目录
Frustum PointNets for 3D Object Detection from RGB-D data
论文背景以及基本思想
论文出发点:作者认为直接在三维空间内进行点云信息的学习得到3D Box的位置和大小更高效,不会带来点云信息的损失。但是在全局点云上进行卷积过于耗费资源。基于图片可以得到较为准确的2D detection结果,但是位置不精确,所以可以结合两者优势,先通过2D检测得到粗略的3D proposal,再进一步进行精确位置的计算。
算法基本流程
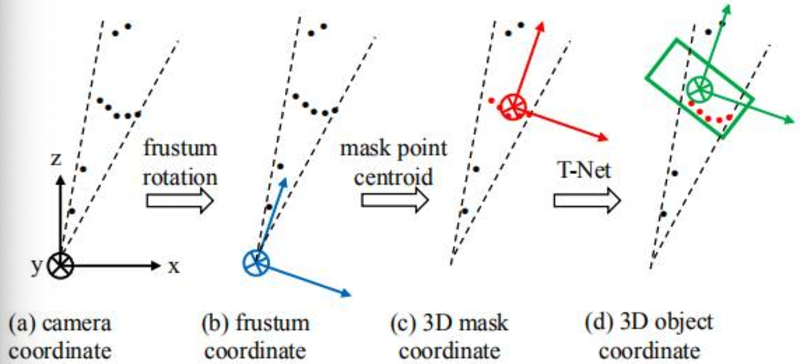
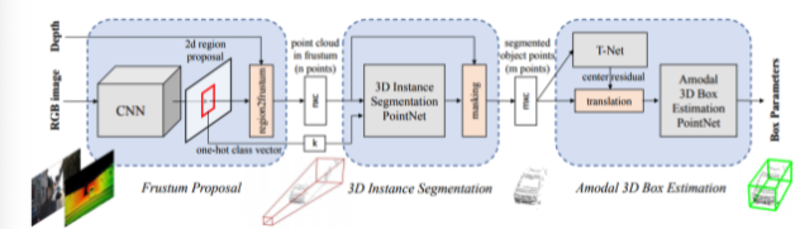
流程:论文先采用2d detector在RGB图上得到2D box作为Proposal,然后通过Depth数据映射到3D的视锥中,得到对应的三维点云(不是精确的分割得到的点云)。然后将视锥内的三维点云,通过PointNet进行3D的Segmentation,本质是对点进行的2分类(多类的话是多分类:one-hot class vector)。之后3D Box的预测会在Masking后的点云上进行,以点云中心作为坐标原点,坐标系方向与视锥方向一致。之后通过T-Net(轻量PointNet进行center点的再次预测,可以认为是alignment),之后再通过3D Box Estimation PointNet进行检测框的预测
框架图:

核心点:
- 通过2D detection结果和depth数据得到视锥坐标下的点云
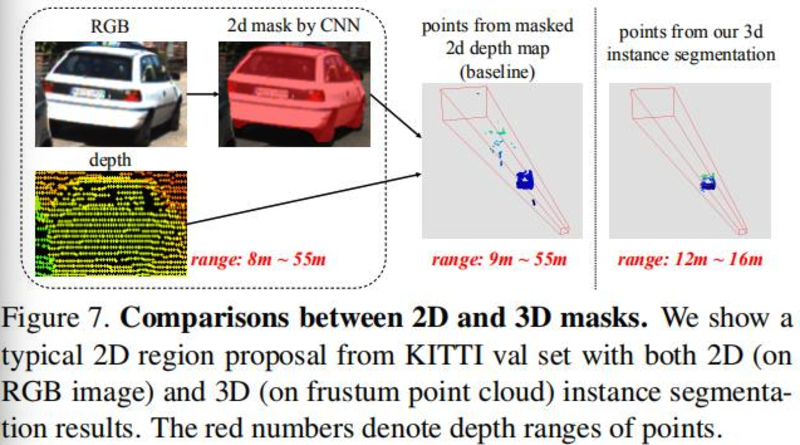
- PointNet进行点云的精确分割
- T-net+PointNet进行点云的两步定位
算法细节
- 其他细节:
- Corner loss:计算各corner点L1距离loss
3D box预测基于local coordinate
- 数据增强:在2d图上进行物体的翻转平移,对应三维视锥再进行点云的采样,翻转和平移操作
- 缺陷:
- 比较依赖于2D detector性能
- 同一视锥下的不同物体难以检出
- 消融实验: