注意点
BN层编译部分: Batchnormalization的axis参数在卷积层和池化层应为1(4维数据) Dense层保持默认即可 但是对于keras 2,2,4和tensorflow-gpu 1.12会出现错误 可参照链接对对应文件进行修改,文件修改如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
if ndim(mean) > 1:
#mean = tf.reshape(mean, (-1))
#added by zwg 20190121
mean = tf.reshape(mean, [-1])
if ndim(var) > 1:
#var = tf.reshape(var, (-1))
#added by zwg 20190121
var = tf.reshape(var, [-1])
if beta is None:
beta = zeros_like(mean)
elif ndim(beta) > 1:
#beta = tf.reshape(beta, (-1))
#added by zwg 20190121
beta = tf.reshape(beta, [-1])
if gamma is None:
gamma = ones_like(mean)
elif ndim(gamma) > 1:
#gamma = tf.reshape(gamma, (-1))
#added by zwg 20190121
gamma = tf.reshape(gamma, [-1])
Import all required libraries
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
XS
import matplotlib.pyplot as plt
%matplotlib inline
from keras.models import Sequential
from keras.layers import Dense , Dropout , Lambda, Flatten
from keras.optimizers import Adam ,RMSprop
from sklearn.model_selection import train_test_split
from keras import backend as K
from keras.preprocessing.image import ImageDataGenerator
# Input data files are available in the "input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
1
2
3
4
5
6
Using TensorFlow backend.
sample_submission.csv
test.csv
train.csv
Load Train and Test data
1
2
3
4
# create the training & test sets, skipping the header row with [1:]
train = pd.read_csv("../input/train.csv")
print(train.shape)
train.head()
1
(42000, 785)
| label | pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | ... | pixel774 | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 785 columns
1
2
3
test= pd.read_csv("../input/test.csv")
print(test.shape)
test.head()
1
(28000, 784)
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel774 | pixel775 | pixel776 | pixel777 | pixel778 | pixel779 | pixel780 | pixel781 | pixel782 | pixel783 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 784 columns
1
2
3
4
X_train = (train.iloc[:,1:].values).astype('float32') # all pixel values
y_train = train.iloc[:,0].values.astype('int32') # only labels i.e targets digits
X_test = test.values.astype('float32')
X_train
1
2
3
4
5
6
7
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)
1
y_train
1
array([1, 0, 1, ..., 7, 6, 9], dtype=int32)
Data Visualization
1
2
3
4
5
6
X_train = X_train.reshape(X_train.shape[0], 28, 28)
for i in range(6, 9):
plt.subplot(330 + (i+1))
plt.imshow(X_train[i], cmap=plt.get_cmap('gray'))
plt.title(y_train[i]);

1
2
3
#expand 1 more dimention as 1 for colour channel gray
X_train = X_train.reshape(X_train.shape[0], 28, 28,1)
X_train.shape
1
(42000, 28, 28, 1)
1
2
X_test = X_test.reshape(X_test.shape[0], 28, 28,1)
X_test.shape
1
(28000, 28, 28, 1)
Preprocessing the digit images
Feature Standardization
1
2
3
4
5
mean_px = X_train.mean().astype(np.float32)
std_px = X_train.std().astype(np.float32)
def standardize(x):
return (x-mean_px)/std_px
One Hot encoding for labels
1
2
3
4
5
6
from keras.utils.np_utils import to_categorical
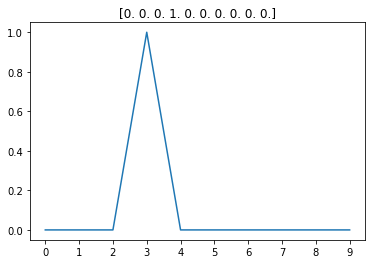
y_train= to_categorical(y_train)
num_classes = y_train.shape[1]
plt.title(y_train[9])
plt.plot(y_train[9])
plt.xticks(range(10));
1
2
/usr/local/lib/python3.5/dist-packages/matplotlib/text.py:1191: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
if s != self._text:
Designing Neural Network Architecture
1
2
3
# fix random seed for reproducibility
seed = 43
np.random.seed(seed)
Linear Model
1
2
3
4
5
6
7
#Lambda layer:sum, average, exponentiation etc.
#Flatten will transform input into 1D array
#Dense: Full-connect layer
from keras.models import Sequential
from keras.layers.core import Lambda , Dense, Flatten, Dropout
from keras.callbacks import EarlyStopping
from keras.layers import BatchNormalization, Convolution2D , MaxPooling2D
1
2
3
4
5
6
model= Sequential()
model.add(Lambda(standardize,input_shape=(28,28,1)))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
print("input shape ",model.input_shape)
print("output shape ",model.output_shape)
1
2
input shape (None, 28, 28, 1)
output shape (None, 10)
Compile network
1
2
3
4
5
6
7
# Add a loss layer
# Add an optimizer
# Add a metrics to monitor the performance of the network
from keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(lr =0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
1
2
from keras.preprocessing import image
gen = image.ImageDataGenerator()
Cross Validation
1
2
3
4
5
6
from sklearn.model_selection import train_test_split
X = X_train
y = y_train
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.10, random_state=42)
batches = gen.flow(X_train, y_train, batch_size=64)
val_batches = gen.flow(X_val, y_val, batch_size=64)
1
2
history = model.fit_generator(generator=batches, steps_per_epoch=batches.n, epochs=1,
validation_data=val_batches, validation_steps=val_batches.n)
1
2
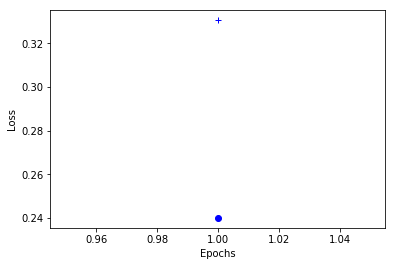
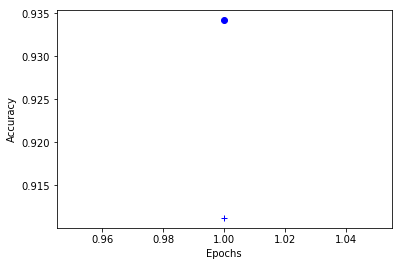
Epoch 1/1
37800/37800 [==============================] - 198s 5ms/step - loss: 0.2401 - acc: 0.9342 - val_loss: 0.3306 - val_acc: 0.9112
1
2
history_dict = history.history
history_dict.keys()
1
dict_keys(['val_acc', 'loss', 'val_loss', 'acc'])
1
2
3
4
5
6
7
8
9
10
11
12
13
import matplotlib.pyplot as plt
%matplotlib inline
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss_values, 'bo')
# "b+" is for "blue crosses"
plt.plot(epochs, val_loss_values, 'b+')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
1
2
3
4
5
6
7
8
9
plt.clf() # Clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc_values, 'bo')
plt.plot(epochs, val_acc_values, 'b+')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.show()
Fully Connected Model
1
2
3
4
5
6
7
8
9
10
11
12
13
# 构建两层全连接层:
# 前层负激活数据(Relu)
# 后层输出分类
def get_fc_model():
model = Sequential([
Lambda(standardize, input_shape=(28,28,1)), # standardize
Flatten(), # Change data into 1-d array
Dense(512, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='Adam', loss='categorical_crossentropy',
metrics=['accuracy'])
return model
1
2
fc = get_fc_model()
fc.optimizer.lr=0.01
1
2
3
# history = fc.fit_generator(generator=batches, steps_per_epoch=batches.n,
# epochs=1, validation_data=val_batches,
# validation_steps=val_batches.n)
Convolutional Neural Network
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from keras.layers import Convolution2D, MaxPooling2D
def get_cnn_model():
model = Sequential([
Lambda(standardize, input_shape=(28,28,1)),
Convolution2D(32, (3,3), activation='relu'),
Convolution2D(32, (3,3), activation='relu'),
MaxPooling2D(),
Convolution2D(64, (3,3), activation='relu'),
Convolution2D(64, (3,3), activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(Adam(), loss='categorical_crossentropy',
metrics=['accuracy'])
return model
1
2
model = get_cnn_model()
model.optimizer.lr = 0.01
1
2
3
4
# history = model.fit_generator(generator=batches,steps_per_epoch=batches.n,
# epochs=1, validation_data=val_batches,
# validation_steps = val_batches.n
# )
Data Augmentation
1
2
3
4
5
6
7
8
9
10
11
12
# Different data aumentation techniques:
# Cropping
# Rotating
# Scaling
# Translating
# Flipping
# Adding Gaussian noise to input images etc.
gen = ImageDataGenerator(rotation_range=8, width_shift_range=0.08,
shear_range=0.3, height_shift_range=0.08,
zoom_range=0.08)
batches = gen.flow(X_train, y_train, batch_size=64)
val_batches = gen.flow(X_val, y_val, batch_size=64)
1
2
3
4
5
model.optimizer.lr = 0.001
# history = model.fit_generator(generator=batches,
# steps_per_epoch=batches.n, epochs=1,
# validation_data=val_batches,
# validation_steps=val_batches.n)
Adding Batch Normalization
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from keras.layers.normalization import BatchNormalization
def get_bn_model():
model = Sequential([
Lambda(standardize, input_shape=(28,28,1)),
Convolution2D(32,(3,3), activation='relu'),
BatchNormalization(axis=1),
Convolution2D(32,(3,3), activation='relu'),
MaxPooling2D(),
BatchNormalization(axis=1),
Convolution2D(64,(3,3), activation='relu'),
BatchNormalization(axis=1),
Convolution2D(64,(3,3), activation='relu'),
MaxPooling2D(),
Flatten(),
BatchNormalization(),
Dense(512, activation='relu'),
BatchNormalization(),
Dense(10, activation='softmax')
])
model.compile(Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
return model
1
2
3
model= get_bn_model()
model.optimizer.lr=0.01
history=model.fit_generator(generator=batches, steps_per_epoch=batches.n, epochs=1,validation_data=val_batches, validation_steps=val_batches.n)
1
2
Epoch 1/1
37800/37800 [==============================] - 2453s 65ms/step - loss: 0.0350 - acc: 0.9902 - val_loss: 0.0485 - val_acc: 0.9898
Submitting Predictions to Kaggle
1
2
3
4
model.optimizer.lr = 0.01
gen = image.ImageDataGenerator()
batches = gen.flow(X, y, batch_size=64)
history = model.fit_generator(generator=batches, steps_per_epoch=batches.n, epochs=3)
1
2
3
4
5
6
Epoch 1/3
42000/42000 [==============================] - 2573s 61ms/step - loss: 0.0128 - acc: 0.9980
Epoch 2/3
42000/42000 [==============================] - 2224s 53ms/step - loss: 0.0195 - acc: 0.9984
Epoch 3/3
42000/42000 [==============================] - 2937s 70ms/step - loss: 0.0241 - acc: 0.9983
1
2
3
4
predictions = model.predict_classes(X_test, verbose=0)
submissions = pd.DataFrame({"ImageId": list(range(1, len(predictions)+1)),
"Label": predictions})
submissions.to_csv("DR.csv", index=False, header=True)