前言
简单介绍各类AttentionScore优化算法。
FlashAttentionV1
FlashAttention于2022年6月由斯坦福大学、纽约州立大学研究者完成。 FlashAttention的核心思路是:通过重组Attention计算,能够对输入块进行分块,逐步执行softmax的reduction,避免了整个输入块的计算,从而减少了更少的内存访问(HBM),同时中间结果不需要输出都HBM。
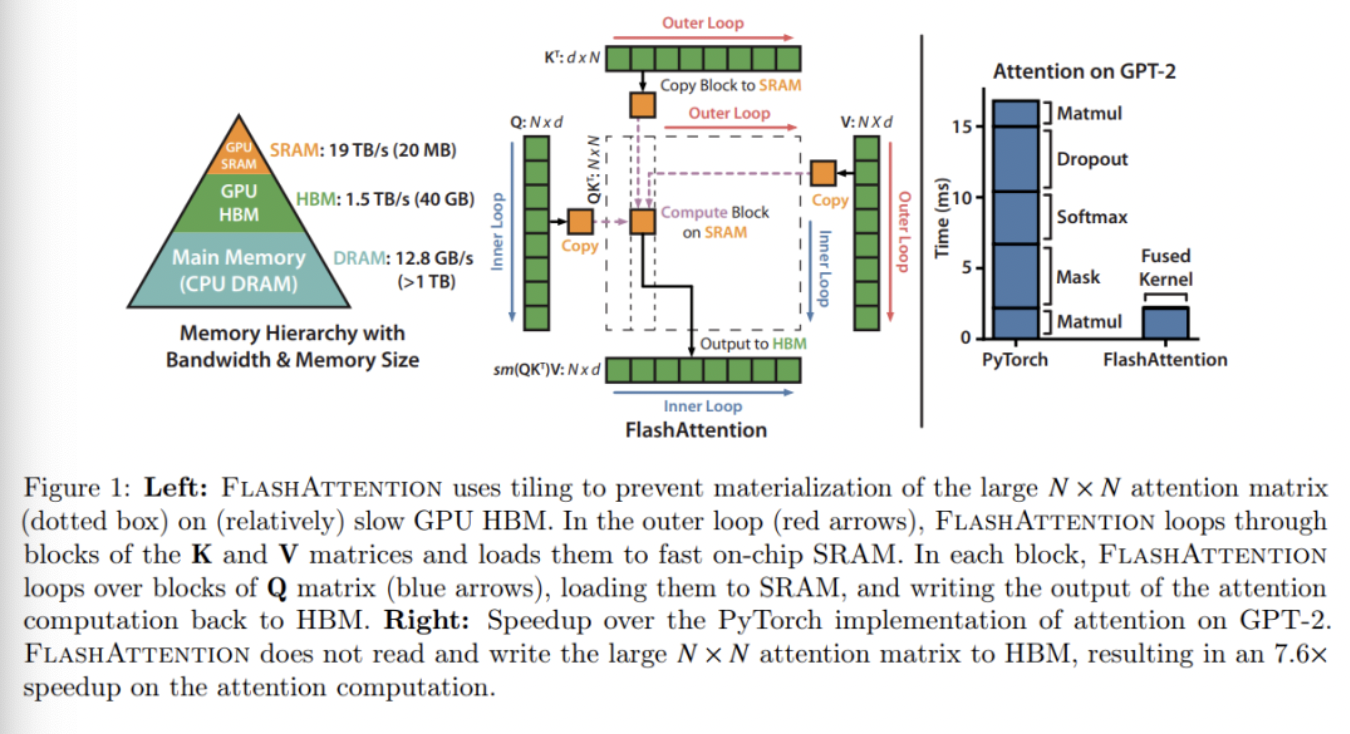
前置背景
由于计算机多级缓存的设计:SRAM,HBM,DRAM的带宽逐渐变小,容量逐渐变大。 原始AttentionScore的IO复杂度为$Ω(N \times d+N^2)$HBM访问,其中$d$为head维度,N和batch相关。
算法设计
FlashAttention的核心思路在于Online-Softmax和分块计算。其旨在通过调整注意力计算顺序,通过两个额外的统计量进行分块计算,避免了实例化完整的$N \times N$的注意力矩阵$P,S$,减少了HBM的访问次数。
Online-Softmax是在Safe-Softmax基础上的改进,Safe-Softmax公式如下:
Online-Softmax通过迭代的方式来更新$y_i$:
其中,$d_j$和$m_j$需要存储中间变量,最终的伪代码如下:
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 1: m_0 \leftarrow - \infty $
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 2: d_0 \leftarrow 0$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 3: \text {for} \ j \leftarrow 1,V \ \text{do} $
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 4:\ \ \ \ m_j \leftarrow \text{max}(m_{j-1}, x_j)$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 5:\ \ \ \ d_j \leftarrow d_{j-1} \times e^{m_{j-1}-m_j}+e^{x_j-m_j}$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 6: \text {end for}$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 7: \text {for} \ i \leftarrow 1,V \ \text{do} $
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 8:\ \ \ \ y_j \leftarrow \frac{e^{x_i-m_V}}{d_V}$
$\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 9: \text {end for}$
FlashAttention的算法流程如下:

FlashAttention仅需要$O\left(\frac {N^2 \times d^2} {M}\right)$HBM访问,其中M为SRAM大小(决定分块大小)。
FlashAttentionV2
FlashAttentionV2于2023年7月提出,其核心贡献点在于:
减少non-matmul FLOPS操作:原始softmax计算需要减去最大值,但是会增加x的遍历次数,v2去除了这部分操作,而是在局部块中进行弥补计算,且消除了rescale计算。中间变量上,从V1的$d_j$和$m_j$的中间变量存储到$l_j$的存储。
实现了序列长度上的并行,即对于单head长seq下也能实现良好的并行:FlashAttention算法有两个循环,K,V在外循环j,Q,O在内循环i。
FlashAttention-2将Q移到了外循环i,K,V移到了内循环j,由于改进了算法使得warps之间不再需要相互通信去处理Q_i,所以外循环可以放在不同的thread block上。
GPU优化:同一个attention计算块内,将工作分配在单个thread block的不同warp上,能够坚守通信和共享内存。
V1和V2的区别主要体现在局部Attention的计算上:
\[\text {FlashAttentionV1:}\ O^{(1)}=P(1)V^{(1)}=diag(l^{(1)})^{-1}e^{S^{(1)}-m^{(1)}}V^{(1)}\] \[\text {FlashAttentionV2:}\ O^{(1)}=e^{S^{(1)}-m^{(1)}}V^{(1)}\]$\text {FlashAttentionV2}$没有通过$diag(l^{(i)})^{-1}$来rescale,需要弥补max值且最后输出$O^{(last)}$需要再rescale:
\[O^{(2)}=diag(e^{m^{(1)}-m^{(2)}})O^{(1)}+e^{S^{(2)}-m^{(2)}}V^{(2)}=e^{s^{(1)}-m}V^{(1)}+e^{e^{(2)}-m}V^{(2)}\] \[O=diag(l^{(2)})^{-1}O^{(2)}\]Formad pass伪代码如下:

基础实现参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import torch
torch.manual_seed(456)
N, d = 16, 8
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
expected_softmax = torch.softmax(Q_mat @ K_mat.T, dim=1)
expected_attention = expected_softmax @ V_mat
# 分块(tiling)尺寸,以SRAM的大小计算得到
Br = 4
Bc = d
O = torch.zeros((N, d))
# 算法流程第3步,执行外循环
for block_start_Br in range(0, N, Br):
block_end_Br = block_start_Br + Br
# 算法流程第4步,从HBM中load Qi 的一个block到SRAM
Qi = Q_mat[block_start_Br:block_end_Br, :]
# 算法流程第5步,初始化每个block的值
Oi = torch.zeros((Br, d)) # shape Br x d
li = torch.zeros((Br, 1)) # shape Br x 1
mi = torch.full((Br, 1), -torch.inf) # shape Br x 1
# 算法流程第6步,执行内循环
for block_start_Bc in range(0, N, Bc):
block_end_Bc = block_start_Bc + Bc
# 算法流程第7步,load Kj, Vj到SRAM
Kj = K_mat[block_start_Bc:block_end_Bc, :]
Vj = V_mat[block_start_Bc:block_end_Bc, :]
# 算法流程第8步
Sij = Qi @ Kj.T
# 算法流程第9步
mi_new = torch.max(torch.column_stack([mi, torch.max(Sij, dim=1).values[:, None]]), dim=1).values[:, None]
Pij_hat = torch.exp(Sij - mi_new)
li = torch.exp(mi - mi_new) * li + torch.sum(Pij_hat, dim=1)[:, None]
# 算法流程第10步
Oi = Oi * torch.exp(mi - mi_new) + Pij_hat @ Vj
mi = mi_new
# 第12步
Oi = Oi / li
# 第14步
O[block_start_Br:block_end_Br, :] = Oi
FlashAttentionV3
FlashAttentionV3核心优化是在Hopper架构上做的,核心在于两个部分:硬件异步和FP8低精度:
硬件异步
Hopper引入新硬件模块:
Tensor Memory Accelerator(TMA),TMA允许在全局内存和共享内存之间进行高效的异步数据传输,减少了对寄存器的依赖。用TMA方式在全局内存和共享内存之间异步拷贝,GPU可以把节省下来的指令cycle用来发射计算。作者把这个优化叫warp-specialization,specialization也有就是部分warp生产,部分warp消费,大家各自分工之意。通过warp-group的思路来重叠GEMM和Softmax计算,进行ping-pang scheduling。
FP低精度
为了提高FP精度,减少outlier,核心用了两项技术:
- block quantization:将Q,K,V分块,每块一个scaling factor。
- Incoherent Processing:将Q,K分别乘一个随机正交的矩阵,这样每个Q,K outliner都减少了,而且不影响最终结果。
PagedAttention
PagedAttention由vLLM提出,其核心在于它允许在非连续空间内存储连续的KV张量,具体来说:PagedAttention能够把每个序列的KV缓存进行分块,每个块包含固定长度的token,且在计算attention时可以高效地找到并获取对应内存块。
设计上,参考虚拟内存和分页的思想:每个固定长度的块可以看成虚拟内存中的页,token可以看成字节,序列可以看成进程。那么通过一个块表就可以将连续的逻辑块映射到非连续的物理块,而物理块可以根据新生成的token按需分配。
PagedAttention能够进行高效的内存共享:在并行采样的时候,一个prompt需要生成多个输出序列。这种情况下,对于这个prompt的计算和内存可以在输出序列之间共享。
通过块表可以自然地实现内存共享。类似进程之间共享物理页,在PagedAttention中的不同序列通过将逻辑块映射到一样的物理块上可以实现共享块。为了确保安全共享,PagedAttention跟踪物理块的引用计数,并实现了Copy-on-Write机制。 内存共享减少了55%内存使用量,大大降低了采样算法的内存开销,同时提升了高达2.2倍的吞吐量。
参考材料
FlashAttention:加速计算,节省显存, IO感知的精确注意力