前言
浅谈 BERT 系列网络,主要从三个维度介绍:发展历程、算法细节、后期发展。 背景知识: 自然语言处理(NLP):其最终目的是理解复杂的语言/文字,主要任务包括:
- 序列标注:如中文分词、词性标注、命名实体识别、语义角色标注等
- 分类任务:文本分类、情感分析等
- 句子关系判断:如QA,自然语言推理等
- 生成式任务:机器翻译、文本摘要、写诗造句等。
BERT发展历程
NLP本质是对语言/文字进行合理的数学表达,方便机器理解,其核心问题是怎么讲将语言文字转化为合理的“数学空间表示”。从最简单的one-hot编码到如今的BERT,都是围绕这一问题展开的:即如何学习现有的语料库(可能大部分是无标注数据),进行具体NLP任务中语言/文字的数学转换或者特征提取,而具体的任务可以认为是基于其特征的下游任务。NLP中的特征提取,类比CV场景,就是“预训练过程”,即基于 ImageNet 预训练的基础网络可以继续 finetune 供其他下游任务使用。NLP领域的预训练过程,通常采用语言模型技术(Language Model,核心是通过分析上下文来进行单词/句子的量化估计),该技术经历了几个技术发展阶段:
- NNLM(神经网络语言模型):最原始的应用神经网络解决NLP问题的模型,其算法思想是:对输入句子的单词进行one-hot编码,然后乘以矩阵Q转换为向量C,将拼接的句子向量接一层
hiddedn layer最后接softmax,预测下一个单词出现的概率。这里的向量C其实便是word embedding的结果。该结果相较于one-hot编码的优势是维度更低,且转换后的向量包含语义信息,比如语义更近的词,通常其距离会更小。 - Word2Vec:Word2Vec在NNLM上更进一步,NNLM其实本身是属于单词预测的语言任务模型,不是专门用于
word embedding。Word2Vec采用了和NNLM类似的网络结构,但是采用了不同的训练方法:CBOW(Continuous Bag-of-Words Model)和Skip-gram(Continuous Skip-gram Model),其中,CBOW是从句子扣掉一个词,然后根据上下文(context)预测这个词,而Skip-gram则是从单个单词去预测上下文。 ELMO(Embedding from Language Models):Word2Vec/Glove这类语言模型的局限在于无法解决单词多义的问题,即单个单词转换的到的向量值都是恒定的,而不能根据上下文体现多义性,如
play music和play football,play的含义是不一致的。ELMO采用的思路是添加上下文单词语义的embedding特征来对单一的word emdding特征进行补充,其基本结构如下:
ELMO输入为对应单词的word emdding,训练网络包含左右两部分“双层LSTM结构”。左边结构为从前往后的正向句子输入,右边为从后往前的逆向句子输入。其中两层LSTM结构对应的是句子的句法特征和语义特征。实际使用过程中,先基于ELMO得到句子的三类embedding特征,然后可以学习三类特征的各自权重,得到加权的最终特征后可以供后续下游任务使用。 ELMO的优点非常明显,引入LSTM/RNN并且通过双向输入补充前后文信息来解决多义性问题;其缺点在于LSTM/RNN结构无法并行,训练/推理效率低,且采用多个emdding特征组合这种非
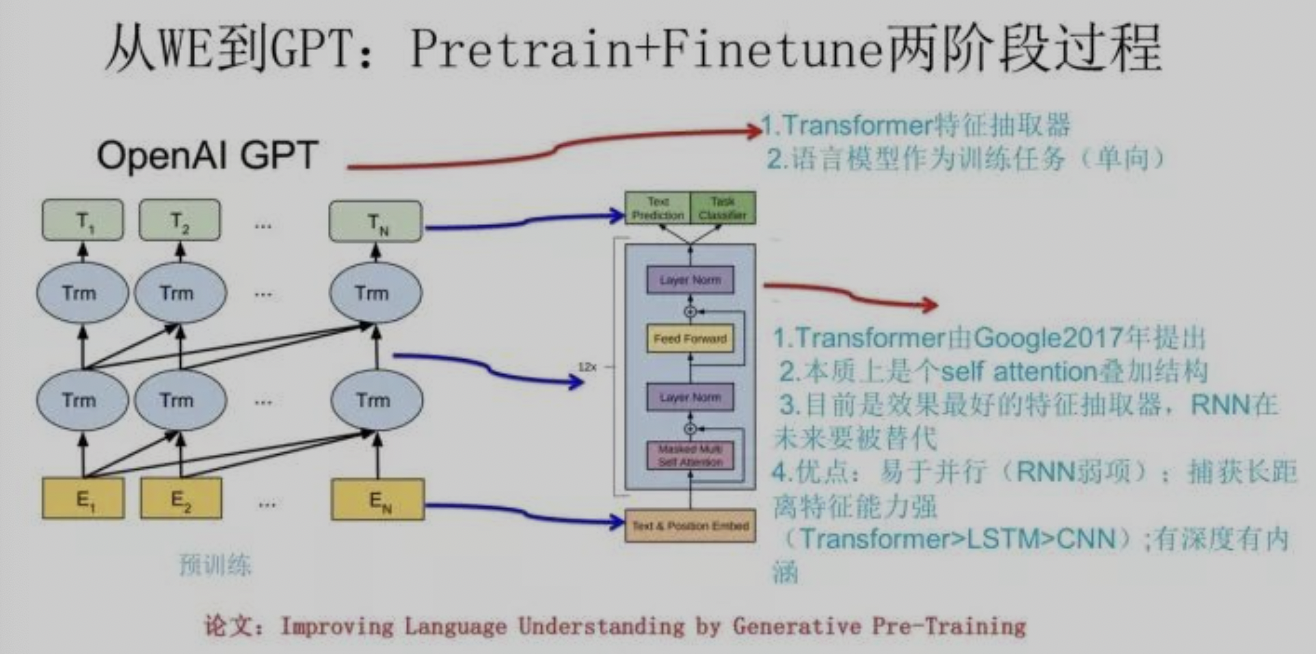
end-to-end的方式,效果不如后续一体化融合的方案好。GPT(Generative Pre-Training):GPT的结构最早将
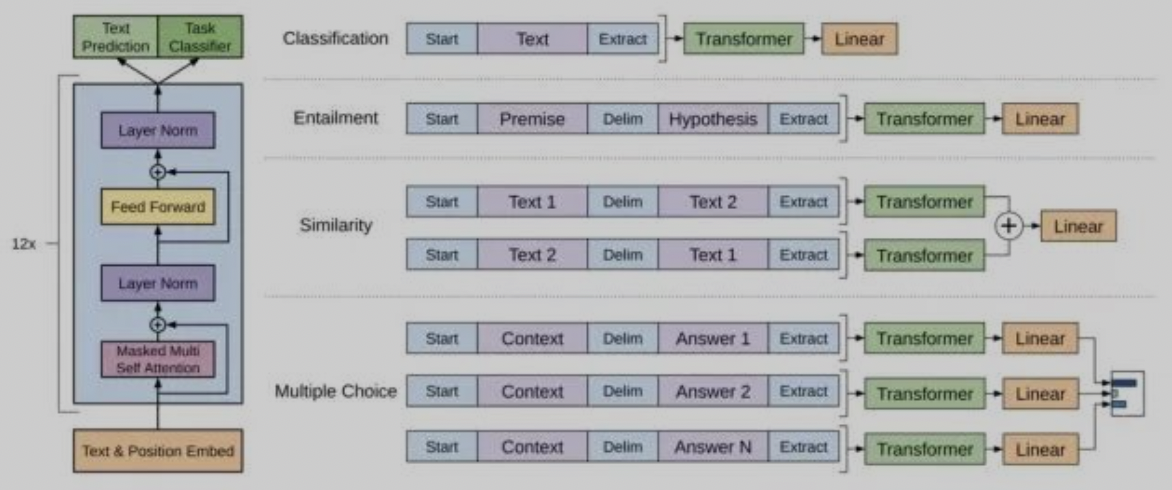
Transformer结构应用于语言模型中,关于Transformer的介绍可以参考 Transformer在CV领域的应用,其优势是提取长依赖特征更好,且并行效率更高。GPT的结构如下:从结构上看,GPT与ELMO的区别是:采用Transformer替代RNN;采用的是单向的结构(即只利用了上文信息);抛弃了ELMO的多个embedding特征的区分,GPT采用的是端到端的推理方式。关于最后一点,指的是GPT的下游任务需要基于GPT的原始结构进行设计,并采用GPT预训练得到的权重重新”finetune”,这点和CV场景很类似。GPT的几种下游任务网络推荐:
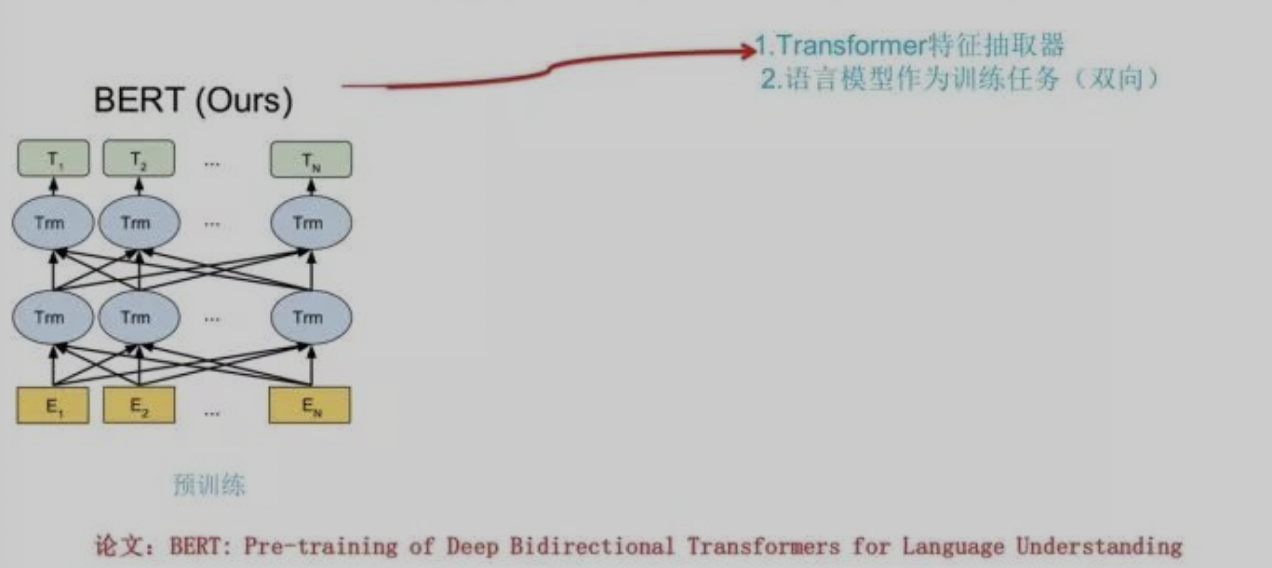
BERT:BERT可以认为是GPT的升级版,从结构上可以看出:
其区别在于BERT采用了双向语言模型结构(通过Mask的方式,设计思路上类似CBOW),添加了
Next Sentence Prediction多任务,且其训练规模更大。

BERT算法细节
BERT网络结构的基本组成单元为 Transformer 结构,前文介绍了Transformer的基本原理和结构。这里做下Attention机制的补充说明: Transformer结构中的q/k/v的Attention机制,其实来源于 寻址(Addressing) 的概念:给定一个和任务相关的查询Query向量q,通过计算与Key的注意力分布并附加在Value上,得到最终的Attention value。而 self-Attention 的区别在于,q/k/v的值都是基于自身输入的变换(矩阵乘法得到)。Transformer中的encoder-decoder结构包含了 self Attention 和 encoder-decoder-attention ,同时添加了位置编码信息和mask信息(方便双向训练): 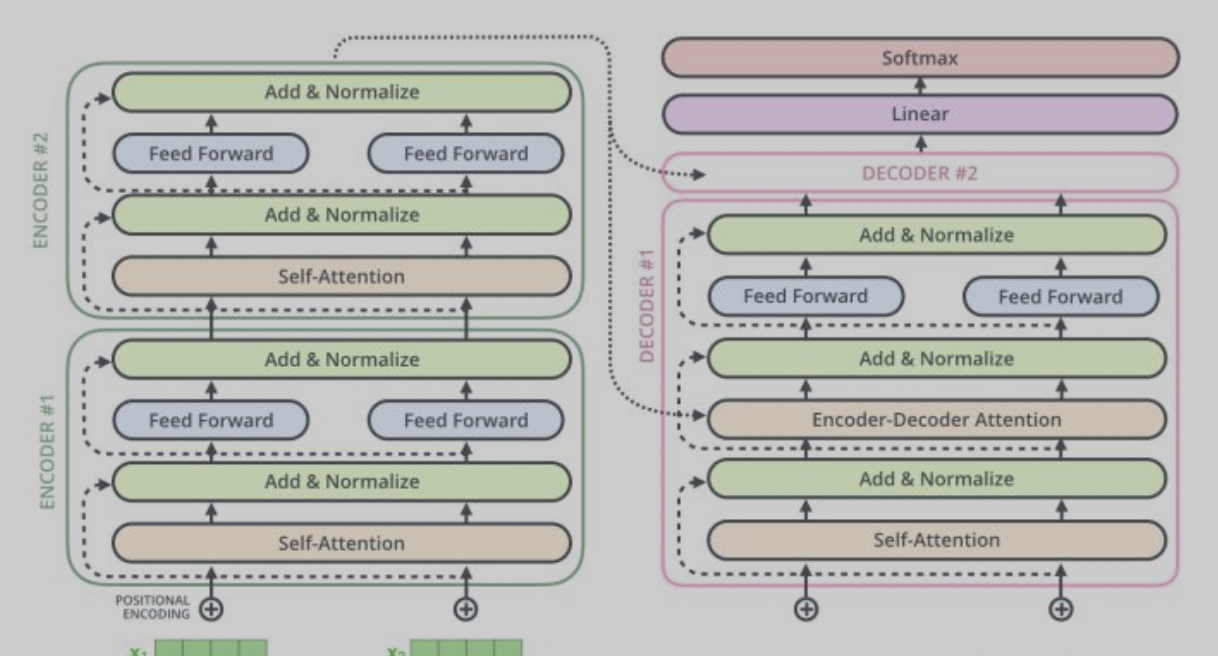
BERT基于Transformer的改进在于:
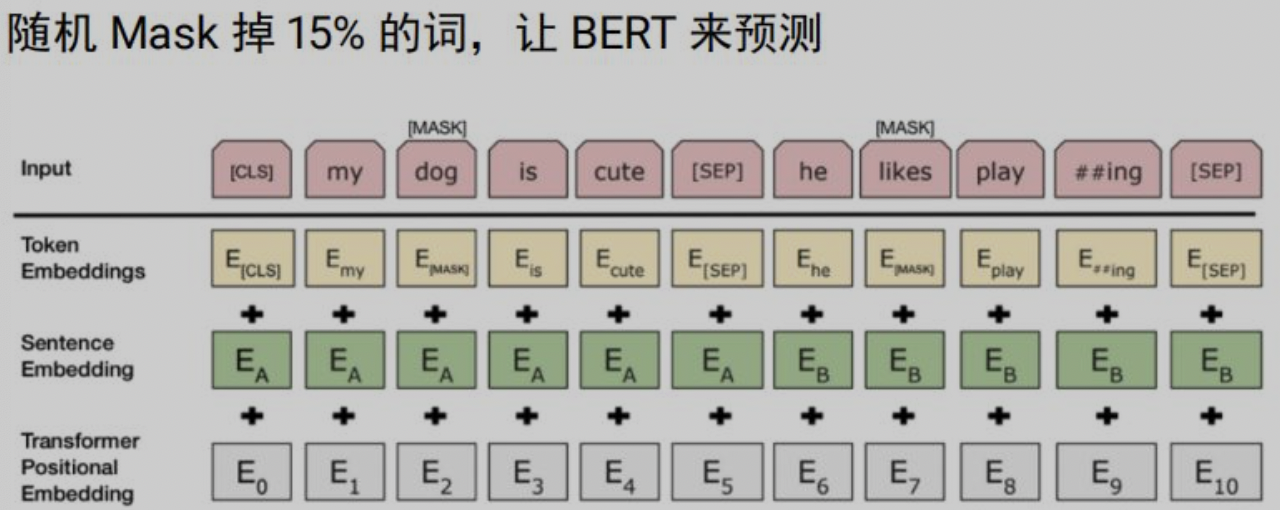
无监督的训练方式:原始transformer模型训练没有考虑无监督训练,通过Masked LM方法,随机Mask掉15%的词来让BERT进行预测,同时也解决了只有上文信息的问题。
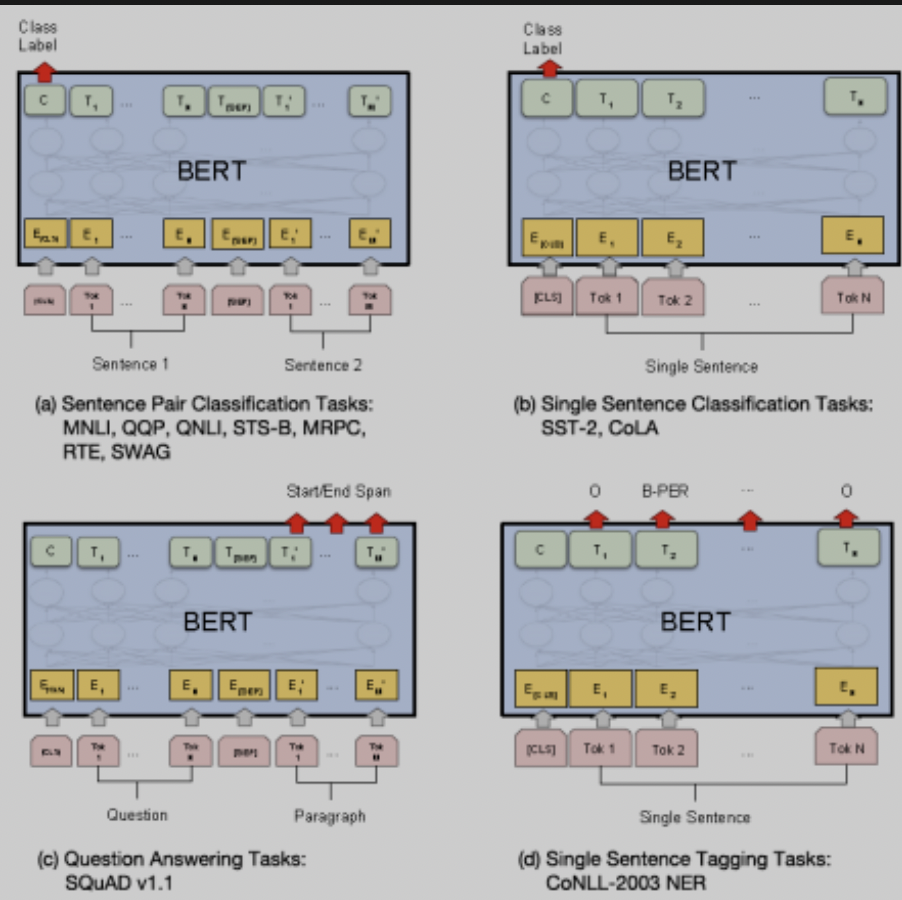
多任务训练:BERT输入为两个句子,通过分隔符sep进行分割,通过添加segment embedding进行区分。训练中进行句子的选取:50%概率抽连续句子,作为正样本;50%概率抽随机句子,作为负样本,该任务作为问答场景很适用。 BERT的下游任务适配:针对不同的NLP任务有不同的使用方式,具体可见下图。BERT的优点在于:实现了真正的双向,解决了多义性的问题;并行计算,效率很高;迁移性强,易于适配下游任务。
BERT后期发展
BERT之后,衍生了各类改进版BERT,具体维度主要包括:改善训练方式、优化模型结构、模型小型化等,以下介绍几个经典的模型:
- XL-Net:主要采用了更好的训练方式:采用AR方式,避免了mask标记位(导致了finetune和pretrain训练不一致带来的误差);替换transfomer为transfoermer-XL。
- ELECTRA:提出了新的预训练任务和框架:原始的Mask LM方式替换为判别式的Replaced token detection任务,采用了对抗训练的方式。
- ERNIE:采用了更好的mask设计;采用了更多的语料(知识类的中文语料)进行预训练。
- RoBERTA:改进了训练方法:改变mask的方式;丢弃NSP任务;优化超参;采用更大规模的训练数据。
- ALBERT:重点在于减少内存的网络设计:对Embedding进行因式分解;跨层的参数共享(全连接层和attention层都进行参数共享);优化了训练方式(去除了部分task和dropout层)。
- TinyBERT:设计更小的transformer结构,并专门设计了transformer蒸馏的方式保持精度。
参考资料
从Word Embedding到BERT模型-自然语言处理中的预训练技术发展史