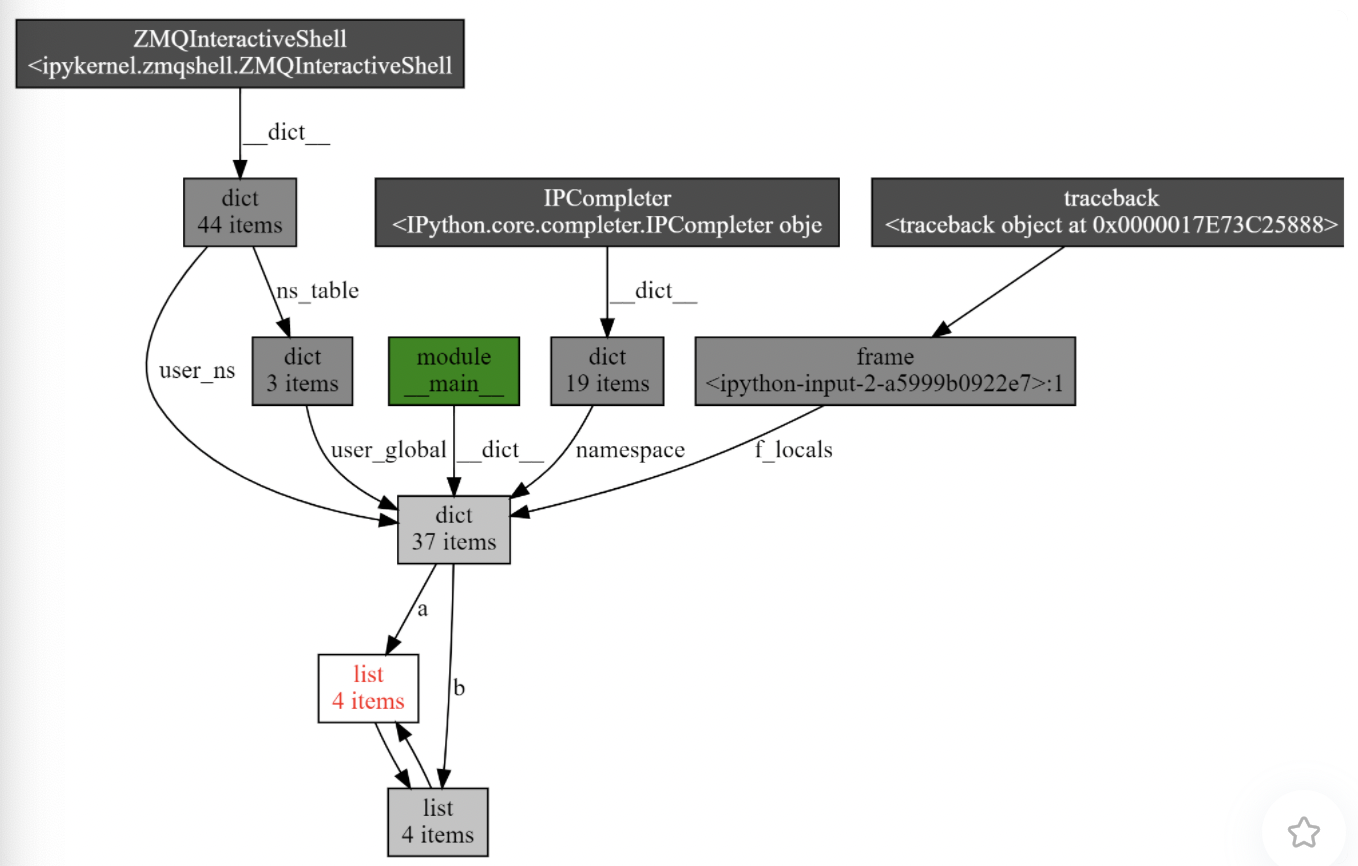
介绍下调试内存泄漏的工具:objgraph 方便可视化引用关系的包: show_refs() 可以生成清晰的引用关系图。如下文,可以看到清晰的互用引用关系图:
1
2
3
4
5
6
7
8
9
10
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])
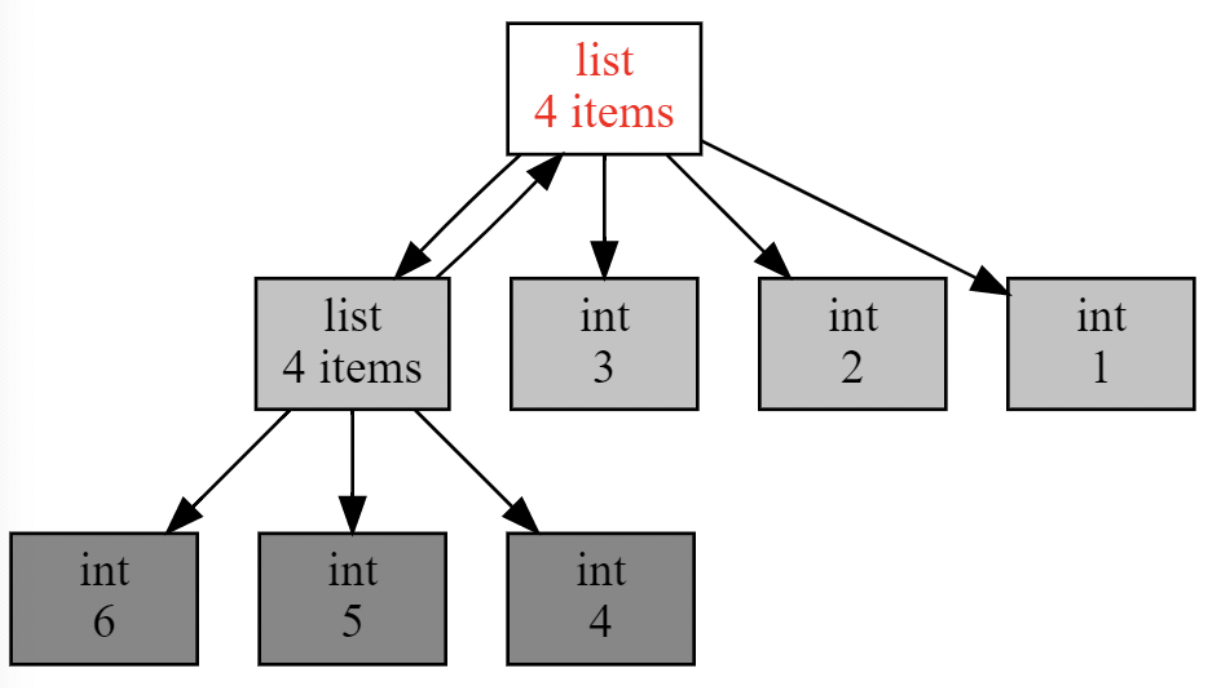
show_backrefs() 同样可以生成前后引用关系图:
1
2
3
4
5
6
7
8
9
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_backrefs([a])