目录
Deep Continuous Fusion for Multi-Sensor 3D Object Detection
论文背景以及基本思想
出发点:作者认为Lidar数据与Image数据融合的难点在于怎么将稀疏连续的三维点云信息与语义丰富但是离散的图像数据融合,提出了基于连续卷积的point-wise Fusion的方式进行BEV和Image的深度融合
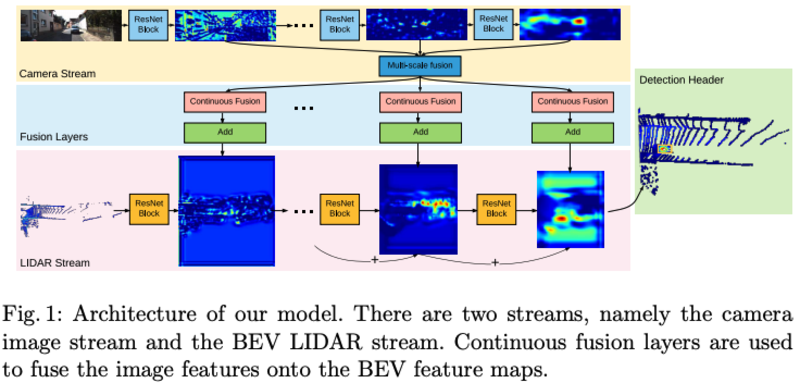
算法基本流程
- 核心:
- Fusion Layers的建立:输入为resnet18四个block的输出Image feature,通过FPN进行combine。融合方式为在BEV 2D plane上找到目标像素的K个邻近点,然后映射到3D空间对应3D点,然后得到3d位置和Image feature(插值得到),最后输入MLP得到融合的feature
- BEV branch最后一层Feature用于最后的分类和预测,会combine之前的三个block的feature(类似FPN)
- 算法框架:
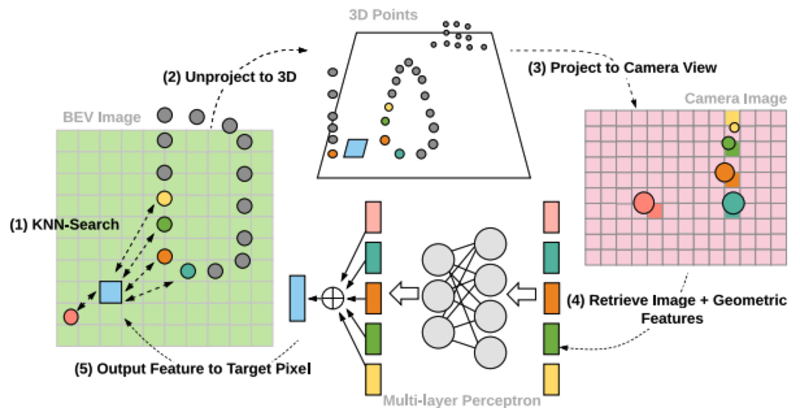
算法细节
- 关键点:
- Feature extractor的过程对每个block进行point-fusion
- 输入BEV 维度更高:512*448*32
- negative sample策略:随机sample 5% 取 top-k
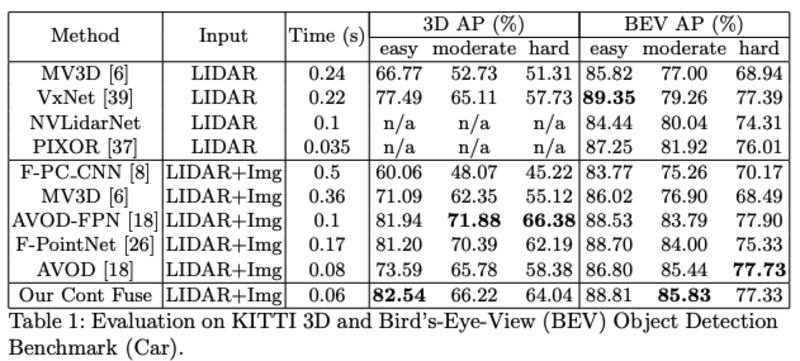
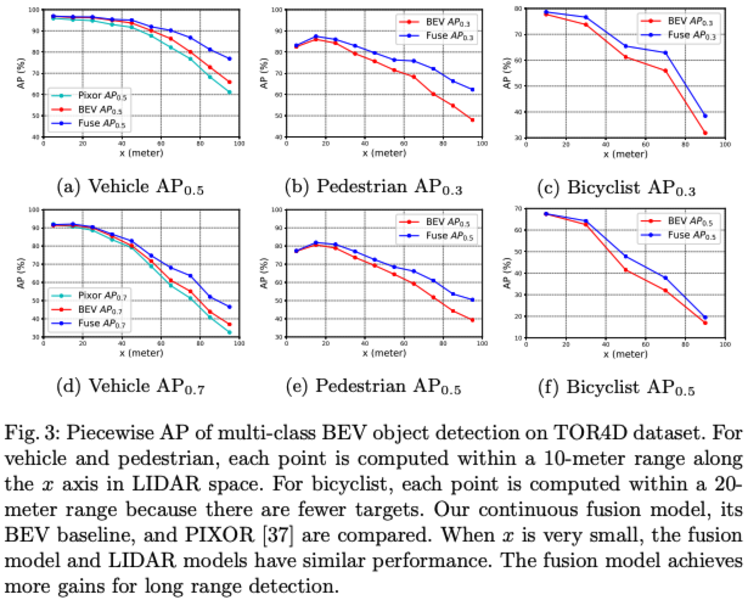
- 论文结果:作者称远距离的的detection结果变好(>60m),因为远处稀疏的点云信息得到了image信息的补充