目录
前言
SSD作为One-Stage系列的论文,如今已经作为基本网络被广泛应用于物体检测中,也很多网络结构是建立在其基础上的改进网络。 当前的Objection Detection架构的两个派系:
- Two-Stage:基于Region Proposal和CNN网络分类回归方式:RCNN->SPPnet->MulriBox->Faster RCNN,该方案的优势在于检测精度高,但是计算量大,实时性差。
- 滑窗方式:没有Region-Proposal的过程,直接通过Bounding-Box和类别confidence的估计:OverFet->Yolo->SSD
论文基本信息
作者信息:
- 一作:
WeiLiu, UNC Chapel Hill在读PhD - 通讯:
Alexander C. Berg, UNC Chapel Hill AP, SHapagon CTO, 引用2.7k
论文背景以及基本思想(Motivation & Contribution)
简述其他框架:简述two-stage的RCNN系列和one-stage的YOLO系列。
RCNN:Region-based Convolution Neural Network,主要包括三步:Selective Search找到Region Proposals(大约2000),在每个region上面运行CNN,将每个CNN的输出结果接入到一个SVM进行分类以及一个线性回归进行bounding box的回归Faster-RCNN:先了解Fast RCNN:Fast RCNN先对输入图片导入一个CNN网络得到feature,再在feature的基础上通过Proposal method得到Regions,采用了ROI Pooling,fc之后以Softmax层替代SVM,Linear回归得到box,除了前置Region Proposal的提取过程外,其他部分都能实现端到端的训练。Fater RCNN在Fast RCNN的基础上,以RPN替代了Proposal method,将得到的ROIS和CNN得到的features接到ROI Pooling和若干全连接层,最后通过softmax分类和bounding box回归得到框,实现了整体网络的端到端训练。YOLO:YOLO采用的是One-stage的检测方式,将目标检测认为是一个回归问题。Yolo的CNN网络将输入 图片分割成S×S网格,然后每个单元负责检测落在该格子内的目标,每个单元会预测B个预测框,以及边界框对类别的置信度。通过前期各层的卷积层输出得到特征图,最后接到两个全连接层,经过reshape得到之前网格的框图预测输出。- SSD的改进思路:SSD避免了采用Faster RCNN的结合RPN和Fast RCNN的方式,而是通过一系列设定得到的boxes对应不同尺度的feature图,实现了end-end的网络结构,使得模型的训练更为简单,模型检测速度更快。相对于YOLO,SSD更加灵活地运用了default boxes(不同大小,不同长宽比),在base网络后连接卷积得到不同尺度的feature图,能够结合不同scale的feature进行预测,对不同尺度的featue图直接通过卷积层输出进行训练和预测,同时用卷积方式替代fc,使得不同尺度下的检测精度更高。
算法基本流程
SSD算法框架: 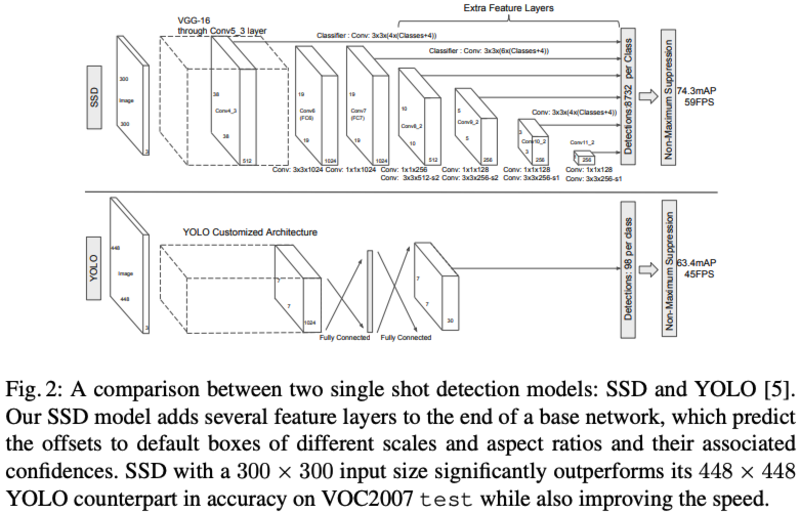
SSD模型主要分为以下几个部分:
Multi-scale feature maps for detection:backbone采用基础网络结构(VGG),本文修改了backbone的最后几层结构,同时引入了额外的卷积层用于抽取不同scale尺度的featureConvolutional predictions for detection:对于每个feature map(假设size为m*n*p),通过3*3*p的卷积核生成预测value,包括预测位置的相对值(相对feature map像素对应的原图位置)以及confidence等Default boxes and aspect ratios:每层的feature map设置有默认大小和长宽比的default boxes,feature map上的每个位置会基于deafault box作相对位置和大小的估计以及类别score的估计。对于size为m*n的feature map,其最终的预测结果为(c+4)kmn,其中c为类别数目,4为位置偏移值和大小偏移值,k为default box数目(不同scale的feature map的k值有所不同,如conv10_2和conv11_2采用k=4,余下为6)。
算法细节
Traing
Matching strategy:区别于MultiBox,SSD对所有与GT的IOU阈值大于0.5的default box作为positive,即default box与GT是多对一的关系,而不是MultiBox的取最大IOU的一对一的关系- Loss设计:Loss主要分为两个部分:
localization loss和confidence loss:
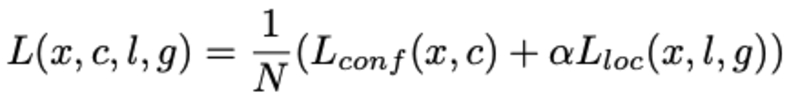
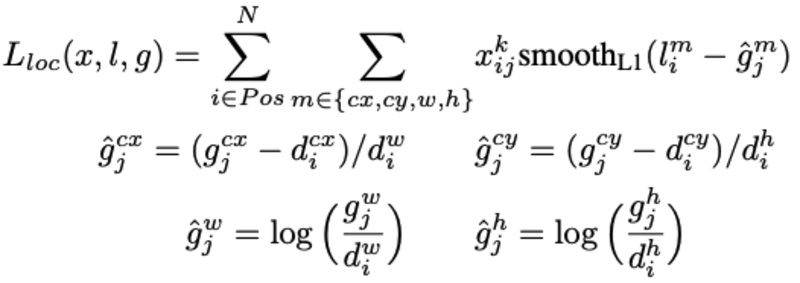
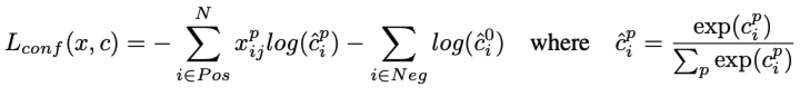
其中,N为匹配上的box数目,如N=0,则loss=0。localization loss采用的是L1 loss,localization loss包括(cx,cy,w,h),即中心位置和宽,长四部分loss,confidence loss采用的是softmax loss。
- Choosing scales and aspect ratios for detection:不同尺度的ferature map拥有不同的感受野,所有应当设计不同大小的default box。SSD采用的default box大小设计如下:
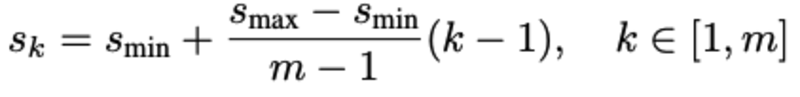
其中,s_min为0.2,s_max为0.9,长宽比设计为a_r={1,2,3,1/2,1/3}
Hard negative mining:策略为按照confidence loss进行排序,保持正负样本为1:3。Data augmentation:采用的ramdom crop策略:- 输入原始大小的输入图片
- 在输入图片上进行Sampel得到patch,满足与objects的最小jaccard overlap为0.1,0.3,0.5,0.7 or 0.9
- 随机Sample得到patch
sample得到的patch大小为[0.1,1],长宽比为1/2,2,保留中心点在sampled patch的box。得到的patch会被resize到固定size,并且采用horizontally flip(probability 0.5),photo-metrix distortions等增强。
Base network:在VGG的基础上,进行了一系列的改动:fc6, fc7替换为卷积层,pool5替换2x2-s2为3x3-s1,同时采用空洞卷积,去除所有drop-out层和fc8层。
实验结果
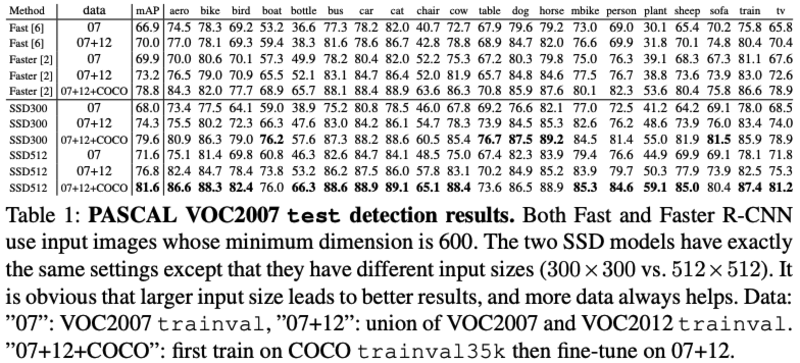
- PASCAL VOC2007 test detection results:SSD在大物体上性能很好,小物体上性能略差(因为物体过小的话,在前面的feature层也不一定有足够的信息),增大输入size能提升小物体性能。
- 模型各模块性能分析:

主要为以下三个结论:
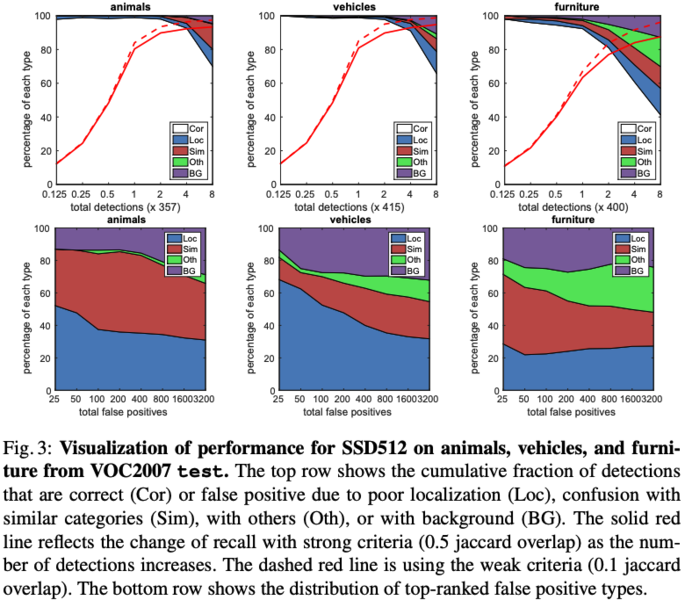
Data Augumentation:单就数据增强这一项提升了8.8mAP,作者认为faster-rcnn因为采用了feature pooling step,所以对数据的translation更鲁棒,所以数据增强对faster-rcnn的收益不打,这点需要存疑,因为random-crop的增强策略不单单是物体的translation的变化。More default box shapes:更多的aspect box的设计会涵盖更多的尺寸的的deafault box,有利于模型预测多尺寸的物体Atrous is faster:采用空洞卷积的方式能够在不降低性能的情况下,加快20%SSD512在animals,vehicles,furniture三类上在VOC2007上的性能:

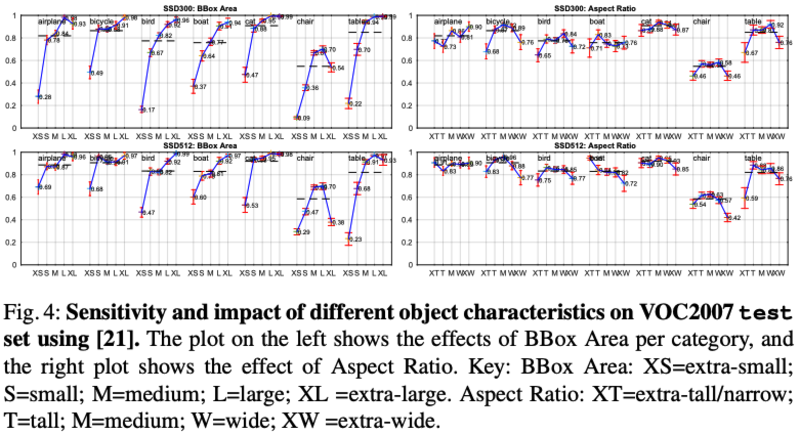
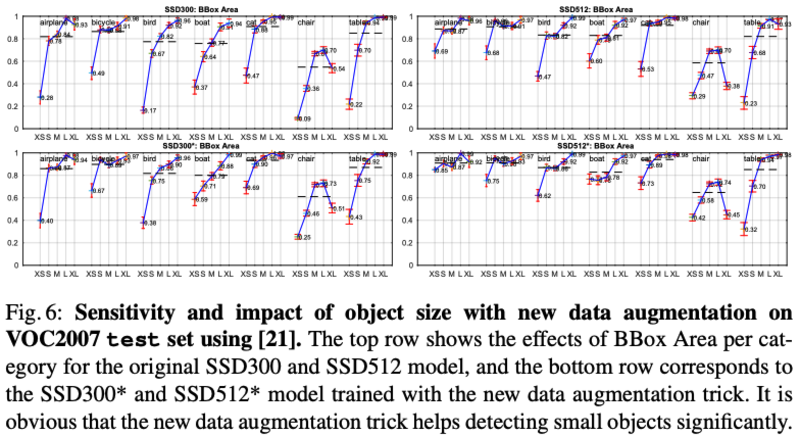
BBox尺寸对各类性能的影响:同一类的小物体性能明显较差
- Multiple output layers at different resolutions:在多尺度feature map上进行预测能够获得更好的性能,同时保留边界box性能会更好(在引入后续更高level的feature层后):

- PASCAL_VOC2012:结论与VOC2007上类似:
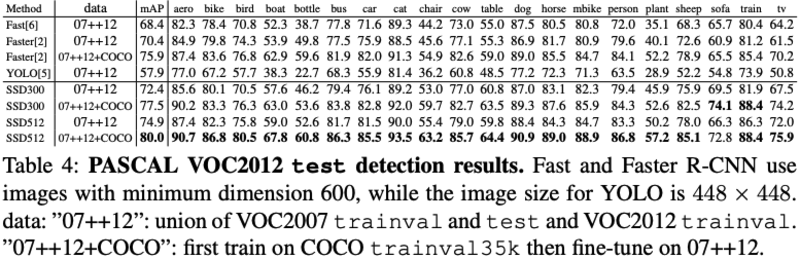
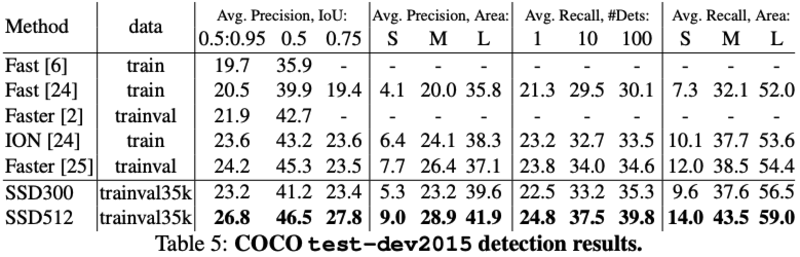
COCO:SSD这里采用了更小的default box尺寸,相比faster-rcnn来说,其在小物体上的性能略差:
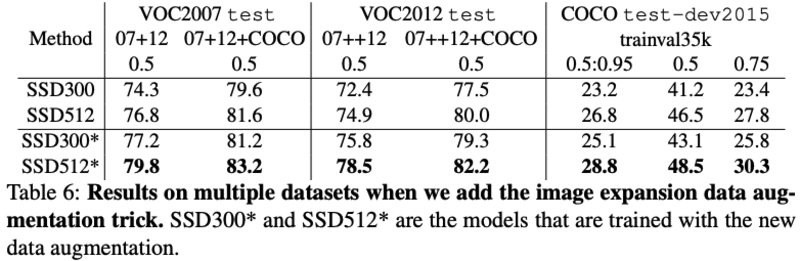
Data Augumentation for Small Object Accuracy:针对小物体,提出了”zoom out”的ramdom-expansion的增强方式:先将图片随机放置到16Xsize的画布上,再进行random crop操作,能明显提升小物体的性能:
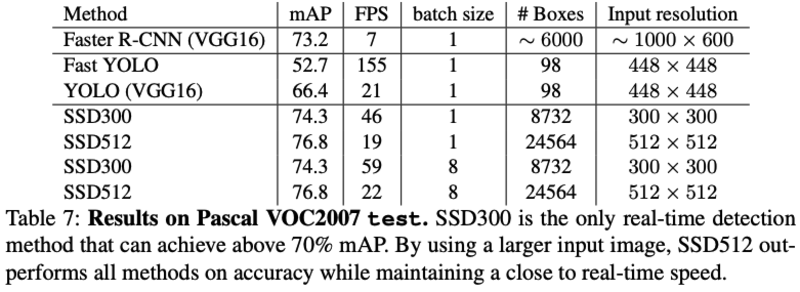
- Inference time:SSD在得到网络的prediction结果后需要进一步的NMS,耗时1.7msec per image for SSD300 and 20 VOC classes,模型整体Infer时间对比如下:
小结
整体上SSD的网络设计还是非常简单可行的,One-Stage的方案在模型精确度和速度上实现了比较好的Trade-off,multi-scale-prediction的设计是其主要的贡献点。但是,论文中的数据增强对模型的性能提升很大,认为可能是本身数据集数据量不足的影响,与没有作相关数据增强的Faster-rcnn进行对比稍微有点不公平.