Prefill Decode分离部署
Background
Prefill和Decode两阶段的计算Pattern完全不一致:Prefill属于计算密集型任务,Decode属于IO密集型任务。
Prefill和Decode混跑情况下,Prefill会打断Decode推理,无法更好的Batching,Decode的Batch数上限降低,几种混跑的策略如下:都存在一定问题:
- Request-level:Request之间queuing时间很长;
- Continuous:Prefill影响Decode的推理启动,导致TTFT时间过长;
- Mixed:混跑导致部分decode阶段时延延长。
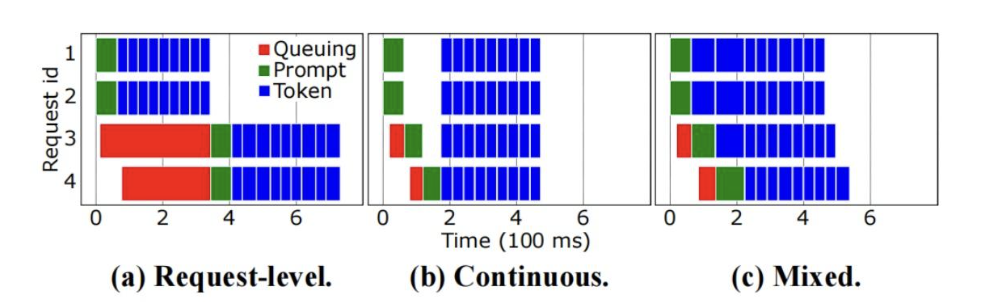
Motivation
PD分离部署的目的在于Prefill和Decode任务在不同的机器/集群上进行部署,中间依赖的$KV_Cache$通过$KV_Transfer$来传递。
PD分离的收益评估:
收益评估:$Bandwidth = \frac {QPS \times KVCache} {TTFT}$,
参考RoCE带宽25GB/s,1.9 G KV Cache时延40ms,对带宽要求可控
工程收益:
Prefill/Decode业务/工程可以分离优化,Prefill侧做Prefix-Cache/PP切分等;Decode专注做大BS推理,做好KV_Cache/Inference流水,schedule优化
硬件成本:方便做异构集群部署,充分发挥硬件算力
FrameWork Design
PD分离框架设计的几个核心点:
Sheduler
SPlitwise设计了
CLS(Cluster-level scheduling)和MLS(Machine-level scheduling)。CLS基于request负载和token分布来动态调整prefill/decode机器,同时基于Request routing来分配prompt/decode机器。MLS基于FCFS(first-come-first-serve)来进行单机器的request的schedule。Mooncake设计了
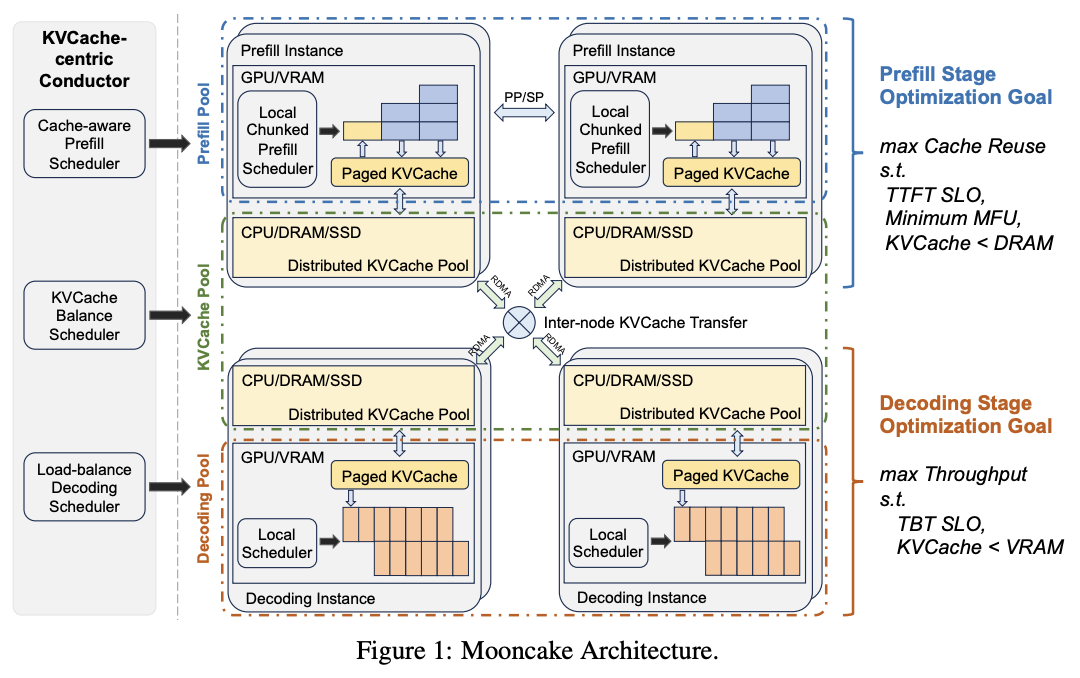
KVCache-centic Conductor来完成基于KVCache为中心的Scheduler,主要解决以下几个问题:Prefill Global Scheduling
Prefill的选择考虑几个因素:prefix cache的load/hit长度,可复用的
KVCache blocks。基于Cache-aware的思路结合prefix-cache下的prefill时间来进行prefill instance的分配。Cache Load Balancing
核心是希望尽可能提高
KVCache命中率的同时,降低load/transfer cache的时间,需要在重计算/remote cache/local cache间进行最佳策略的选择。

分布式部署
PD分离的一个优势是Prefill和Decode可以采用不同的部署方式。主要在于Prefill部署可以更加灵活,如:QPS需求低,latency要求高的时候,可以采用TP的方式;QPS需求高的时候可以采用Chunkprefill+PP的方式。
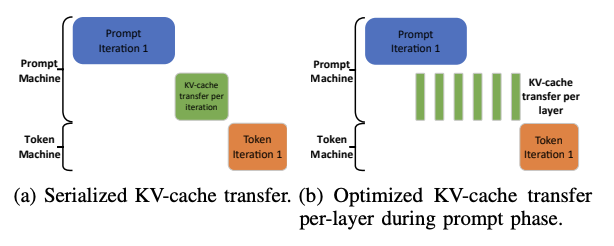
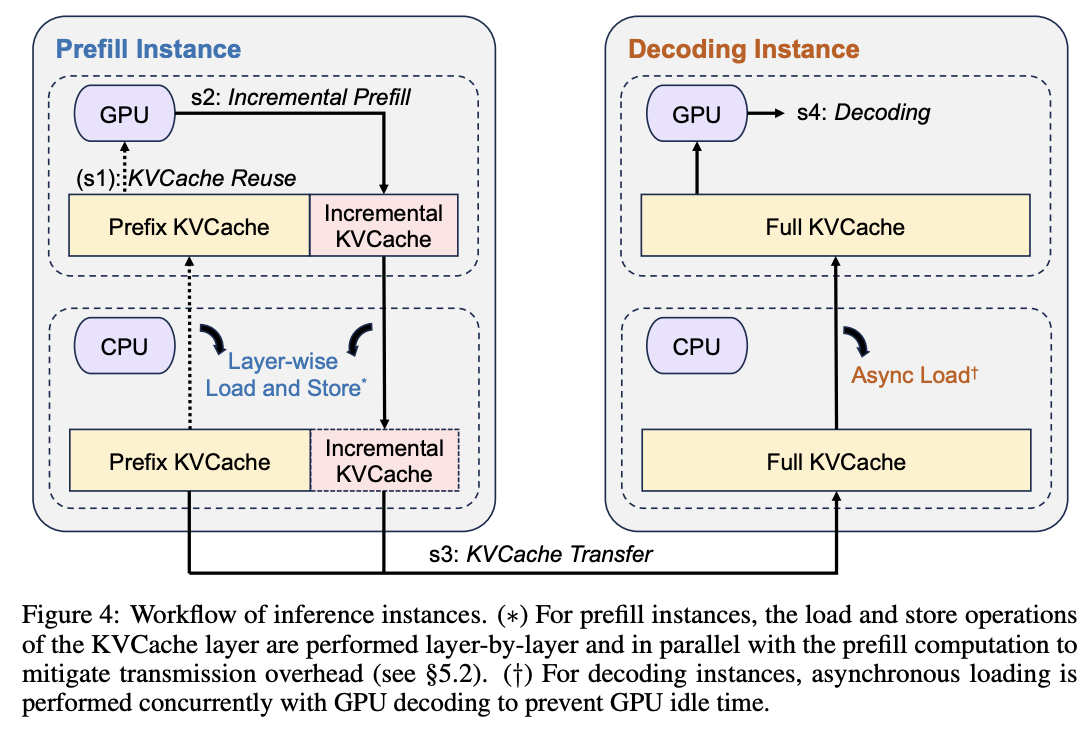
KV_Cache Transfer
KVCache分离部署核心需要解决高Cache命中和Cache流水掩盖的冲突,需要考虑:
- 分布式KVCache集群设计:多级存储,HBM/DRAM/SSD
- 调度设计:基于Cache-Match分配Prefill/Decode节点,通过Page方式管理
KVCache Block灵活复用。 - KVCache Transfer: prefill->decode,per layer异步传输
Reference
https://zhuanlan.zhihu.com/p/8056351077
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
Splitwise: Efficient Generative LLM Inference Using Phase Splitting