LLM长文本优化策略
长文本对LLM带来的挑战主要在于显存上的,核心原因是:
原始Attention的计算过程中,中间变量的大小是$O(N^2)$增长的,可以通过FlashAttention的Tiling设计来降低中间变量显存为$O(\frac {N ^ 2}{M})$,$KV_Cache$和FFN层的激活都为$O(N)$,所以核心思路是降低$sequence\ length$,主要有以下两种方法:
SP(序列并行,Sequence Parallism),而序列并行最典型的思路便是:ULYSESS和Ring Attention。
Ulysess
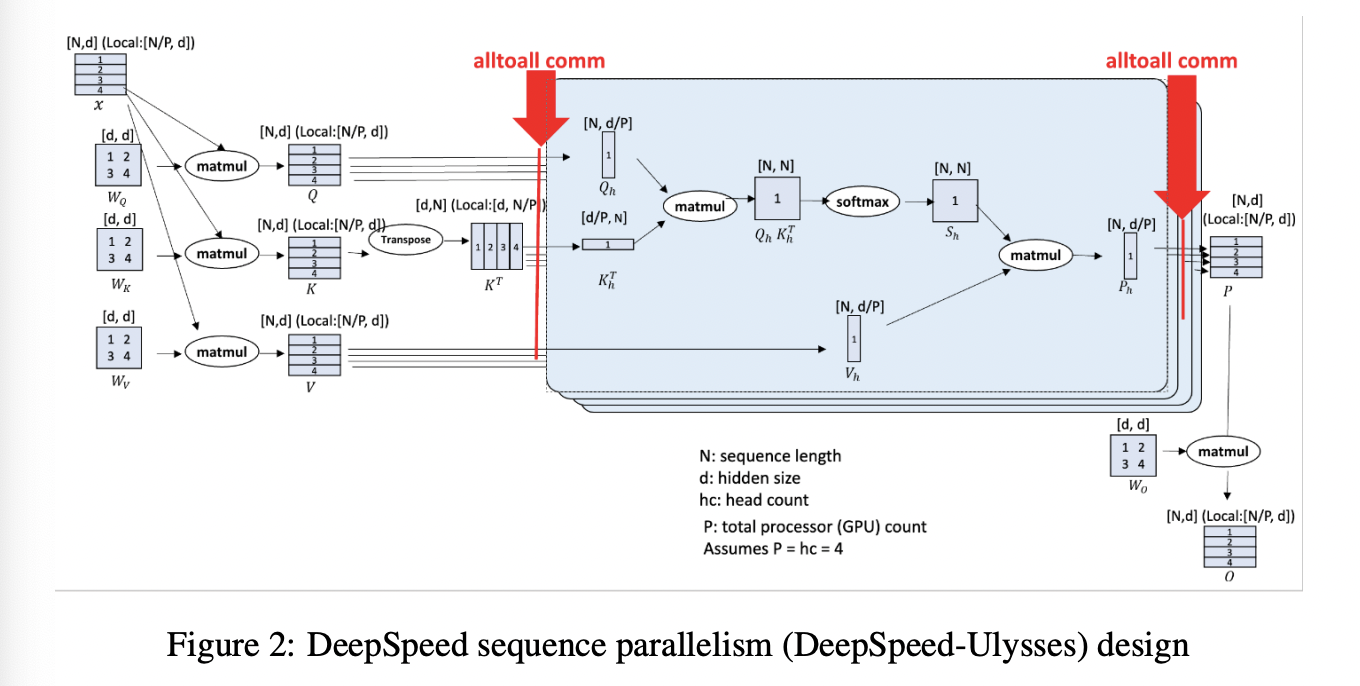
核心思路是:Q/K/V矩阵按照N维度做切分,然后workers之间通过All2All转换为d维度切分(前置知识:All2All等价于分布式Transpose),然后可以按照$Softmax(QK^T)$计算,然后再做一次All2All通信转置回来,单次通信量为$O(N \times d)$,与卡数目无关,总通信量为$3 \times O(N \times d)$限制条件是$d/P$可整除,对GQA/MQA不友好。

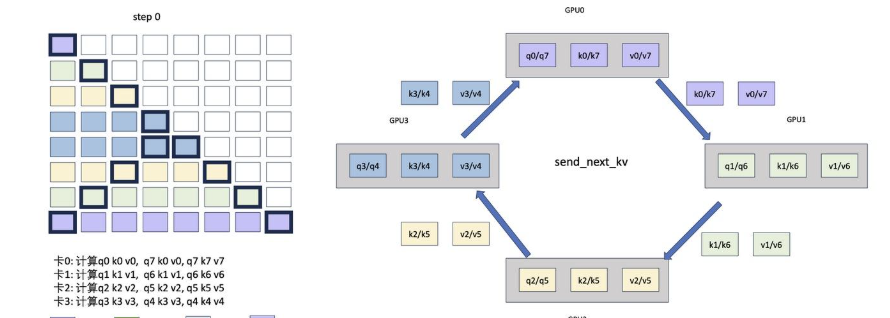
RingAttention
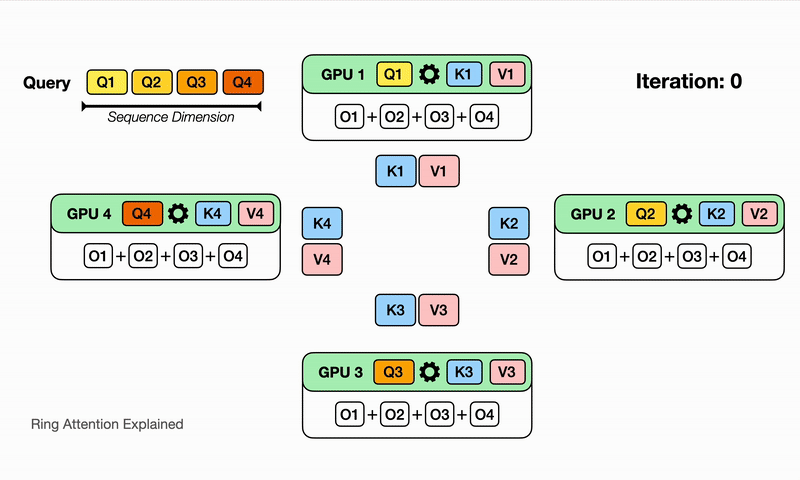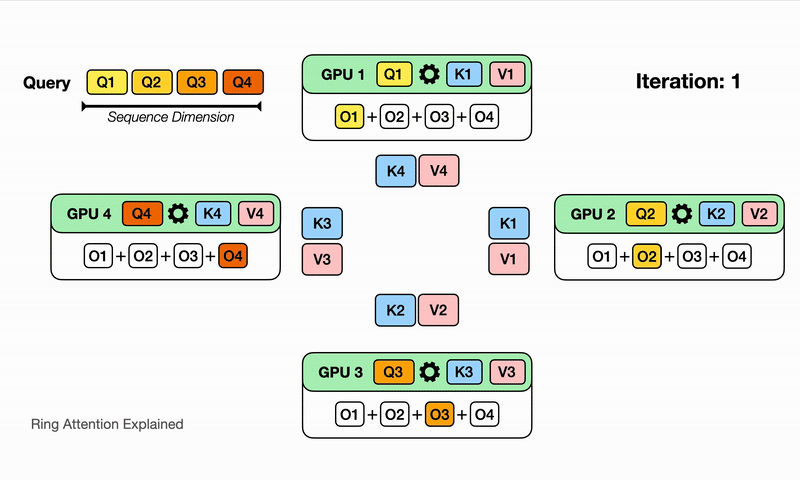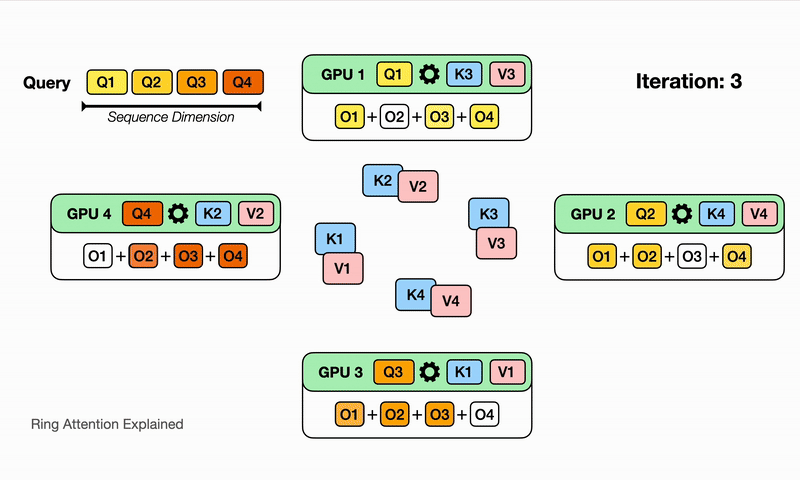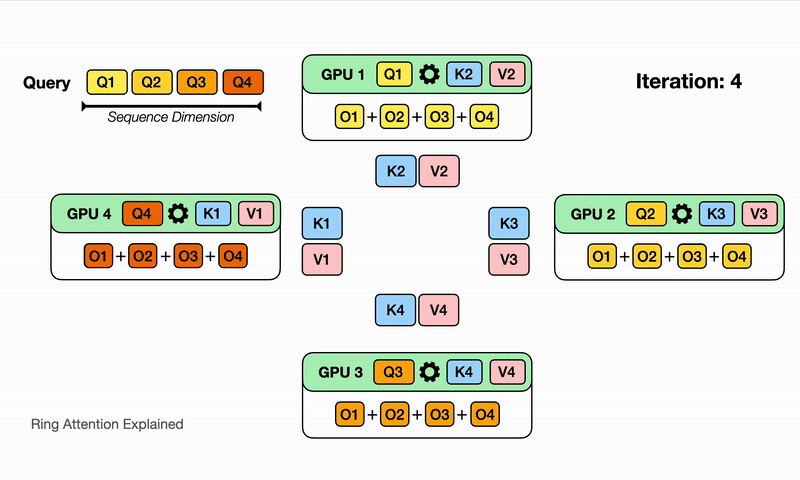
可以认为是分布式的FlashAttention,其核心修改点是:内层循环K、V的时候需要通过P2P通信来得到不同Device间的K、V中间结果,RingAttention的单次通信量是$O(Nd)P$,和卡量相关,总通信量为$N/P/c(P-1)O(N*d)$,其中P为卡量,c为单次计算的block大小,但是计算和通信理论上可以流水,且当计算时间大于通信时间的时候,能够overlap。
Ring-Attention的优点在于泛化性好,即插即用,P2P对通信要求低,但是通信量更大,且存在负载均衡的问题,具体表现为越到后面的seq实际的计算量越大。
从负载角度,因为Prefill阶段,计算强度大,通信量相对低,Decode阶段,计算强度低,通信量高,因此通常可以采用不同的交换策略:
Prefill:基于RingAttention交换kv。交换完kv后,每张卡获取全量kv,每张卡都是部分的q和部分o,需要merge得到全量attention。同时,RingAttention还需要考虑负载均衡:不同rank的chunk不一样,计算量也不一致,简单的负载均衡策略可以为:$rank_0$负载$chunk_0/chunk_{n}$
Decode:仅交换q,即prefill阶段保存了全量的kv,每张卡上仅保存部分q。