PP&&TP LLMs部署
训练场景,并行策略有DP/TP/PP/EP等策略,也有不同并行策略的组合,以及Zero等OffLoad的策略。
对于推理而言,最常用的是TP/PP策略。 TP最常用的策略主要在MLP/Self-Attention(num_head切分)进行切分,整体为:col-spllit->row-split->all-reduce。
从参数量上看,单卡的权重为$\frac {1}{TP}$,计算量上为$\frac {1}{TP}$,激活值为$\frac {1}{TP}$,但是由于输入为完整的seqlen,所以KV_Cache为完整的,通信量上看是 $2 \times b \times s \times h + 2 \times b \times s \times h$ ,通信量比较大,所以一般需要较大的通信带宽。

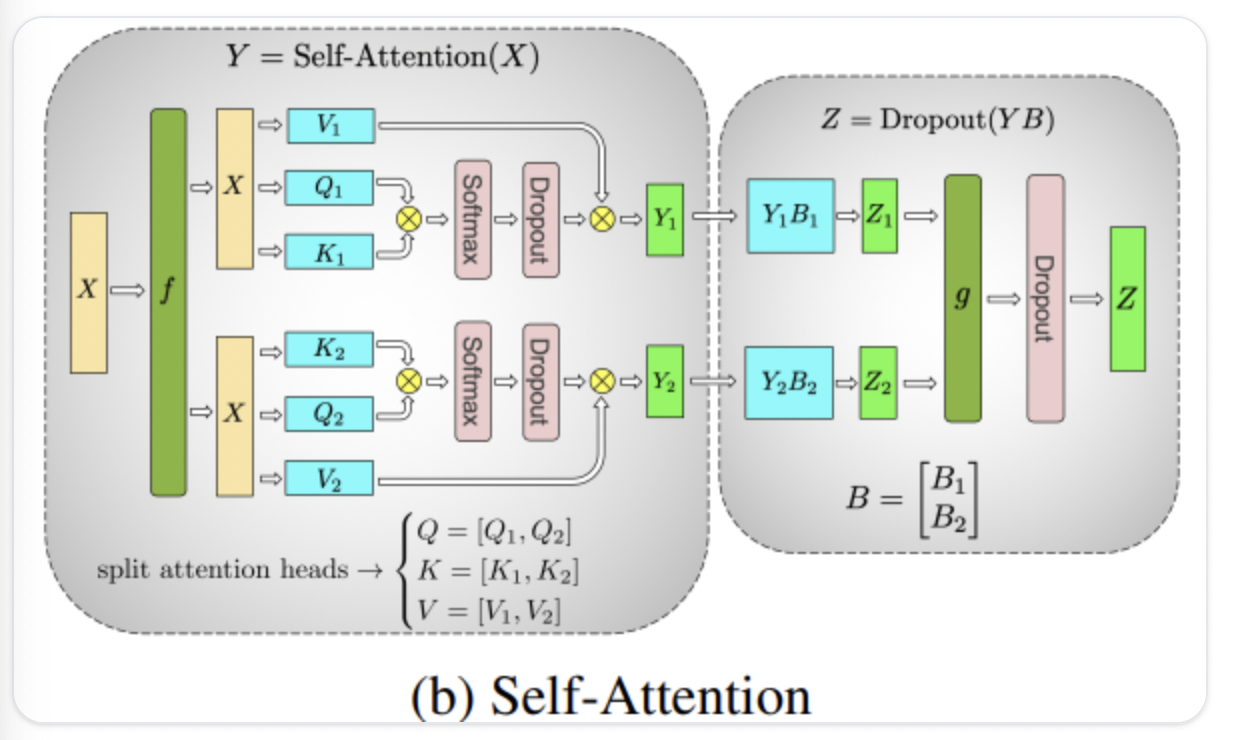
PP的切分策略比较简单,通常按照Transformer-Block进行切分(num_layers/pp_world_size),不同Block之间通过send/recv通信,且由于推理过程中仅涉及forward阶段,所以PP的Bubble现象也不显著:需要保证不同卡间TransforBlock计算的均衡。从参数量上看,单卡的权重为$\frac1{PP}$,计算量为$\frac {1}{PP}$,激活值为$\frac1{PP}$,KV_Cache为$\frac1{PP}$;通信量上是 $b \times s \times h$ 。
Micro-Batch 将一个大的批次(Global Batch)分解为多个小批次,并以流水线的方式分批传递。每个设备在处理一个小批次的同时,可以接受另一个小批次的数据,形成并行执行,可以降低PP的Bubble:
