LLMs量化算法概述
量化基础概念
INT8 量化将模型的权重和激活值从 FP16/FP32 转换为 INT8 格式。最简单的方式是使用线性映射将浮点数范围映射到整数范围:
- $z$ : 零点,用于偏移。
- $s$ : 缩放因子,控制浮点和整数范围的映射。
- $qmin,qmax$:对应量化的最大/最小值
根据是否依赖“再训练”,可以分为两种方案:
Post-training Quantization (PTQ):
直接对已训练模型权重进行离线量化。
常采用对称量化或非对称量化。
Quantization-aware Training (QAT):
- 在训练过程中模拟量化的影响,使模型适应量化后的权重和激活值。
量化维度
量化维度上看,可以从以下几个维度区分:
- Per-tensor:单层/单个tensor只有一个缩放因子
- per-channel:每个通道都对应一个缩放因子,如$W$的shape为$d \times h$,则缩放因子维度为 $d \times 1$
- per-token:通常对于激活量化,在token维度做量化,维度为$L \times 1$
- per-group/group-wise:以组为单位,如和channel-wise组合
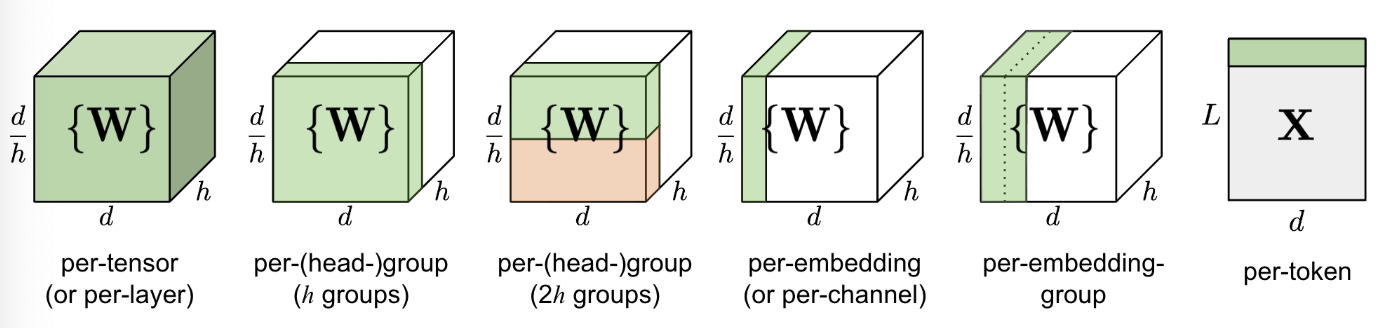
量化对象
Weight:权重量化是最常见的量化对象。量化权重可达到减少模型内存占用空间。权重在训练完后固定,数值范围与输入无关,可离线完成量化,通常相对容易量化;通常有W8A16(MinMax)、W4A16(AWQ、GPTQ)等。Activation:实际上激活往往是占内存使用的大头,因此量化激活不仅可以大大减少内存占用。更重要的是,结合权重量化可以充分利用整数计算获得模型推理性能的提升。但激活输出随输入变化而变化,需要统计数据动态范围,通常更难量化。通常有W8A8(LLM.int8、SmoothQuant)等。KV Cache:除了权重和激活量化之外,在LLMs中的KV Cache也会消耗不少的内存。 因此,量化 KV 缓存对于提高模型长序列生成的吞吐量至关重要。通常有KV8(INT8-TensorRTLLM,FP8-vLLM)、KV4(Atom)。
主流算法介绍
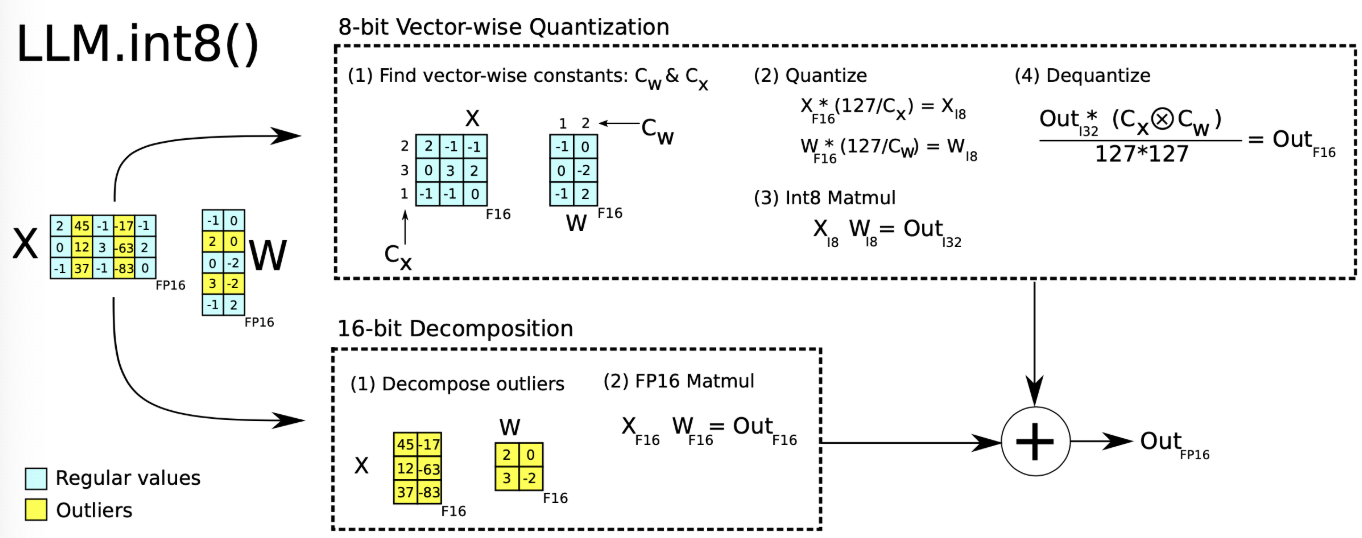
LLM.int8是一种采用混合精度分解的量化方法。该方案先做了一个矩阵分解,对绝大部分权重和激活用8bit量化(vector-wise)。对离群特征的几个维度保留16bit,对其做高精度的矩阵乘法。
LLM.int8通过三个步骤完成矩阵乘法计算:
- 从输入的隐含状态中,按列提取异常值 (离群特征,即大于某个阈值的值)。
- 对离群特征进行 FP16 矩阵运算,对非离群特征进行量化,做 INT8 矩阵运算;
- 反量化非离群值的矩阵乘结果,并与离群值矩阵乘结果相加,获得最终的 FP16 结果。
GPTQ通常存在W4A16,W8A16两种方案,一般需要校准数据集:
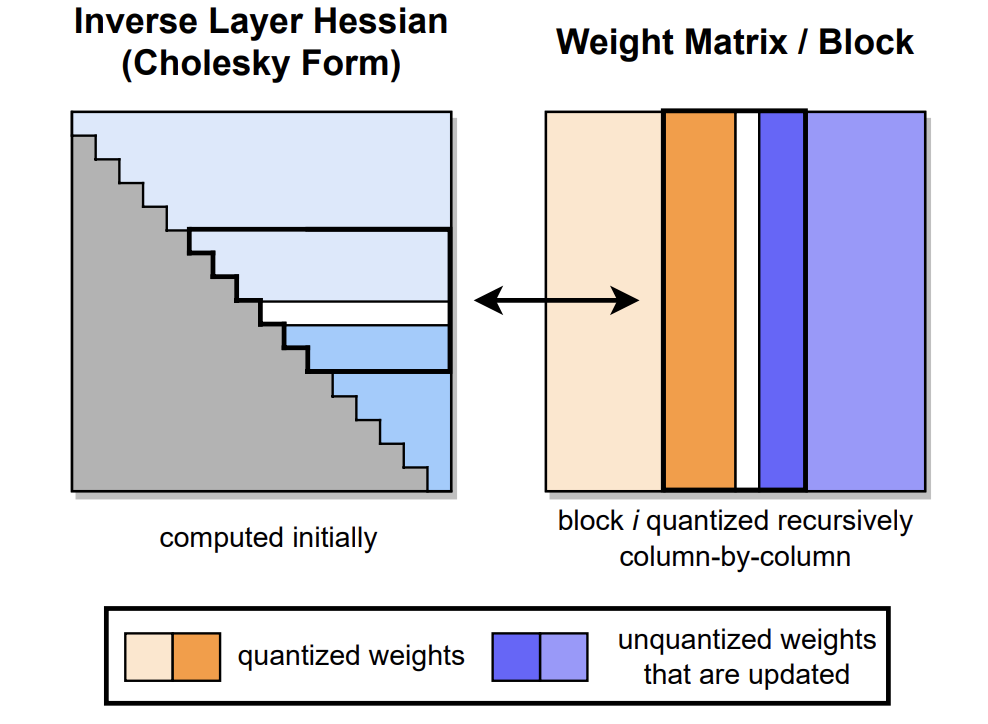
通过分解海森矩阵来迭代量化,GPTQ 将权重分组(如:128列为一组)为多个子矩阵(block)。对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。因此,GPTQ 量化需要准备校准数据集。
GPTQ 量化过程如下图所示。首先,使用 Cholesky 分解求解 Hessian矩阵的逆,然后在给定的步骤中对连续列的块进行量化,并在该步骤结束时更新剩余的权重(蓝色)。量化过程在每个块内递归应用,白色中间列表示当前正在被量化。
更新权重的伪代码如下:

支持W4A16,W8A16,激活感知的量化,为完全的int4/int8权重量化。
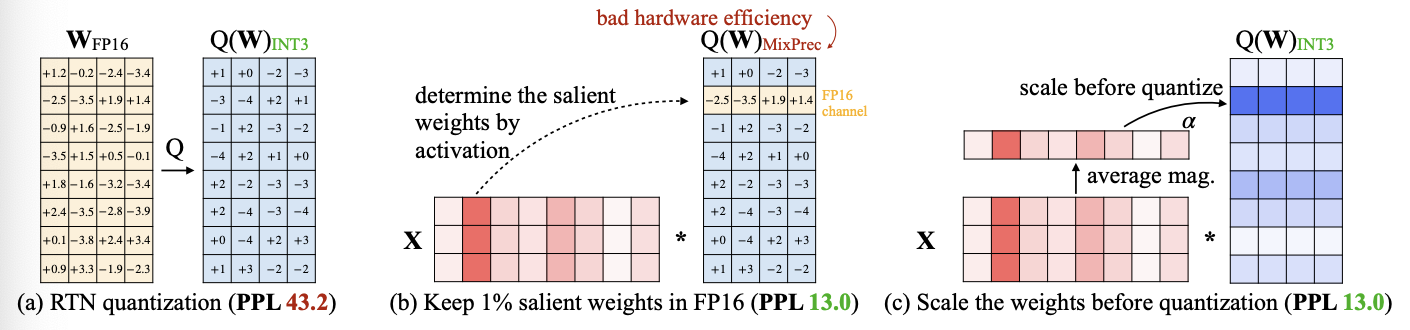
核心思路:源于“权重对于LLM的性能并不同等重要”的观察,存在约(0.1%-1%)显著权重对大模型性能影响太大,通过跳过这1%的重要权重(salient weight)不进行量化,可以大大减少量化误差。
算法步骤:
- 识别关键权重的方法是分析Activation分布。取1%的比例作为显著权重,如果采用保持FP16 channel的方式(混合精度),硬件实现比较低效。
- 显著权重乘一个放大系数scale后,量化误差会较之前变小,并且对于显著权重也给予不同的保护粒度: 论文通过最小化layer量化前后的差值来在搜索空间寻找最优的 scaling。
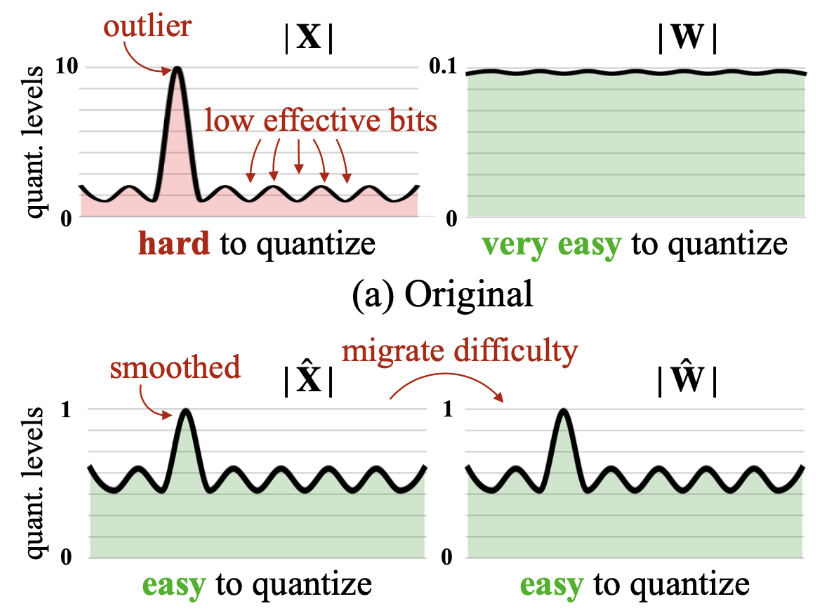
支持W8A8,支持weight/activation联合量化(对权重进行per-tensor或者per-channel,对激活进行per-token或则会per-tensor)。
其动机是发现activations需要channel-wise才能保持精度,但是channel-wise的activation量化效率很低,所以采用:
把Activation量化的难度平滑转移到weight的量化上。SmoothQuant 提出了一种数学上等价的逐通道缩放变换(per-channel scaling transformation),可显著平滑通道间的幅度,从而使模型易于量化。
KVQuant 通过结合几种新颖的方法来缓解 KV 缓存量化的精度损失。具体的优化技术如下:
- 逐通道(
Per-Channel)对 Key 进行量化,通过调整 Key 激活的量化维度以更好地匹配分布;按通道对Key进行量化也在同期的工作KIVI中被探索,该工作将同一通道中的大幅度值组合在一起以最小化量化误差。他们的按通道量化方法需要进行细粒度分组,同时保持KV缓存的一部分为fp16精度。而本工作则展示了通过利用离线校准集,可以准确地执行按通道量化,而不需要进行分组。 - 在
Position Embedding之前对 Key 进行量化,在旋转位置嵌入之前量化Key激活,以减轻其对量化的影响。 - 非均匀 KV 缓存量化,通过导出每层敏感度加权的非均匀数据类型,以更好地表示分布;
- 按向量(Per-Vector)密集和稀疏量化,分别隔离每个向量的异常值,以最大限度地减少量化范围中的偏差。
- Attention Sink 感知量化,由于 Attention Sink 现象,模型对部分Token中的量化误差异常敏感。通过仅保留这部分Token为FP16 来确保模型的精度。
- 在逐通道量化中,更新在线缩放因子是具有挑战性的,因为每个传入通道对应的缩放因子可能需要在 KV 缓存中添加新Token时进行更新。因此,离线(即在运行推理之前使用校准数据)计算统计数据。采用逐通道量化有效地进行离线校准,从而避免了在线更新缩放因子的需要。对于逐Token量化,由于存在异常的 Value tokens ,离线校准缩放因子是具有挑战性的。因此,每个传入Token在线计算缩放因子和异常值阈值。通过卸载到CPU来有效地在线计算每个Token的异常值阈值。通过利用定制的量化函数实现来压缩激活,可以在线执行逐 Token 的 Value 量化而不会影响性能。