前言
通常来说,单一检测模型往往无法覆盖所有的场景;对于不同场景采用的不同的检测框架/训练数据/训练策略也是非常重要的。本文笔者简单归纳了几种常见的检测场景,并介绍该场景下一些通用的检测Tricks:
- 样本不均衡场景
- 小物体检测场景
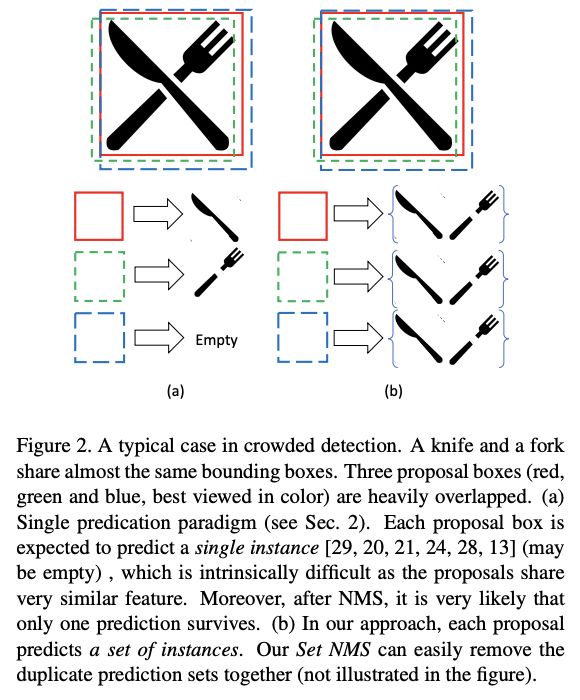
- 密集遮挡场景
详细介绍
样本不均衡
常见Hard Example策略
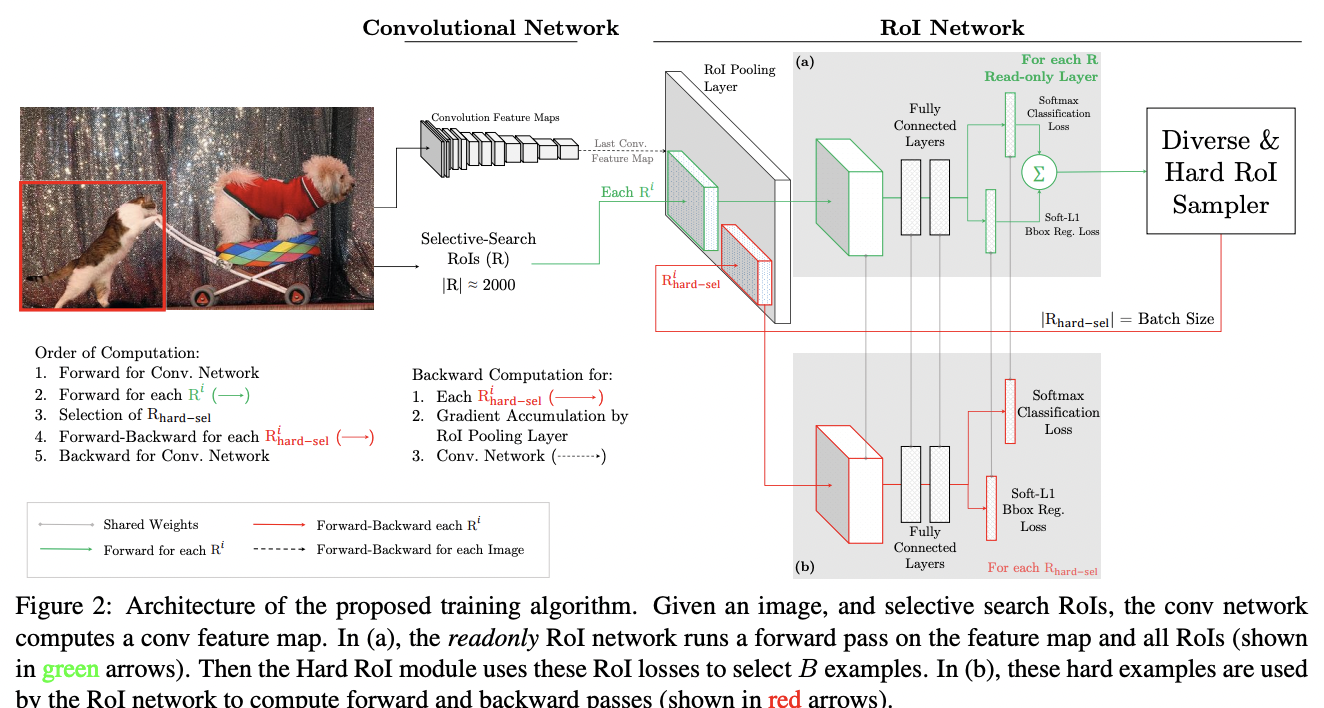
OHEM (Online Hard Example Mining)最早提出自Training Region-based Object Detectors with Online Hard Example Mining,其核心是选择 hard example 作为训练的样本从而改善网络参数结果。其中, hard example 的选取是通过样本的损失得到的。但是直接依据loss选取的问题是存在大量重合的正例,所以作者采用来 NMS 后的结果:认为阈值大于0.7即为重合率高,需去除。 以 Faster RCNN 为例,将 Fast RCNN 的 ROI network 分为两个部分:其中一部分为只读的网络,仅支持网络的推理;另一部分支持网络的前向和后向推理。实际训练过程中,先通过只读网络进行前向推理,得到所有ROI的loss,然后通过 hard ROI sampler 根据损失得到 hard example ,然后将这些 hard example 作为训练的 ROI nerwork 输入。其网络结构如下:
Focal Loss及其变种
关于 Focal Loss 及变种,可参照:2D_Detection-Loss,核心是通过基于分配难度不同的对象的loss,来调整训练的倾向,即在后期 hard case 会被较多的关注,从而提升性能。
小物体检测
对于One-Stage检测算法框架,简单分析小物体检测性能较差的原因:
Feature Map尺寸问题:Feature Map在进行数据下采样会造成小物体的特征损失。Anchor分配问题:小物体在Anchor分配上,同等条件下匹配到的正例更少。
可参考: 2021小目标检测最新研究综述,里面较为全面地阐述了小物体检测上的研究。 Awesome Tiny Object Detection,里面收集了比较全面的论文和数据集介绍。
如何融合多尺度特征
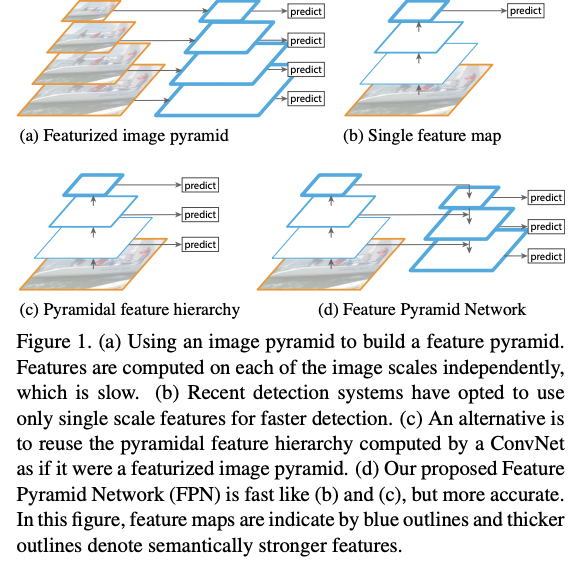
融合多尺度特征是常用的提高小物体检测能力的方案,最经典的算法框架便是RetinaNet。 RetinaNet 采用了FPN的的网络结构设计,其设计核心通过大小 feature map 的特征融合实现高语义和大尺度的特征融合,网络结构如下:
另外 feature map 的融合主要在 backbone 层面,其中 DetNet 在基于传统 FPN 基础上进行了优化,可参考:2D_Detection-Backbone(DetNet)
脱离bbox看待问题检测
基于bbox的物体检测,不可避免会引起 Anchor竞争 的问题,可以基于优化 sample策略 和 数据增强 的方式来改善。另外,也有一些方案抛开基本的bbox检测方案,而是从其他角度:工程侧/非bbox方案。
工程侧(可能这个说法不是很严谨)指的是从实际部署的角度看待小物体检测物体:小物体是相对于大图片输入而言的,那么可以通过裁剪输入图片形成大物体来解决小物体检测miss的问题,同时在最后的大图上做最后一轮 nms 操作。当然,该方案必然会引起速度的下降,具体实现可参考:You only look twice。
非bbox的方案设计主要是为了避免 Anchor 层面的问题,最常见的思路便是在较大的 Feature map 上基于 Key points 进行检测,然后基于关键点得到最终的检测框。典型算法框架有CornerNet,CenterNet等
密集遮挡场景
nms引发的问题
主要是将各个重叠的box清理,得到score最高的主要box,代码步骤实现:
- 将所有的box框根据score进行升序排列
- 判断box序列是否为空
- 保存当前的box序号
- 计算最高score与其余的box的iou
- 将iou大于阈值的box去除,得到余下的box序列
- 更新box序列
简单NMS的缺陷在于: 可能会直接过滤掉得分低且重叠度高的边框可能会导致漏检,尤其是在一些拥挤/遮挡的场景. 基于简单的 NMS 的改建方案有:
- soft_nms 传统的nms对于多个物体重叠的情况来说,会把低分的物体过滤掉,处理过于粗暴;
soft-nms的方法是将计算得到的iou和box本身的score的输入参数,重新计算box的置信度,最后根据新的置信度判断是否去除这个box - softer_nms 在训练中引入了描述定框准确度的分支(通过预测值和GT值的KL散度进行约束),然后将预测得到的定框置信度作为nms判断的权重。
softer nms的定框置信度的分支其实于QFocal loss/IoU Branch都有类似的地方(后文会介绍)。
如何让定框变得准确?
IoU Branch && Centerness
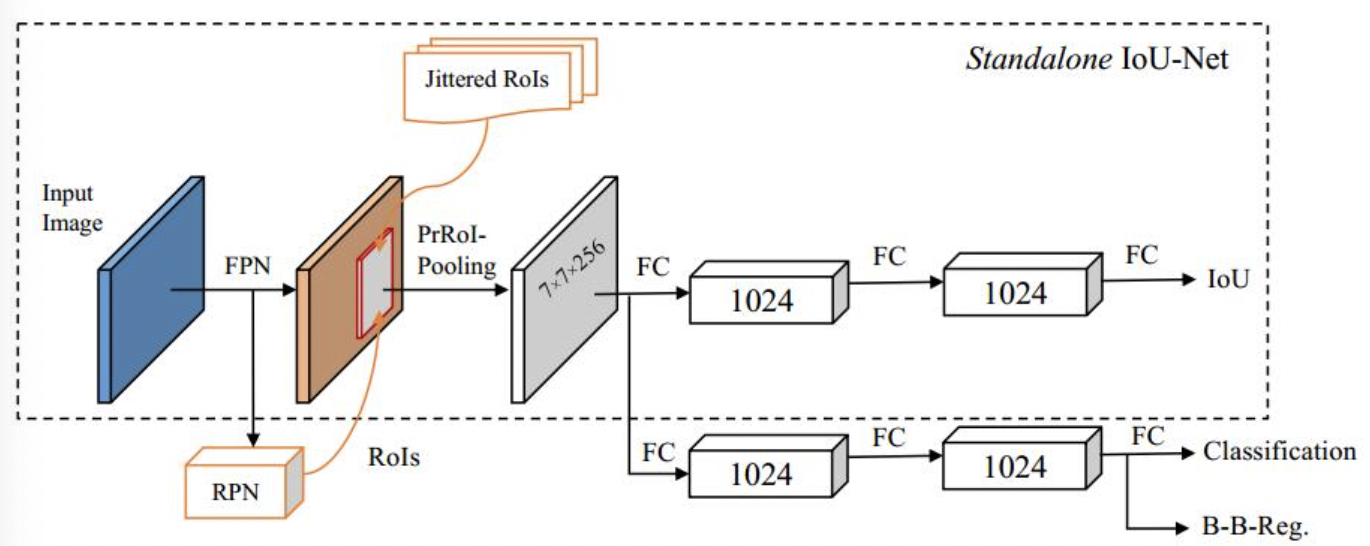
IoU Branch和Centerness的设计目的都是通过添加额外的分支来进行定框置信度(或者定框质量)的评估,结合分类分支/回归分支来得到更加准确的定框。IoU Branch的设计最早由IoU Net提出,IoU Net的网络结构可见下图。其能预测检测到的边界框和它们对应的真实目标框之间的IoU,使得该网络能像其分类模块一样,对检测框的定位精确程度有所掌握。推理过程,预测得到的IoU可以作为后置NMS的筛选机制。
\[centerness^{*} = \sqrt{\frac{min(l^*, r^*)}{max(l^*, r^*)}*\frac{min(t^*, b^*)}{max(t^*, b^*)}}\]Centerness出自FCOS,其本身为Anchor-Free检测算法。其添加了centerness分支(与分类分支平行),提高检测框的预测质量,其centerness定义如下:QFocal Loss
QFocal Loss出自Generalized Focal Loss,其核心在于基于Focal Loss的基础上结合了centerness的定义,相当于将FCOS中的classification分支和centerness分支合并一起优化,详情可参考:2D_Detection-Loss。

怎么解决高度重叠的场景?
物体高度重叠的物体检测性能下降,其核心原因在于 Anchor 分配的问题:
对于多层 Feature map 的 Anchor 分配,最基本的便是基于不同层的 Anchor尺寸 进行对象的匹配,另外一种比较经典的分配方式便是根据大小和中心点位置进行分配,可参照FCOS。
对于单层 Feature map 上的 Anchor 分配问题(较为常见,也是更难解决),一种比较经典的解决方式是修改同位置的 Anchor match 方式来实现单个 Anchor 实现匹配多个物体。其实现细节:修改原始的 max iou 的匹配方式,而是采用 TopK 的方式来进行匹配,从而在拥挤场景,单个 Anchor 能够预测得到多个物体,可参照One Proposal, Multiple Predictions,其匹配效果: