MoEs(Mixed Expert Models)
MoEs最早由Switch Transformer提出,核心结构由稀疏MoE层和门控网络或者路由组成:
\[y = \sum_{i=1}^{n} g_i(x) \cdot f_i(x)\]其中:$n$为专家数量;$g_i(x)$为门控网络对第$i$ 个专家的权重;$f_i(x)$ 是第$i$个专家对输入的输出。
稀疏 MoE 层:
这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
门控网络或路由
门控网络通常是一个小型的神经网络,用于根据输入特征生成专家权重:输出$g(x)$的常用形式为$Softmax$。
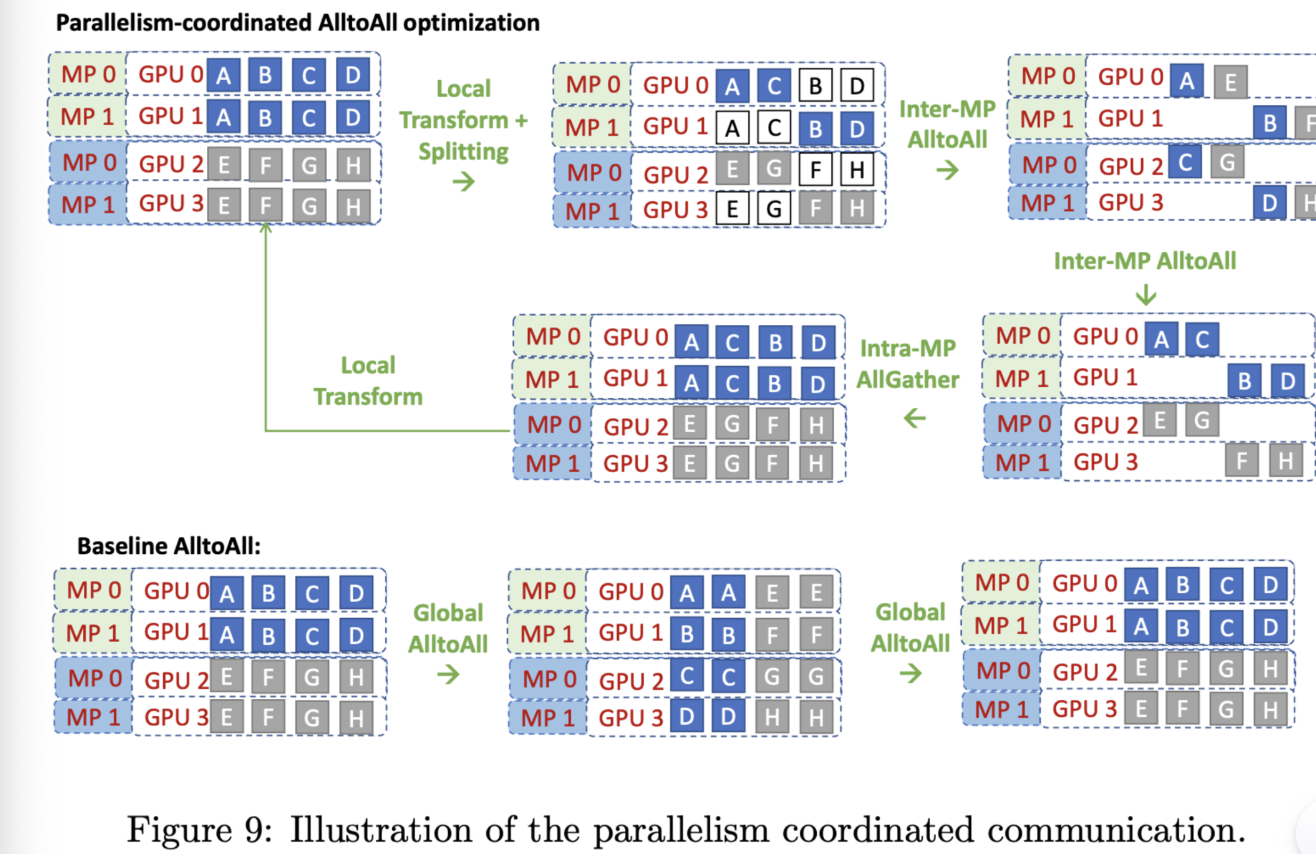
这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。

MoEs加速的问题在于:
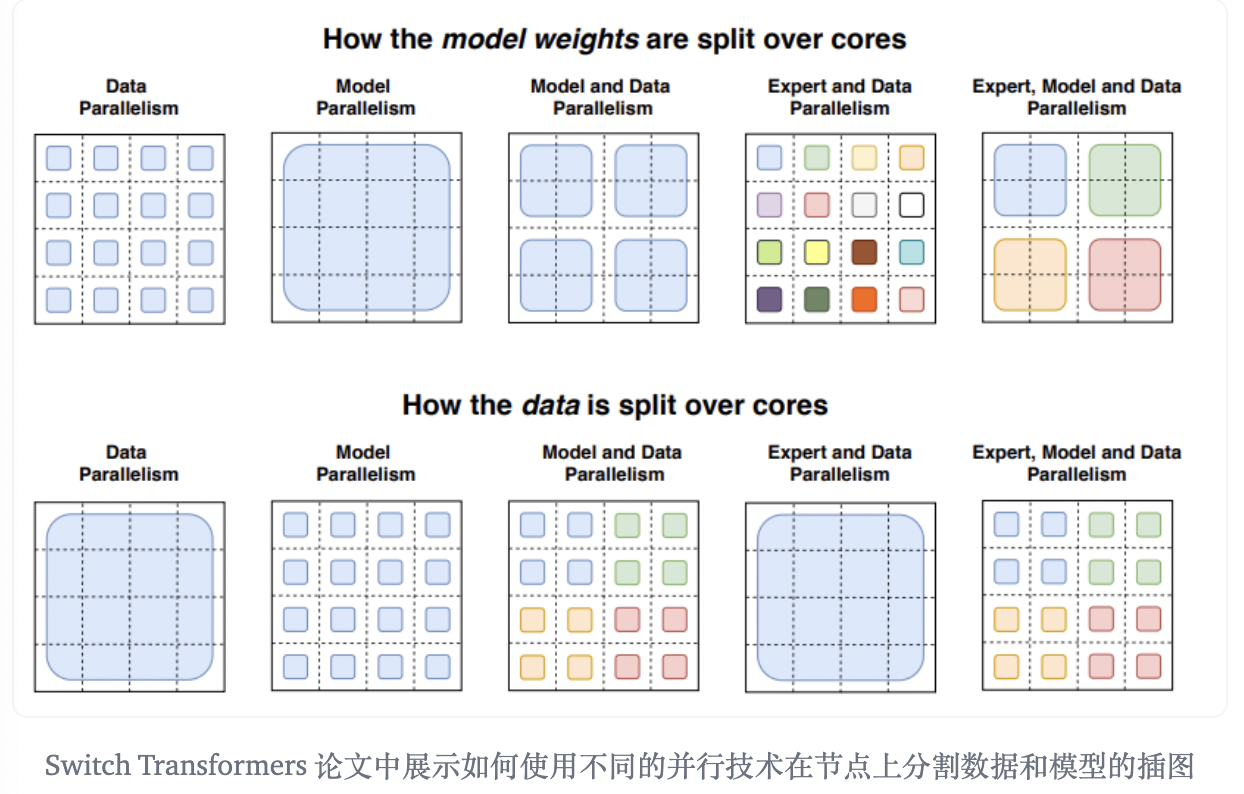
其本身的分支结构会导致计算效率低下,且由于Experts数目的增多会导致需要多卡/多机之间的分布式部署,从而引入额外的通信开销。对于MoEs模型,通常需要采用多种并行计算策略:DP/PP(MP)/TP/EP,且多种策略往往需要组合使用。
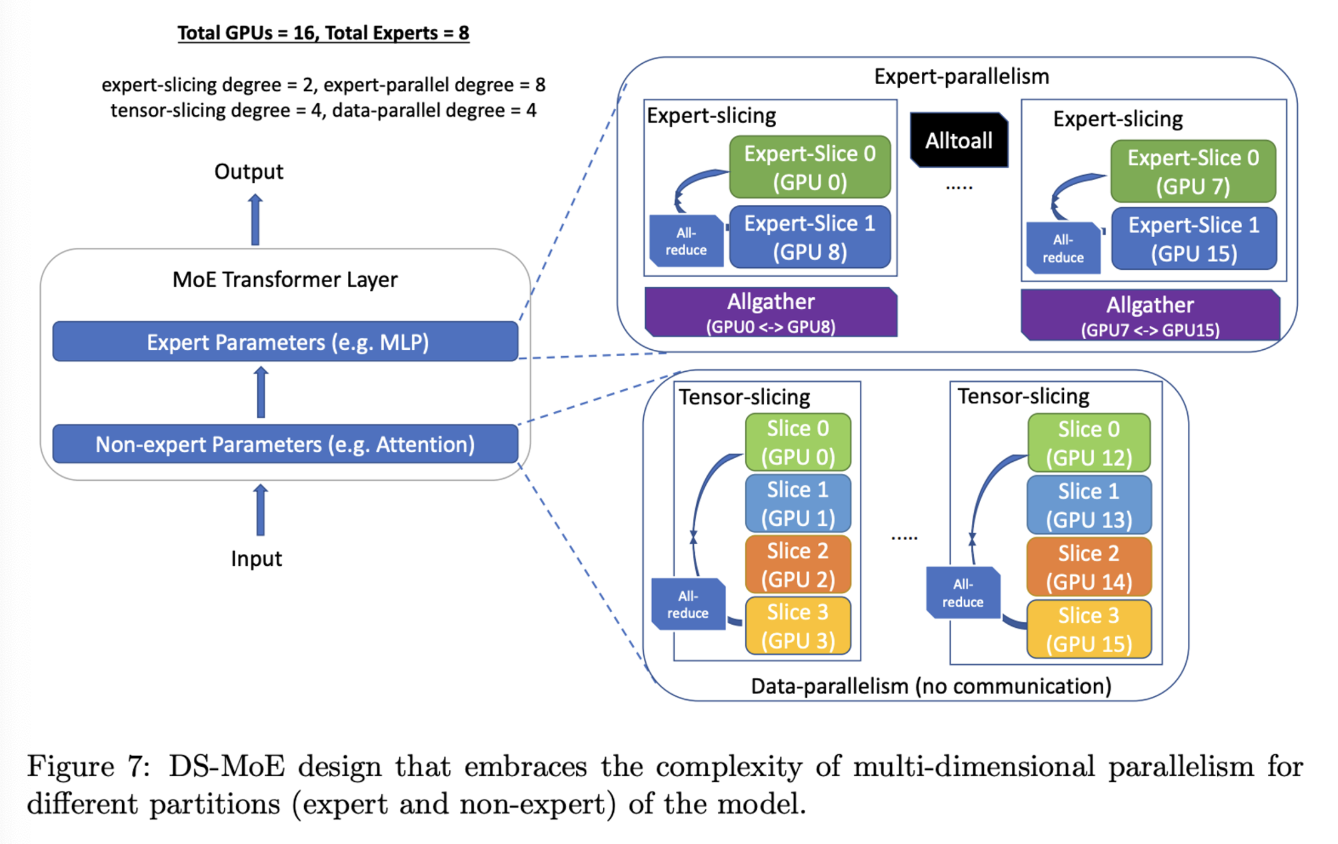
DeepSpeed的并行策略组合如下:下图是以单个 MoE 层为例解释了如何使用混合并行策略,假设总共有16 个 GPU,专家数量为 8 个,可以看到并行模式是针对专家和非专家模块分别设计的,具体如下:
- 对于非 expert 参数模块:
- 使用4 路数据并行,也就是说该部分参数复制了 4 遍
- 每一路数据并行的内部采用 4 路的tensor 并行
- 对于 expert 参数模块:
- 使用 8 路专家并行
- 每个专家通过 2 路的 tensor 并行进行参数拆分
同时,TP/EP间也可以做通信优化:核心思路是TP的输入/输出数据是一致的,不需要做all-to-all通信,能够节省EP的通信开销: