LLMs图编译概述
图编译优化主要是围绕AI编译器来实现的,整体框架可参考:The Deep Learning Compiler: A Comprehensive Survey:
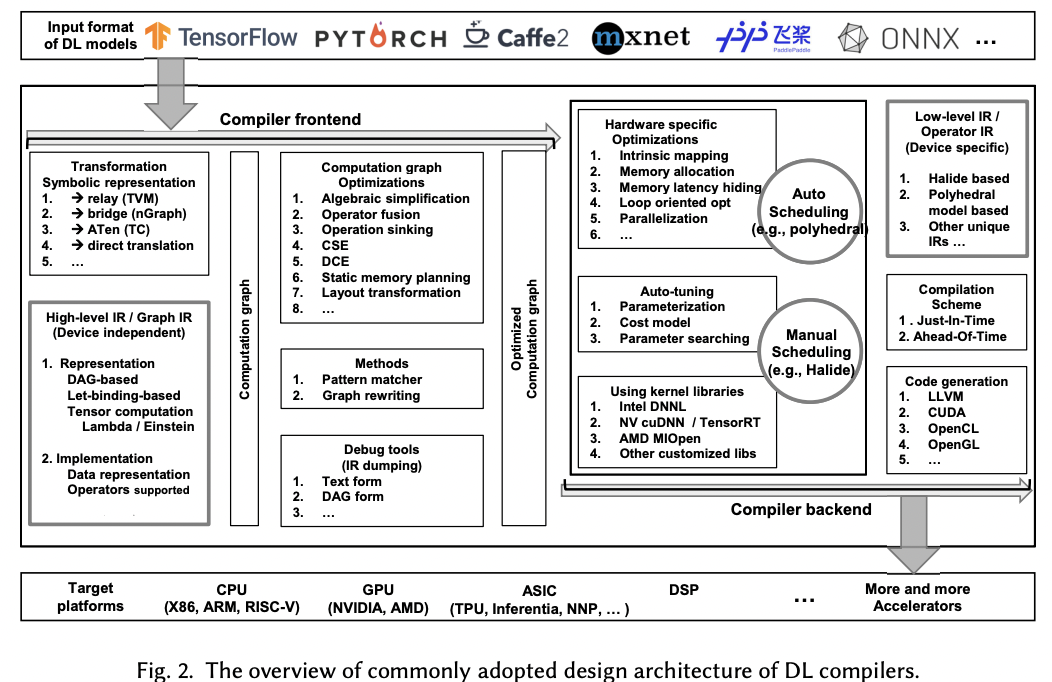
LLMs图优化
对于LLM来说,本身模型结构的变化不大,意味着图层面的优化策略是比较通用的,如:
Quant算子的融合/PointWise算子融合/自定义融合算子等,所以常用的策略是复用PyTorch等框架的Compiler,自定义LLM的Compiler,如[RFC] A Graph Optimization System in vLLM using torch.compile中介绍的:
基于TorchDynamo的FX Graph添加Used-defined Compiler来实现LLM的自定义Compiler优化。其优势是能够不开发专用Compiler的前提下,完成high-level的IR优化,同时复用TorchDynoma Low-IR侧的优化能力,但是缺点是其输入的图属于raw FX Graph,对于例如code elimination/topo sort,实现上会有些困难。
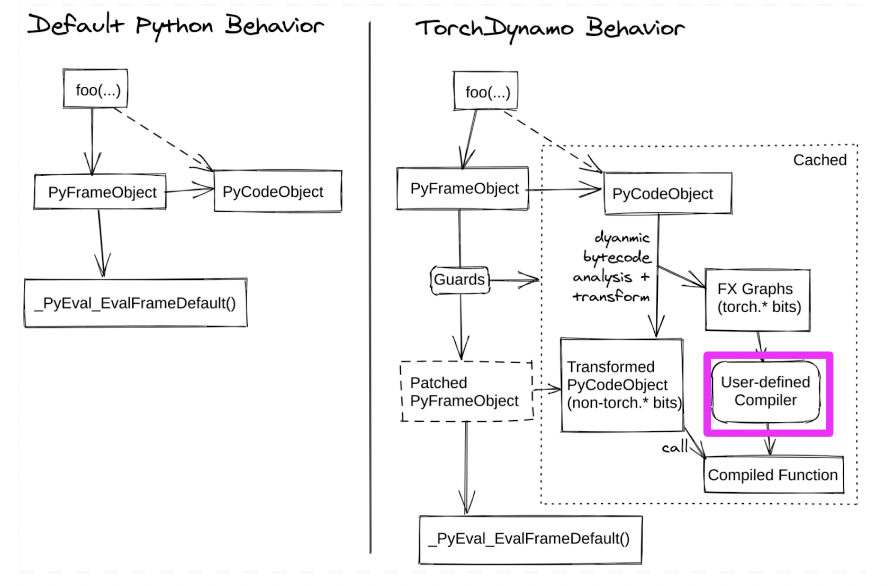
FX Graph自定义Compiler实现
以下是一个示例自定义 Compiler 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import torch
from torch.fx import GraphModule
def my_custom_compiler(fx_graph: GraphModule, example_inputs):
"""
自定义 Compiler 接收 FX Graph 并进行处理。
:param fx_graph: TorchDynamo 捕获的 FX GraphModule。
:param example_inputs: 示例输入张量,用于形状推导或优化。
:return: 返回优化后的 callable。
"""
print("Original FX Graph:")
print(fx_graph.graph)
# 对 FX Graph 进行优化或修改,例如插入自定义算子。
for node in fx_graph.graph.nodes:
if node.op == 'call_function':
print(f"Optimizing node: {node.name}, function: {node.target}")
# 可以返回修改后的 GraphModule 或直接生成一个新的函数。
fx_graph.graph.lint() # 检查修改后的图是否有效
fx_graph.recompile() # 重新编译图以应用更改
# 返回一个可调用的模块
return fx_graph
注册自定义 Compiler,使用 TorchDynamo 的torch._dynamo.optimize 接口,将自定义 Compiler 绑定到目标模型:
1
2
3
4
5
6
7
8
import torch._dynamo as dynamo
# 注册自定义 Compiler
optimized_model = dynamo.optimize(my_custom_compiler)(model)
# 运行优化后的模型
example_inputs = torch.randn(1, 3, 224, 224) # 示例输入
output = optimized_model(example_inputs)
打印的Fx Graph如下:
1
2
3
4
5
6
7
graph():
%x : [#users=1] = placeholder[target=x] # 输入张量 x
%linear_weight : [#users=1] = get_attr[target=linear.weight]
%linear_bias : [#users=1] = get_attr[target=linear.bias]
%linear_output : [#users=1] = call_function[target=torch.nn.functional.linear](args = (%x, %linear_weight, %linear_bias), kwargs = {})
%relu_output : [#users=1] = call_function[target=torch.nn.functional.relu](args = (%linear_output,), kwargs = {})
return relu_output