目录
论文背景以及基本思想
论文出发点:本文基于F-PointNet的思想,认为F-PointNet非端到端,最终3D Box的预测强依赖于3D点云的分割结果,前置模块的点云缺失会造成后期预测不准确。
算法基本流程
- 核心点:
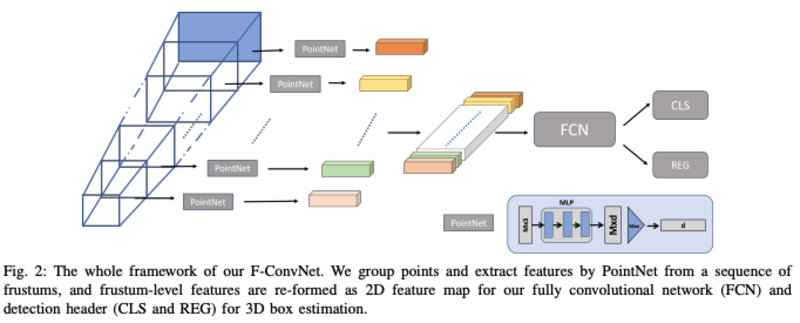
- 将2D detection的结果得到的视锥等分为T个部分,对所有视锥部分进行PointNet特征的提取,组成2D的feature map(L*d)通过FCN(kernel:3*d)网络进行每个部分的box分类和位置预测
- 视锥分割采取多组stride,在网络不同阶段进行多尺度的融合
整体框架图:

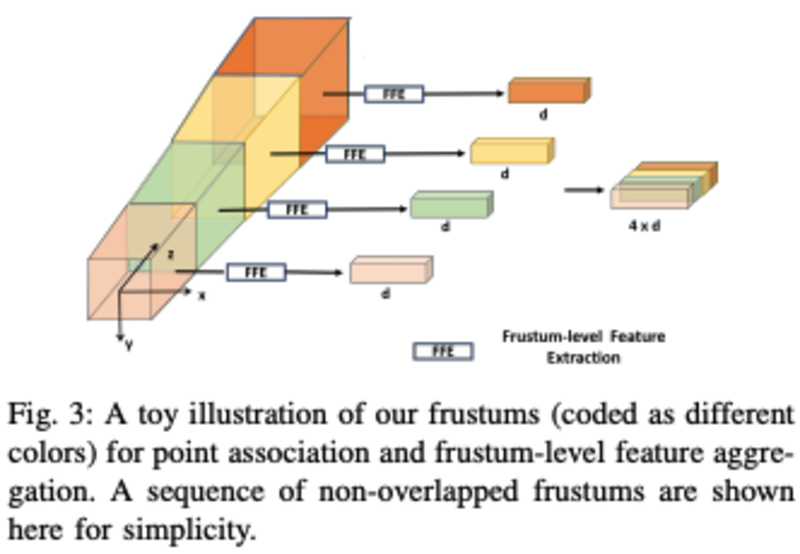
视锥的划分,通过不同stride产生的feature进行融合:
- 多尺度进行feature的融合:

算法细节
其他细节:
- 采用Focal loss平衡foreground和background
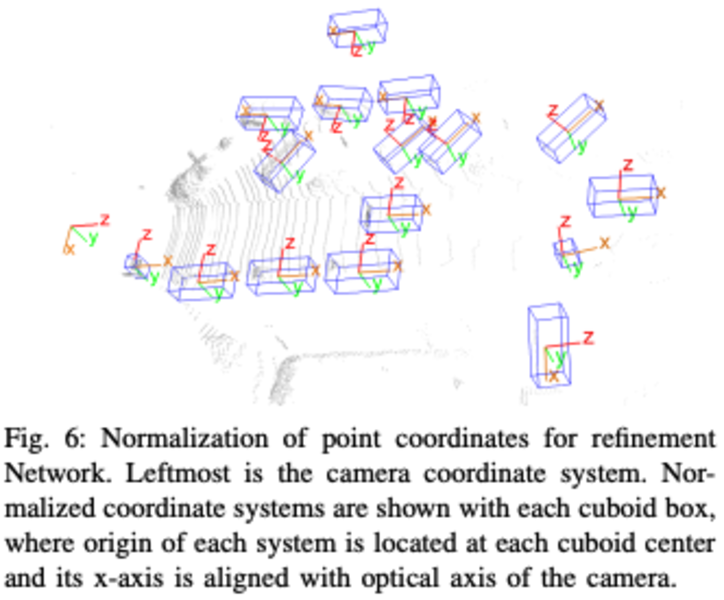
Final refinement:在得到3D box的输出后,将预测得到的3D box进行expand和normalization(将框扩大factor倍(1.2),方向不变),然后将这些框内的points再次作为网络的输入,进行二次的refinement,结果显示refinement的提升很大(+2Ap以上):
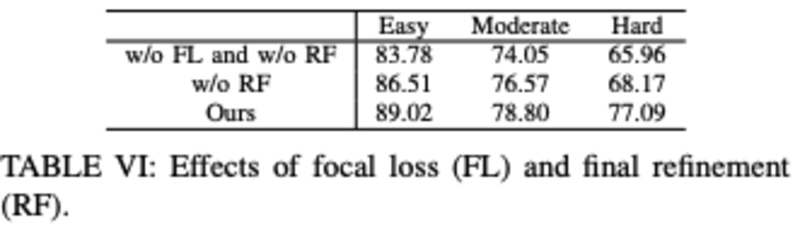
- 消融实验:focal loss和refinement: