Lora&&Multi-Lora
Paper
MULTILORA: DEMOCRATIZING LORA FOR BETTER MULTI-TASK LEARNING
S-LoRA: SERVING THOUSANDS OF CONCURRENT LORA ADAPTERS
Motivation
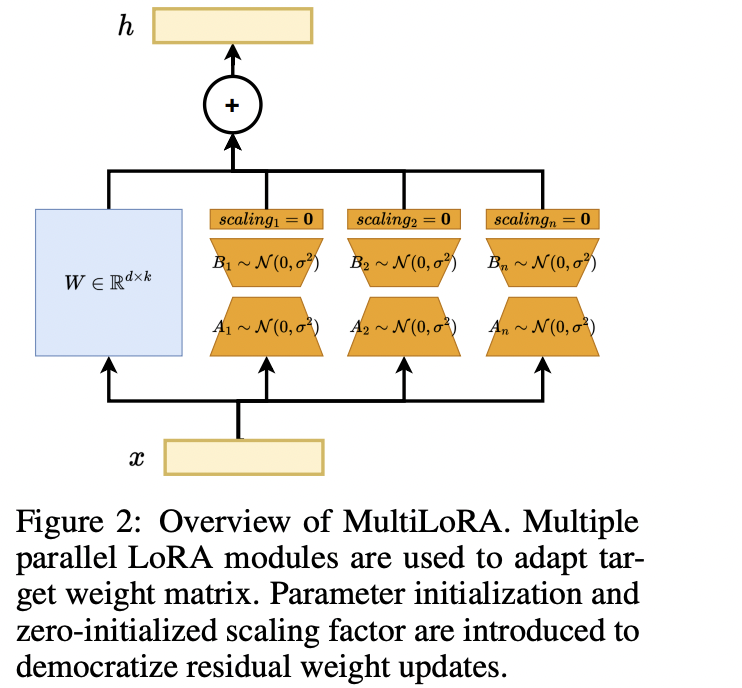
PEFT降低了大模型fine-tuning的硬件算力需求,比较常见如:LoRA;对于多任务PEFT的工作,之前的工作无法像LoRA一样和BaseModel参数做无缝集成。 Multi-LoRA在推理部署的问题的困境在于:
- 单个LoRA可以通过merge权重的方式,实现无开销的LoRA推理;但是对于Multi-LoRA而言,这种方式的效率是偏低的。
- Multi-LoRA的Adapter的数目可能很多,全量加载可能会导致显存占用过高,需要实现Host/Device侧内存的Load/OffLoad
- 对于2.的问题需要解决内存碎片和动态Load/OffLoad的延迟开销问题。
Key Points
核心流程如下:
多个lora独立,但是前向传播过程中共享所以训练数据的前向传播,但loss更新的时候会根据mask矩阵进行单个任务的LoRA权重更新。
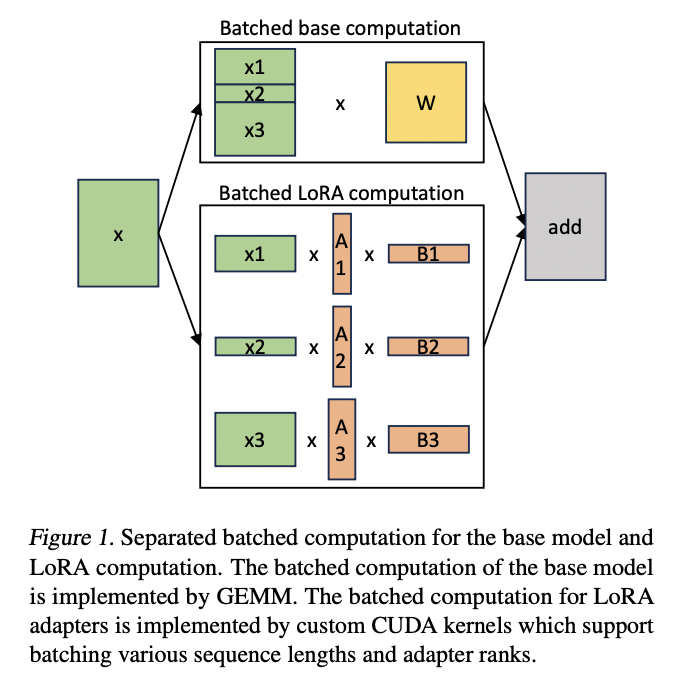
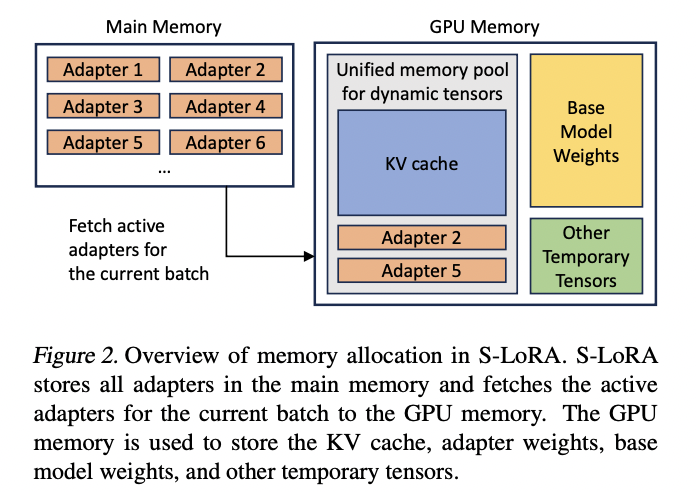
推理部署而言,核心为了解决前文的Multi-LoRA的Adator的动态加载的问题,关键方案如下:
Specified-CUDA-Kernels:定制了批处理GEMM内核来计算LoRA。

Memory-Allocator Design:Host内存存储了全量的Adater权重,实际推理过程中需要实时fetch对应的Adater权重到显存
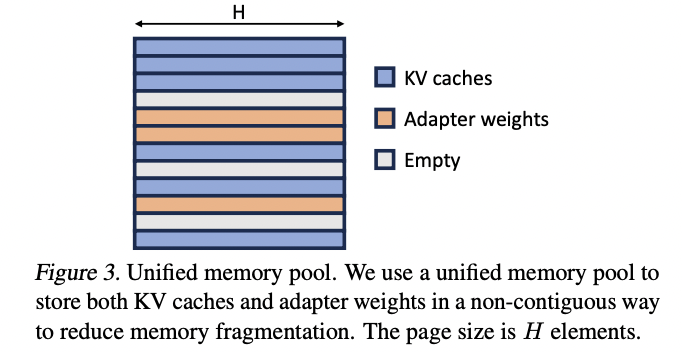
Unified Paging:扩展了PagedAttention的内存管理方式,划分了LoRA权重专门的内存池以减少内存碎片,同时提前fetch权重来实现计算/权重加载并行
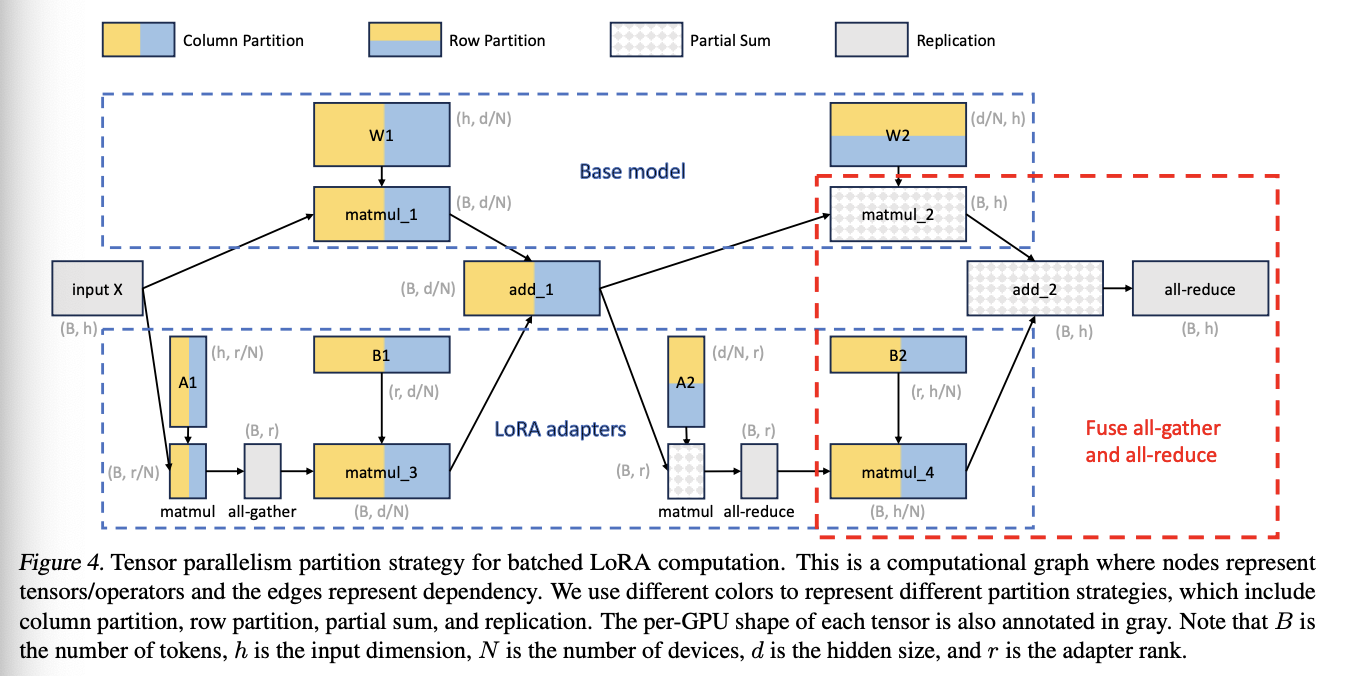
张量并行:LoRA侧的并行策略如下:
Statistics
S-LoRA策略下,单个GPU/多个GPU下可以部署数千个LoRA适配器,以下为Llama-7B/13B/30B/70B的部分结果: