Orca-Continuous Batching策略
Paper
Orca: A Distributed Serving System for Transformer-Based Generative Models
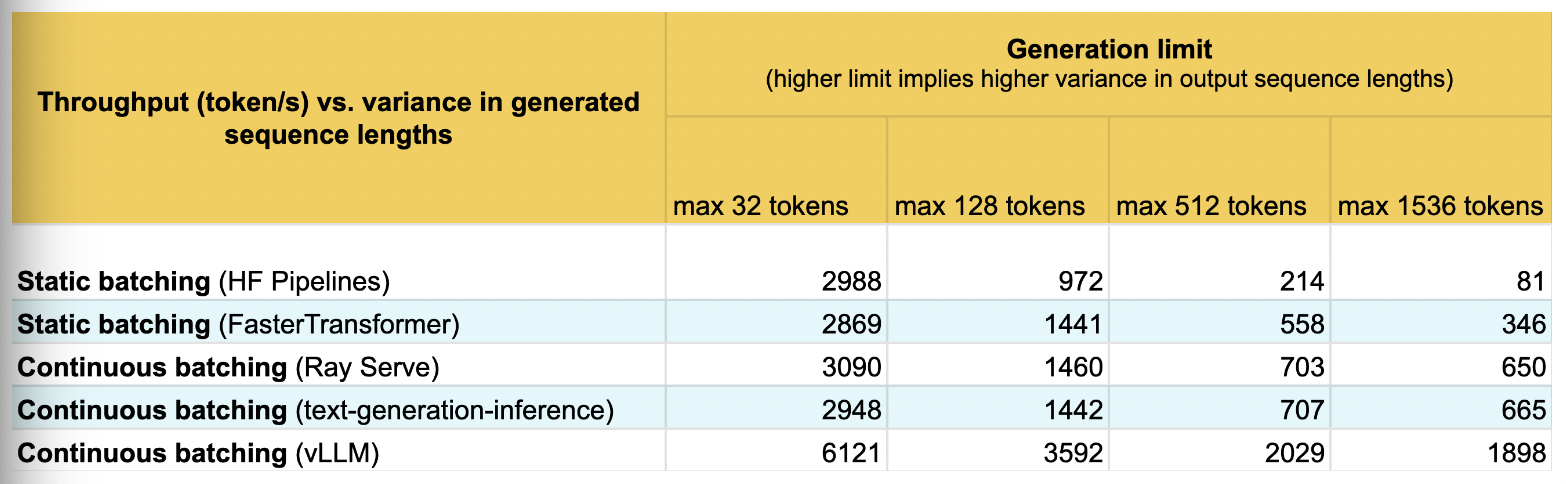
LLM推理主要氛围Prefill/Decode阶段,其中Prefill阶段为Compute Bound,Decode阶段为Memory-IO Bound,意味着需要充分利用显存的数据带宽。但是由于显存的限制,如A100-40GB而言,以13B模型为例,权重为26GB,其消耗单个Token的显存约为1MB(激活值/Cache等),则当Seq长度为2048时,仅能支持7 batch的推理,此时算力利用率很低。为了提高算力利用率,一方面可以通过量化手段减小显存,也可以通过优化FlashAttention等算子实现减少Memory-IO,另一方面也可以从Schedule层面通过Continuous Batching手段来提高Batching效率。
Motivation
传统的 static batching 如下: 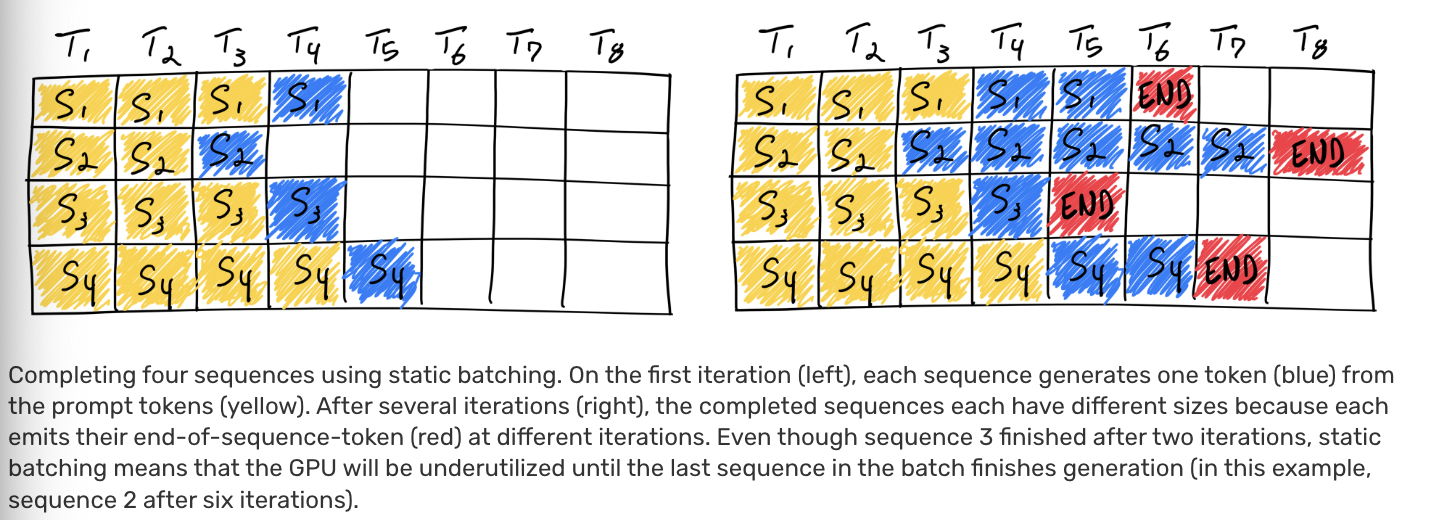
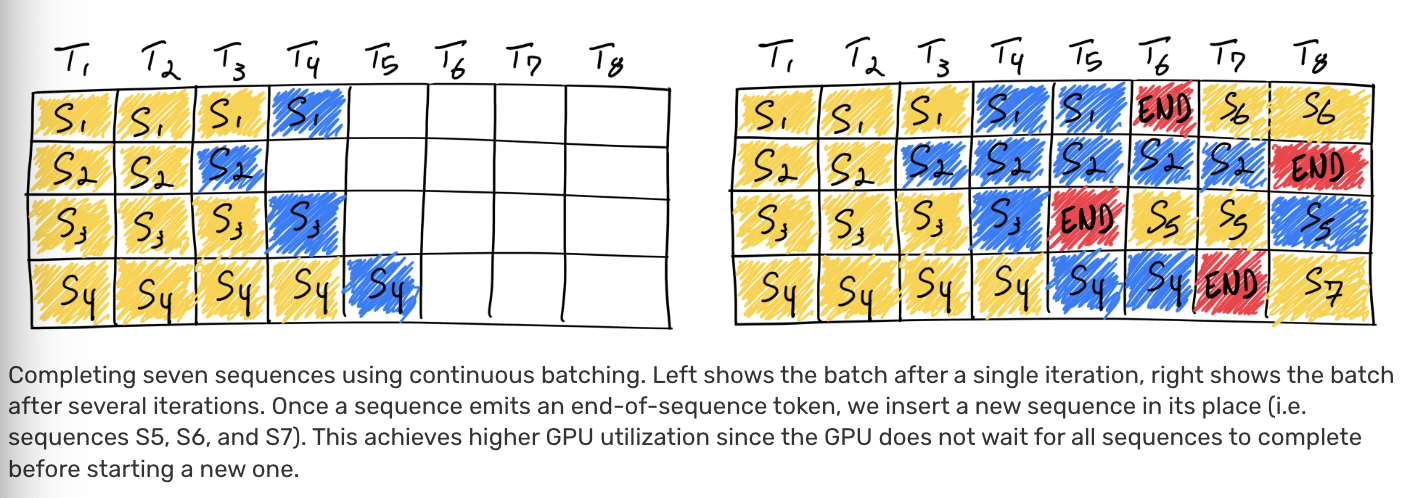
显然,由于不同batch的out_token数目不一致,1,3,4batch存在empty slots,意味着一段时间内,只有batch 2单batch在计算。Continuous batching采用来iteration-level的调度策略:
KeyPoints
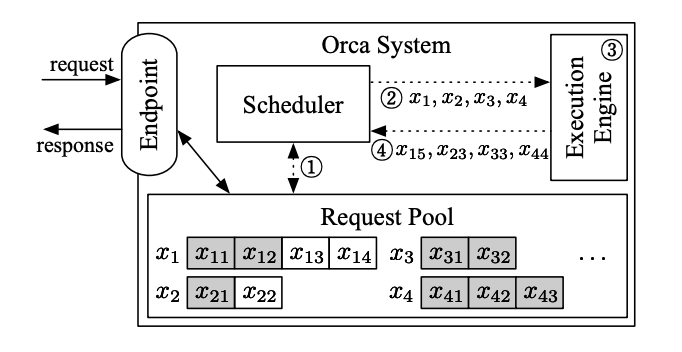
ORCA的核心思路在于iteration-level scheduling和selective batching。
iteration-level scheduling:通过在每一次iteration中,动态调整任务执行顺序。可以通过任务优先级情况、微批次流水来提高硬件利用率。
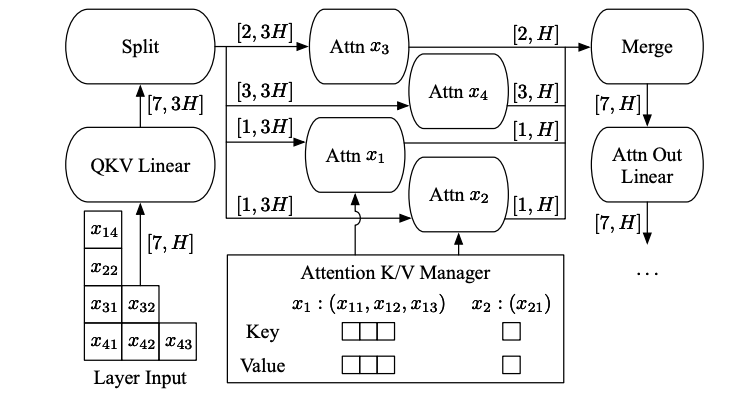
selective batching: 模型输入的shape为$[B,L,H]$,non-Attention算子,如矩阵乘、LayerNorm等算子支持$B \times H$合并,但是Attention算子需要分离$B,L$两维。selective batching通过Attention前后Split/Merge的方式来进行维度处理,从而支持ORCA的动态Batching。
Statistics