LLMs存储
前言
简述存储相关知识栈(work with ChatGPT)。
存储技术
多级存储
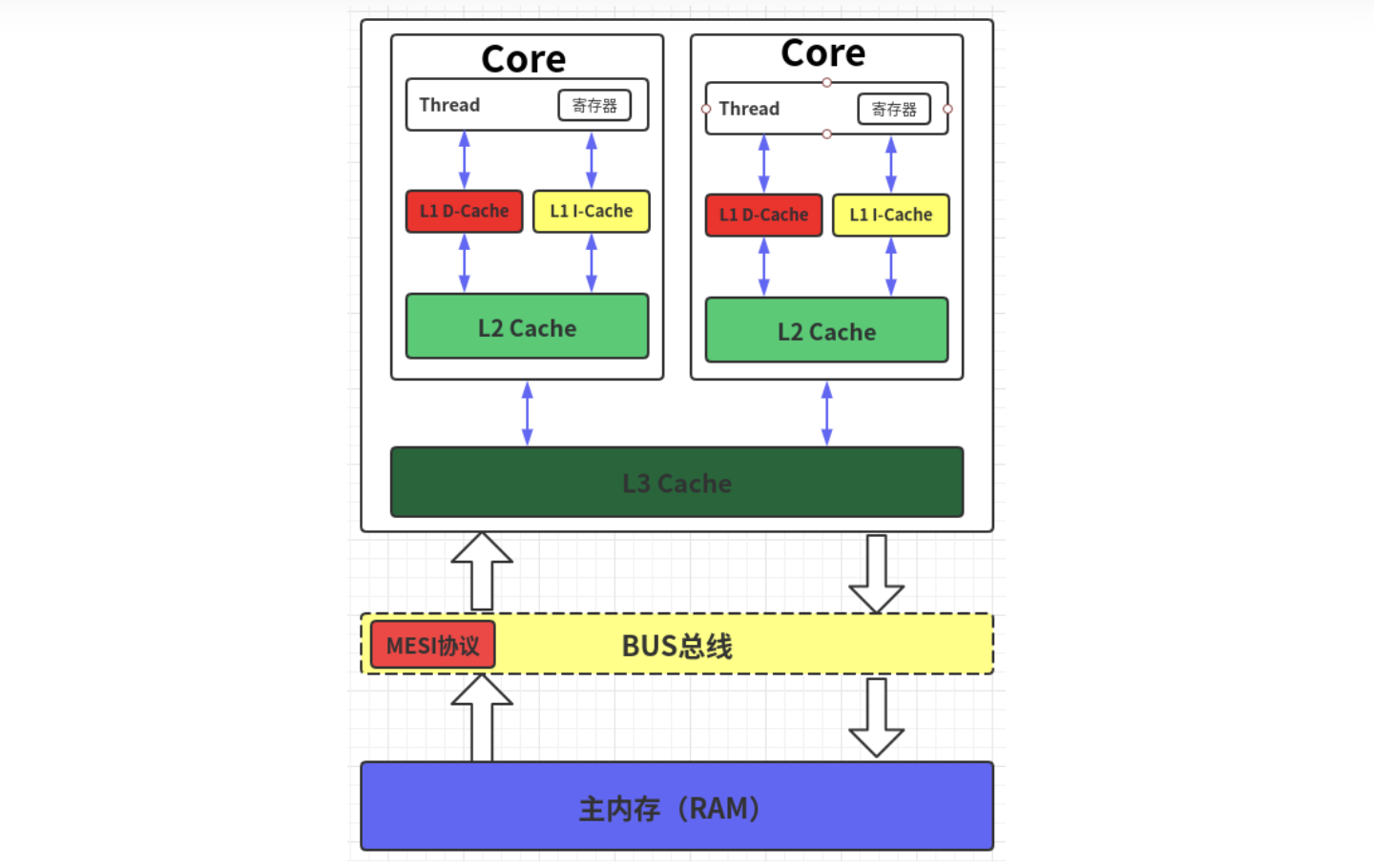
现代CPU为了提升执行效率,减少CPU与内存的交互(交互影响CPU效率),一般在CPU上集成了多级缓存架构,常见的为三级缓存结构,即L1 Cache、L2 Cache、L3 Cache的三级缓存结构。缓存级别越小,越靠近CPU,同样也意味着速度越快,但是对应的容量越少:
存储器存储空间大小:内存>L3>L2>L1>寄存器。
存储器速度快慢排序:寄存器>L1>L2>L3>内存。
从CPU到 CPU周期 执行时间(ns) 寄存器 1 cycles L1 Cache ~3-4 cycles ~0.5-1 L2 Cache ~10-20 cycles ~3-7 L3 Cache ~40-45 cycles ~15 跨槽传输 ~20 内存 ~120-240 cycles ~60-120
多级Cache设计的出发点事基于局部性原理(principle of locality):
- 时间局部性:如果某个数据项被访问,那么不久后它可能再次被访问。
- 空间局部性:如果某个数据项被访问,与它地址相邻的数据项可能很快也将被访问。
层次化存储由不同层次组成,数据只能在相邻两层间复制,上层容量小、速度快、其工艺成本更高。
Cache存储
Cache为处理器和主内存之间的存储中间层:Cache存储的是主内存的部分出处数据,必然会涉及到地址的映射关系。如最简单的直接映射(direct mapped):
\[\text{块在cache中的位置}= \text{(块地址)}\ \text{mod}\ \text{(cache中的块数量)}\]此外还有优化的映射方式:
- 全相联cache:cache 的一种组织结构,数据块可以存放在 cache 的任意位置。
- 组相联cache:cache 的一种组织结构,每个数据块在 cache 中存放的位置数量具有至少为 2 的固定值。每个数据块有 n 个位置可放的组相联 cache 被称为 n 路组相联 cache。每个数据块可以存放在一个组(set)中 n 个块的任意位置。
此外由于存在“一对多”的关系,还需要增加额外的tag:
\[\text{(cache块位置,tag)} \leftarrow \text{(块地址)}\]假设已有数据地址,访问cache数据流程为:
- 由地址得到 cache 块位置(索引字段)
- 由地址的其余高位得到标签字段,用于和 cache 中存放数据的标签位比较
- 找到索引字段指向的 cache 块,如果标签位和标签字段一样,且有效位有效,则命中
- 否则,失效
如果Cache存在失效,则需要:
- 将 PC (程序计数器)的原始值(目前PC值-4)发送到内存,流水线停顿
- 对主存进行读操作,等待主存完成访问
- 写入 cache ,主存中的数据写入 cache 的数据部分,地址的高位写入标签字段,有效位更新为有效
- 重启指令执行。即重新开始取指。
缓存读写的性能主要体现在等待存储访问的时间周期数:
\[\text{等待存储访问的时间周期数}=\frac{指令数目}{程序}\times\frac{失效次数}{指令数目}\times读/写失效代价\]由于Cache大小有限,Cache失效不可避免,因此软件层面也可以通过改善时间/空间局部性来降低失效率。如对于矩阵乘操作:
\[A=BC \ \rightarrow \ a_{ij}=\sum_{k}b_{ik}\cdot c_{kj}\]对于$(m\times k)(k \times n)$的矩阵乘法,总乘法数为$mnk$,因此最坏情况下每个数据都访问主存,则数据量为$2mnk(读次数)+mn(写次数)$。但是如果对$BC$矩阵进行分块,即分解矩阵为$m/t\times k/t$和$k/t\times n/t$矩阵,则原始矩阵乘可以转化为:
\[A_{ij}=\sum\limits_{l=1}^{k/t}B_{il}C{lj}\]则读写的数据量变为:
\[[2(mnk/t^3)+(mn/t)^2]*(t\times t)=2mnk/t+mn\]多级Cache一致性
多核场景下,由于各个核由都有各自的 cache,如果按照单核处理器的 cache 设计思路,多核处理器的各个核有可能在各自的 cache 中看到不同的值。
这个问题被称为 cache 一致性问题
如果对任何一个数据项的读取,都能返回该数据最近被写入的值,则称这样的存储系统是一致的,由此引出两个正确共享存储的概念:
- 一致性 (cache coherence): 读取操作返回的值
- 连续性 (memory consistency): 写入的值何时被读操作返回
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。MESI 是指4中状态的首字母。每个Cache line(Cache的最小存储单元)有4个状态,可用2个bit表示,以下是常见的状态转换及触发条件:
| 当前状态 | 状态描述 | 操作 | 转换后状态 | 转换描述 |
|---|---|---|---|---|
| M(Modified) | 当前缓存中的数据已被修改,且与主存中的副本不一致。 | 其他处理器请求读 | S 或 I | 数据写回主存后,与请求处理器共享(S),或者当前缓存状态变为无效(I)。 |
| E(Exclusive) | 当前缓存中的数据是最新的,与主存一致,且仅存在于当前缓存中。 | 自身写操作 | M | 数据被修改,状态转为 Modified。 |
| E(Exclusive) | 其他处理器请求读 | S | 数据被共享,状态变为 Shared。 | |
| S(shared) | 数据可以存在于多个缓存中,且与主存一致。 | 自身写操作 | M | 修改数据时,通知其他缓存失效,状态变为 Modified。 |
| S(shared) | 其他处理器请求写 | I | 其他处理器想要修改数据时,当前缓存失效。 | |
| I(Invalid) | 当前缓存中的数据无效,不能使用。 | 自身读操作 | E 或 S | 根据数据是否被共享,加载数据后状态更新为 Exclusive 或 Shared。 |
| I(Invalid) | 自身写操作 | M | 从主存加载数据后直接修改,状态变为 Modified。 |
基于MESI模拟多核下的数据读写,假设存在CPU A/CPU B,具备各自的cache a/cache b:
读取操作:
- CPU A发出了一条指令,从主内存中读取x。
- CPU A从主内存通过bus读取到 cache a中并将该cache line 设置为E状态。
- CPU B发出了一条指令,从主内存中读取x。
- CPU B试图从主内存中读取x时,CPU A检测到了地址冲突。这时CPU A对相关数据做出响应。此时x 存储于cache a和cache b中,x在chche a和cache b中都被设置为S状态(共享)。
修改操作:
- CPU A 计算完成后发指令需要修改x.
- CPU A 将x设置为M状态(修改)并通知缓存了x的CPU B,
- CPU B将本地cache b中的x设置为I状态(无效)
- CPU A 对x进行赋值。
修改后同步:
- CPU B 发出了要读取x的指令。
- CPU B 通知CPU A,CPU A将修改后的数据同步到主内存时cache a 修改为E(独享)。
- CPU A同步CPU B的x,将cache a和同步后cache b中的x设置为S状态(共享)。
虚拟存储
主存充当磁盘/闪存等辅助存储的“cache”,这种技术被称为虚拟存储。
提出虚拟存储的动机:
- 允许在多个程序间高效安全地共享内存。虚拟存储实现了将程序地址空间(只有这个程序能访问的一系列存储位置)转换为物理地址(主存的地址),这种地址转换加强了各个程序地址空间之间的保护(确保共享处理器、内存、I/O设备的多个进程之间互不读写)
- 允许单用户程序使用超出内存容量的内存
CPU其实不会直接跟内存物理地址交互,而是通过一个叫做内存管理单元(MMU),来将虚拟地址转为实际的物理地址。
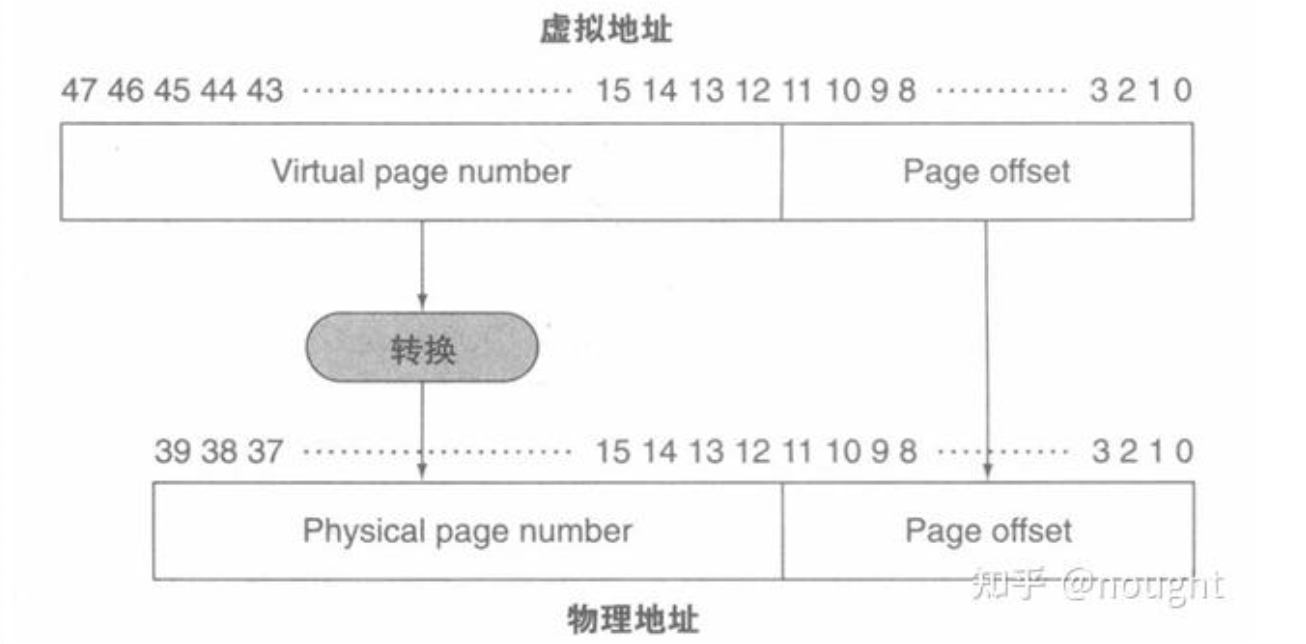
虚拟存储块被称为页,虚拟存储失效被称为缺页失效。
在虚拟存储中,处理器产生一个虚拟地址,该地址通过软硬件转换为一个物理地址,物理地址可以访问主存。
访问内存时将虚拟地址映射为物理地址的过程,称为地址转换。
在虚拟存储中,地址被划分为虚拟页号和页内偏移。虚拟页号可以转化为物理页号,而页内偏移在物理地址中和虚拟地址中保持一致。
存储硬件
LLMs 的存储层次结构从快速、低延迟的存储(如寄存器和缓存)到高容量、低成本的存储(如磁盘和网络存储)逐级递减。主要分为以下几层:
| 层次 | 存储类型 | 特点 | 主要用途 |
|---|---|---|---|
| 寄存器 | 处理器内部寄存器 | 极快,容量极小 | 保存当前执行指令所需的操作数 |
| 缓存(SRAM) | L1/L2/L3 缓存 | 高速缓存,容量较小 | 暂存经常使用的数据,减少对主存访问 |
| 高速存储 | HBM/GDDR 内存 | 高带宽存储器,专为高带宽、低延迟优化设计的DRAM | 加速 GPU 上的计算,减少内存瓶颈 |
| 主存储(DRAM) | 动态随机存储器 | 大容量,中等速度 | 存储模型权重、激活值和中间结果 |
| 磁盘存储 | SSD/HDD | 高容量,速度慢 | 存储不常用的权重、模型快照和预训练数据集 |
| 分布式存储 | NVMe over Fabric 等 | 超大容量,延迟较高 | 分布式环境下的权重加载和存储 |
GPU 存储层次结构通常可以分为以下几层,从最快但容量最小的寄存器到最慢但容量最大的全局内存和主机内存:
| 存储层次 | 位置 | 特点 | 用途 |
|---|---|---|---|
| 寄存器 | 每个 CUDA 核心独享 | 最快,容量最小 | 保存线程的局部变量,用于频繁访问的数据 |
| 共享内存 | 一个线程块的所有线程共享 | 快速,延迟低,容量有限(48 KB~64 KB) | 线程间共享数据,减少全局内存访问 |
| L1 缓存 | 每个 SM 独享 | 高速缓存,延迟低,容量较小 | 缓存局部内存或全局内存中经常访问的数据 |
| L2 缓存 | 所有 SM 共享 | 容量较大(几 MB),延迟较高 | 缓存全局内存数据,优化多 SM 之间的数据访问 |
| 全局内存 | GPU 设备上的 DRAM | 高带宽,大容量(16 GB~80 GB) | 存储大规模数据,例如模型权重、输入和中间结果 |
| 纹理/常量内存 | 专用内存区域 | 高带宽,支持只读优化 | 用于访问只读数据,例如纹理或常量 |
| 主机内存(CPU 内存) | 主机系统内存 | 超大容量,延迟高 | 存储超出 GPU 显存的数据,动态加载或交换 |