前言
本文简述2D检测算法中经典的算法框架,该领域过去涌现了很多论文和框架,无法一一追踪。但是大部分新算法还是基于经典的算法框架上进行延生和拓展。 当前目标检测框架按照算法流程上看主要分为两个派别:One Stage和Two Stage.其中One Stage的代表算法有YOLO,SSD;Two Stage则以RCNN系列为主. Google基于Tensorflow实现的主流检测算法性能结果: 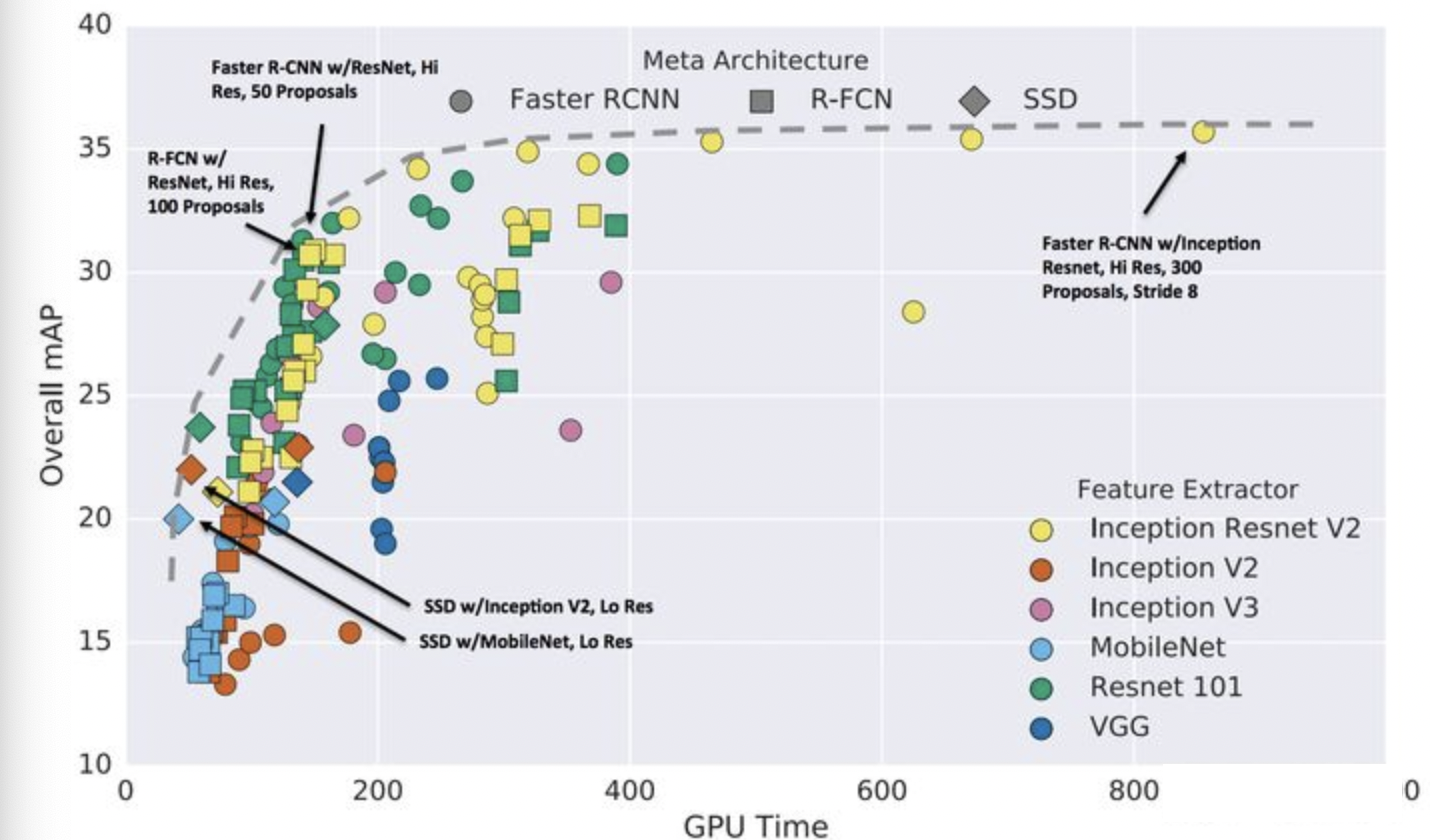
backbone对性能的影响: 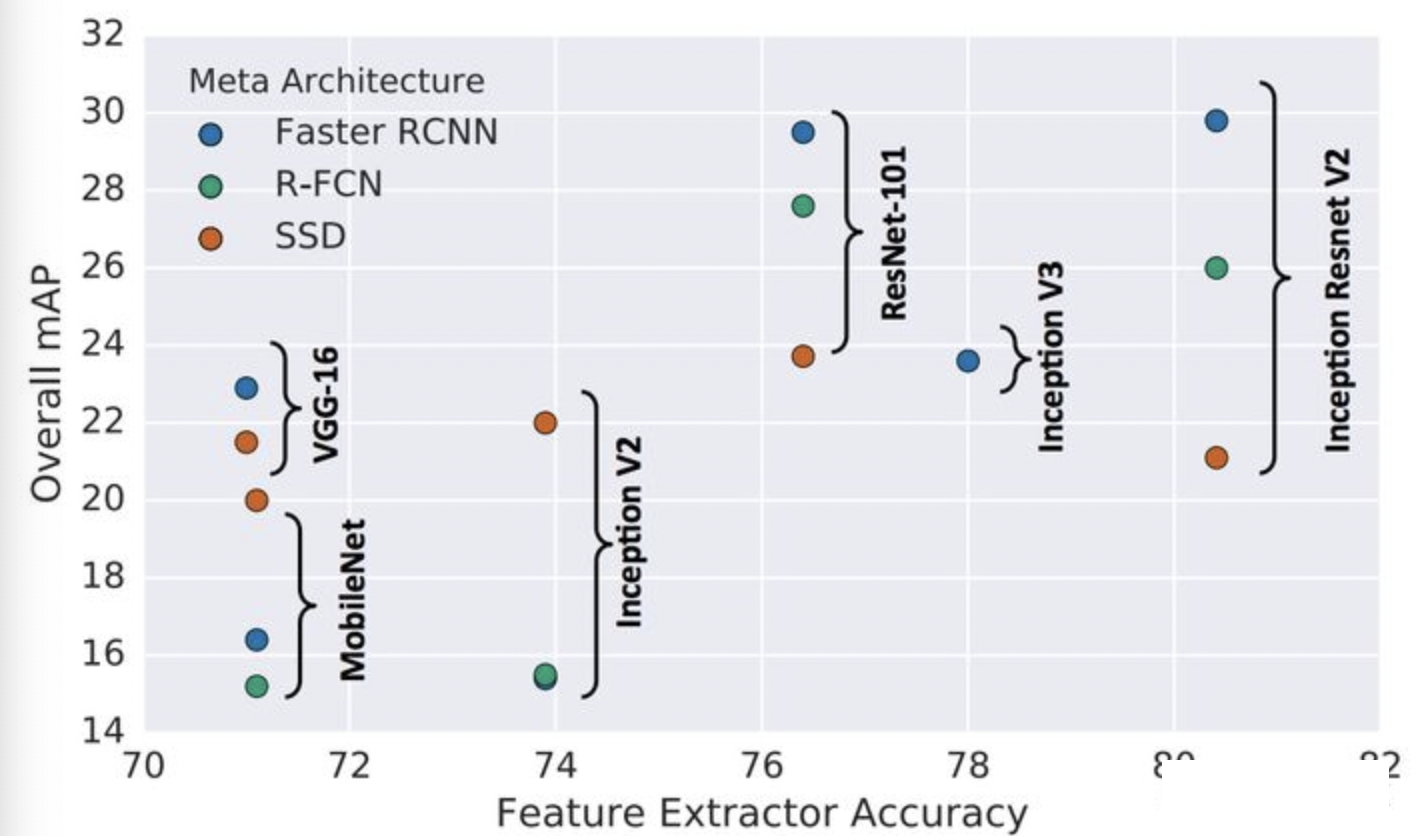
物体尺寸的影响: 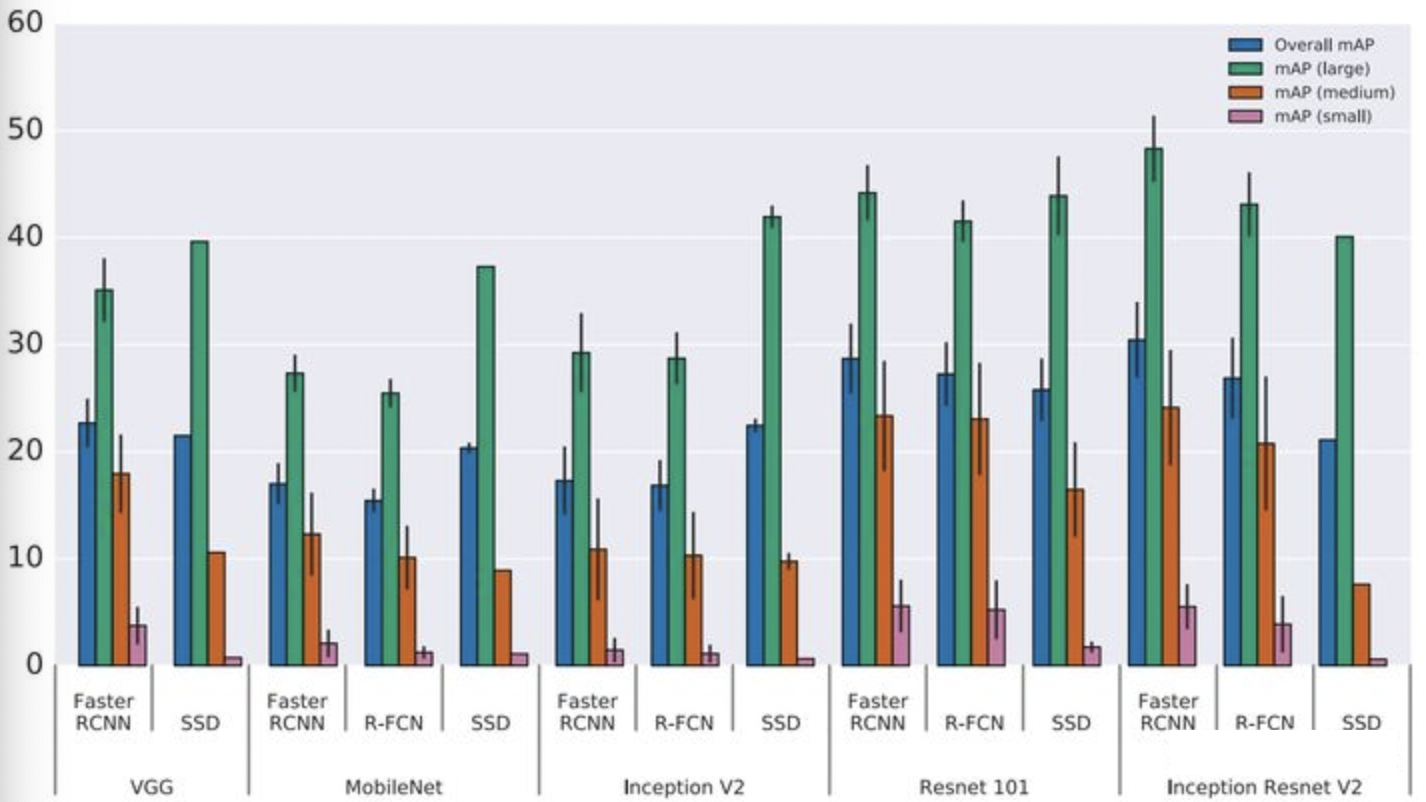
整体上看,精度上看Faster-RCNN的精度最高,且采用更好的backbone性能提升幅度也更大.速度最快的为SSD+MobileNet的组合,但是SSD的小物体检测性能较差. 后续也有一些基于 Anchor Free 的算法框架提出,这里也会略作介绍。
Two Stage算法
RCNN系列
RCNN系列经历了RCNN->Fast RCNN->Faster RCNN的变迁,最终的Faster RCNN可以认为是Two Stage的集大成者,这里也仅重点介绍下Faster RCNN的算法设计.
Faster-RCNN总览
Faster-RCNN从功能模块来看,可以分为4个部分:
- 特征提取网络(Backbone):输入图像通过Backbone得到特征图.
- RPN模块:区域Proposal生成模块,其作用是生成较好的建议框,这里利用了强先验的Anchor.RPN包含了5个子模块:
- Anchor生成:RPN对feature map上每个点都对应生成9个Anchors,9个Anchors的大小宽高都不一致,几乎能够对应覆盖原图中的所有大小的物体.RPN的工作比那时从中筛选得到更好的Proposal位置.
- RPN卷积网络:feature map上单个点上对应9个Anchors,可以通过卷积网络得到每个Anchor的预测得分和偏移
- 计算RPN loss:RPN阶段Anchor的标签分配只有正样本,负样本.RPN loss对每个Anchor的预测值包括两个部分:正负样本分类损失和预测偏移值损失.计算loss中,RPN默认随机选择256个Anchors进行损失的计算,其中最多不超过128个正样本,如果数量超过128,则进行随机选取.
- 生成Proposal:利用前置步骤得到的Anchor的的得分和偏移量,得到一组较好的Proposals
- 筛选Proposal得到最终RoI:训练过程中,现有Proposals数量还是过多(NMS去重后,按照score排序,默认2000),需要进一步筛选Proposal得到RoI计算loss(默认数量为256).infer过程中,不需要此模块,Proposal直接作为RoI(默认为300).训练过程中的筛选过程与计算RPN loss过程类似.其正负例的筛选标准:最大IoU大于0.5,则认为正样本;最大IoU大于0且小于0.5,则认为负样本.正负样本的总数为256,控制正负样本为1:3,即正样本的数目为64,负样本数目为192.
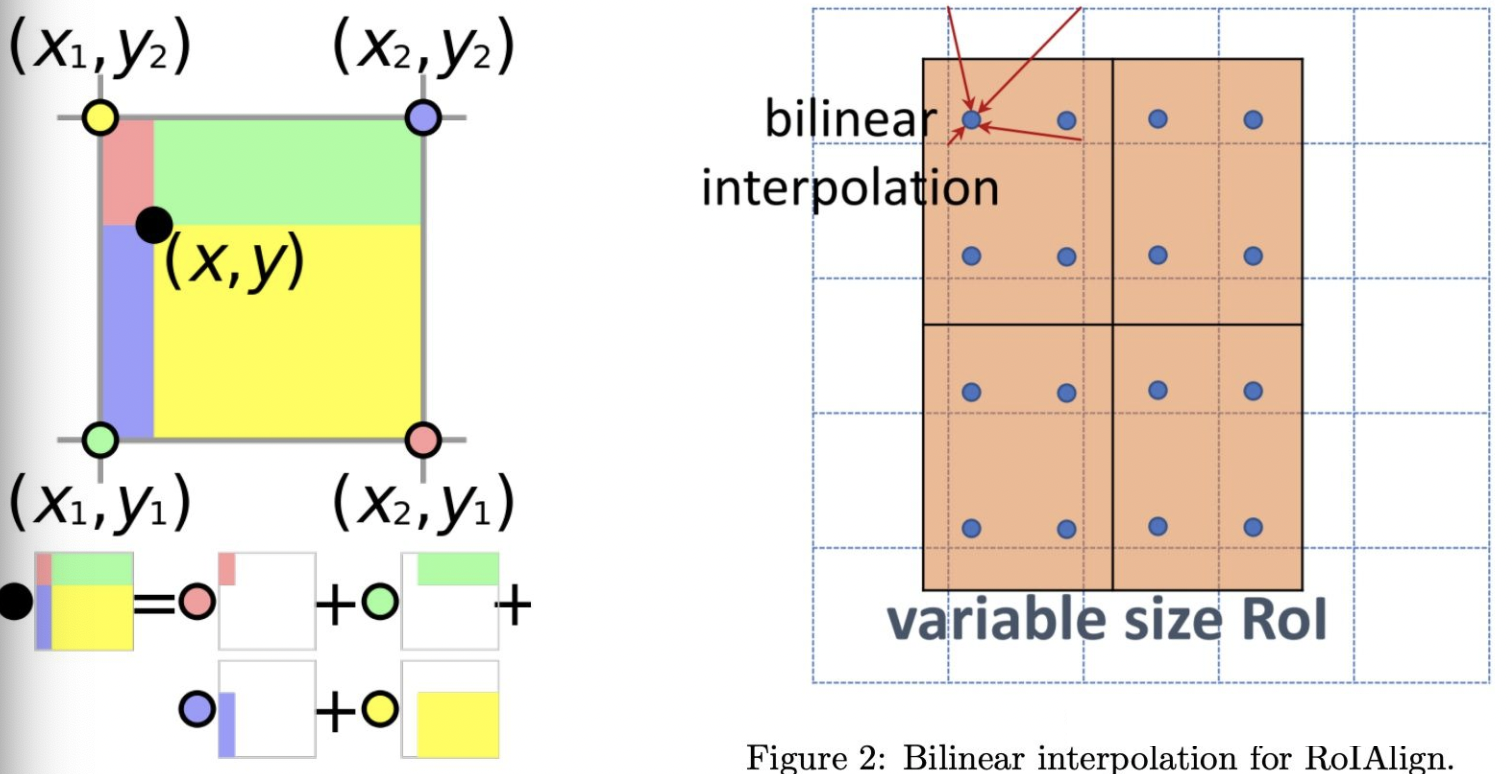
RoI Pooling:RoI Pooling的作用是将大小不同的RoI区域转化为固定大小的特征输入.最早应用于SPPNet,在Fast RCNN中采用最近邻差值算法将池化过程进行了简化,而在随后的Mask RCNN上则通过RoI Align提高了算法的精度.RoI Align相较于RoI Pooling不再进行取整操作,得到的RoI区域直接为浮点数格式边界,即得到的区域和feature map点区域不match.对于不match的区域,通过取每个bin的四个点特征值的最大值作为该bin的特征值.四个点的特征值则通过周围feature map的特征值差值得到:

- RCNN模块:经过RoI Pooling(RoI Align)后,得到了大小固定的特征,之后便可以通过全连接网络进行分类和回归预测量的计算.RCNN的loss计算和RPN的loss计算类似,只是分类loss为GT lable的loss,而不再是简单的正负例样本loss.
Faster-RCNN的算法框架图如下: 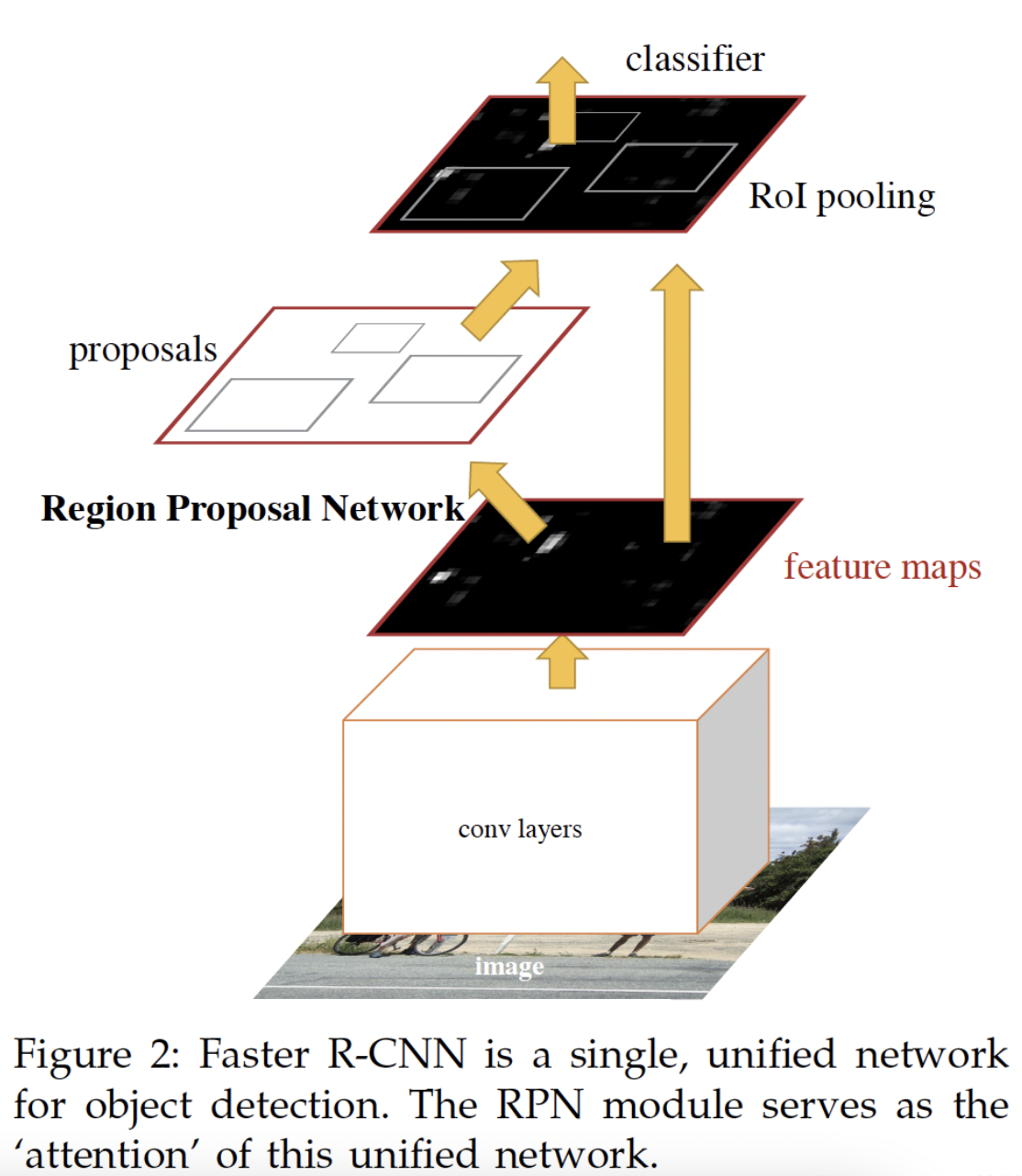
基于Faster-RCNN改进算法
Faster-RCNN算法作为Two-Stage网络,拥有较为优越的性能.但是仍然存在一些缺点:
- RCNN模块采用的是全连接网络,即所有RoI都会通过全连接得到,导致网络的计算量较大,速度较慢
- 后处理策略:NMS的后处理对于拥挤/遮挡场景不友好,容易造成漏检
- 正负样本的选取:当前正负样本采用的1:3的超参设计,但是该参数是否通用于其他场景,尚需讨论
R-FCN
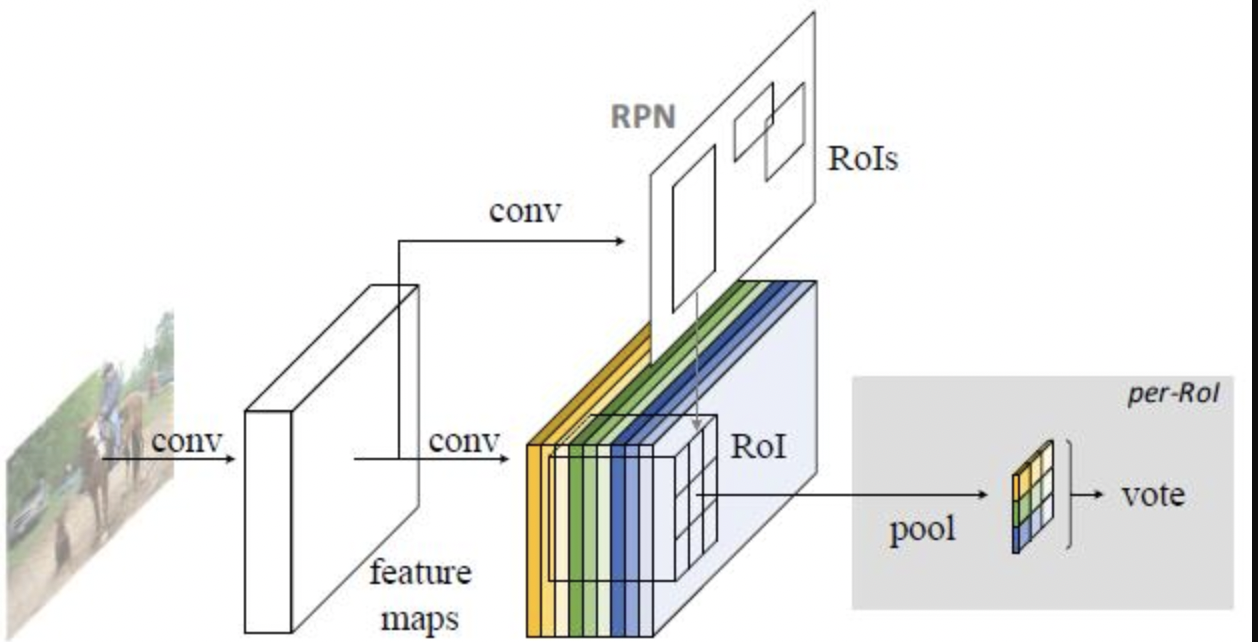
Faster RCNN采用了两个全连接网络提取特征,占据了大部分的网络参数.但是如果直接去除全连接,检测性能则会急剧下降,主要在于基础卷积网络具有平移不变性质,但是对于位置信息不敏感. R-FCN通过全卷积网络得到位置敏感得分图(position-sensitive score maps)实现了对位置的敏感性.R-FCN的算法框架图如下:
R-FCN的算法流程如下:
- 网络Backbone提取图像特征
- 通过全卷积网络基于特征图生成位置敏感图的score bank,假设设计目标的相对位置数量为k^2,则分数图数目为k^2*(C+1),C为类别数目
- 采用RPN网络得到RoI,然后将其分为k^2区域,并将子区域作为分数图
- 当k^2子区域都具备某类的目标匹配值时,则对该子区域求取平均值,同理得到每类的score,最终vote得到C+1维度的特征
- 对剩下的C+1维度进行softmax回归,进行分类
R-FCN的优势在于保持精度一致的情况下,速度明显优于Faster-RCNN.
Cascade RCNN
Cascade RCNN较为深入地探讨了IoU阈值对检测器性能的影响.作者提出了原始Faster RCNN在RPN阶段存在mismatch问题:
- training阶段,由于gt是已知的,所有可以取iou大于0.5的作为正样本
- infer阶段,gt未知,只能将所有的proposal作为正样本,通过score判断正负样本
所以,training阶段和infer阶段,bbox回归的输入分布是不一样的,该missmatch现象在threshold=0.5的时候问题不会太大.但是当threshold提高的时候,一方面missmatch现象会更严重,同时也会由于训练过程中正样本Proposal变少,导致模型过拟合. 因此提高检测位置精度,直接提高IoU阈值的方式是不合理的.作者的改进的思路主要基于两点:
- 当Proposal自身的IoU阈值和训练器用的阈值较为接近的时候,训练器的性能更好
- 经过回归后候选框与GT的IoU会有所提升.
Cascade RCNN的算法设计如下:
- 采用multi-stage的算法框架,每个检测stage采用不同的IoU阈值,且IoU阈值逐步变高
- 前一个回归网络的输出边框作为下一个检测器的输入继续回归,共迭代三次
整体算法框架如下:

One Stage算法
SSD
SSD算法框架: 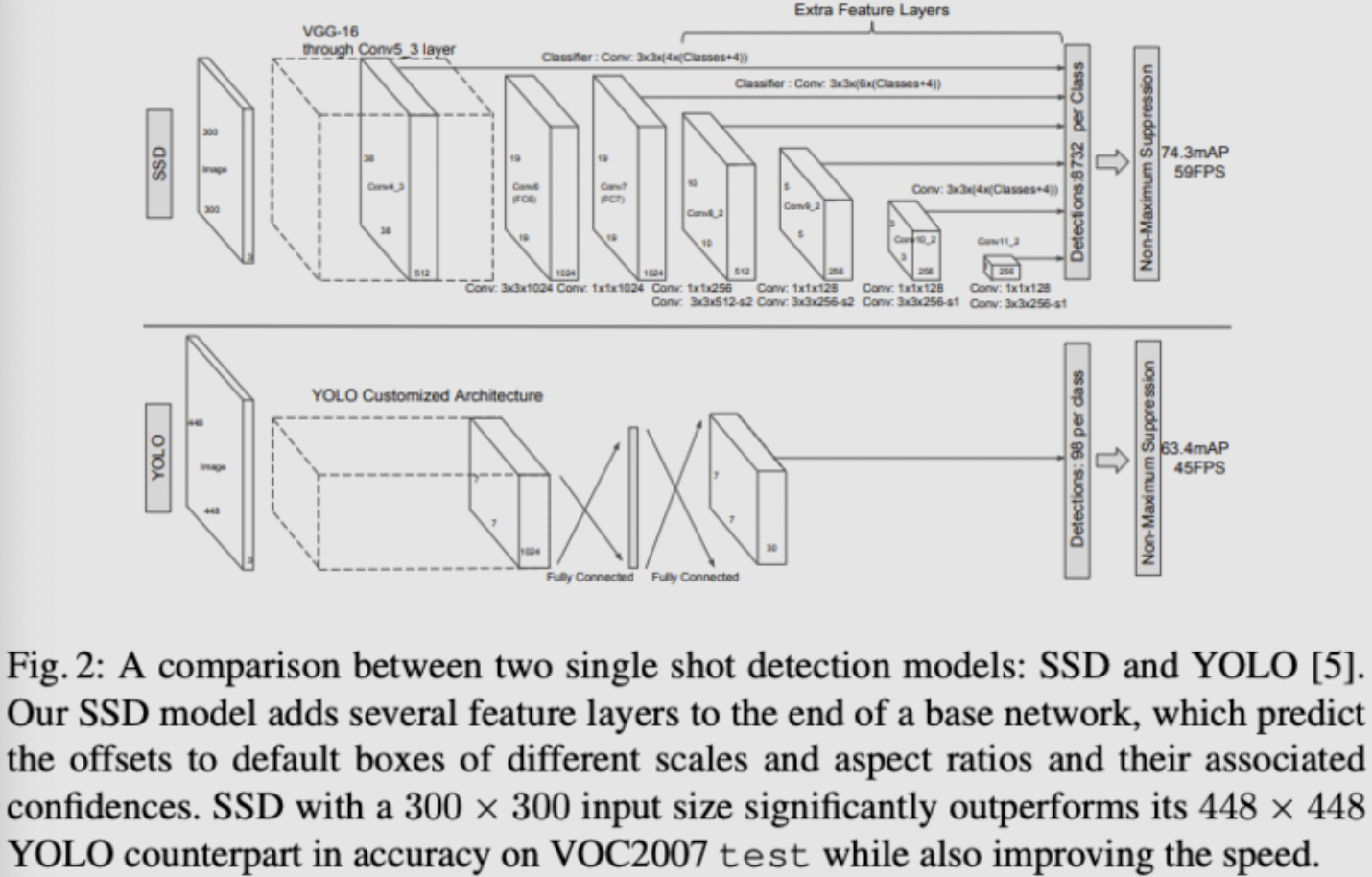
SSD模型主要分为以下几个部分:
Multi-scale feature maps for detection: backbone采用基础网络结构(VGG),本文修改了backbone的最后几层结构,同时引入了额外的卷积层用于抽取不同scale尺度的featureConvolutional predictions for detection: 对于每个feature map(假设size为mxnxp),通过3x3的卷积核生成预测value,包括预测位置的相对值(相对feature map像素对应的原图位置)以及confidence等Default boxes and aspect ratios: 每层的feature map设置有默认大小和长宽比的default boxes,feature map上的每个位置会基于deafault box作相对位置和大小的估计以及类别score的估计。对于size为mxn的feature map,其最终的预测结果为(c+4)xkxmxn,其中c为类别数目,4为位置偏移值和大小偏移值,k为default box数目(不同scale的feature map的k值有所不同,如conv10_2和conv11_2采用k=4,余下为6)。
算法细节:
Base network: 在VGG的基础上,进行了一系列的改动:fc6, fc7替换为卷积层,pool5替换2x2-s2为3x3-s1,同时采用空洞卷积,去除所有drop-out层和fc8层。Matching strategy: 区别于MultiBox,SSD对所有与GT的IOU阈值大于0.5的default box作为positive,即default box与GT是多对一的关系,而不是MultiBox的取最大IOU的一对一的关系Loss设计:Loss主要分为两个部分:localization loss和confidence loss:其中,N为匹配上的box数目,如N=0,则loss=0。localization loss采用的是
L1 loss,localization loss包括(cx,cy,w,h),即中心位置和宽,长四部分loss,confidence loss采用的是softmax loss。Choosing scales and aspect ratios for detection:不同尺度的ferature map拥有不同的感受野,所有应当设计不同大小的default box( 影响性能比较关键的点 )。SSD采用的default box大小设计如下:其中,s_min为0.2,s_max为0.9,长宽比设计为 $a_r={1,2,3,1/2,1/3}$
Hard negative mining:策略为按照confidence loss进行排序,保持正负样本为1:3Data augmentation:采用的ramdom crop策略( 非常重要 ):- 输入原始大小的输入图片
- 在输入图片上进行Sampel得到patch,满足与objects的最小jaccard overlap为0.1,0.3,0.5,0.7 or 0.9
- 随机Sample得到patch: sample得到的patch大小为[0.1,1],长宽比为1/2,2,保留中心点在sampled patch的box。得到的patch会被resize到固定size,并且采用horizontally flip(probability 0.5),photo-metrix distortions等增强。

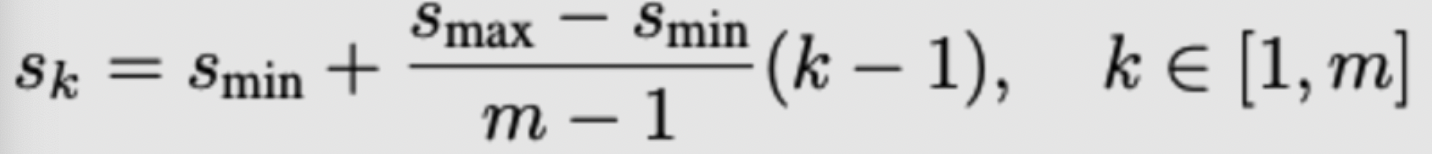
SSD算法作为One-Stage网络仍然存在一系列的算法限制:
YOLO
YOLO系列截止2021/2的发展:v1->v2->v3->v4->v5,其中v4,v5非YOLO原作,后期更多是算法的trick的叠加应用,这里重点介绍v1/v2/v3版本,v4/v5(updated on 8/29/2021)
YOLO V1
YOLOv1:
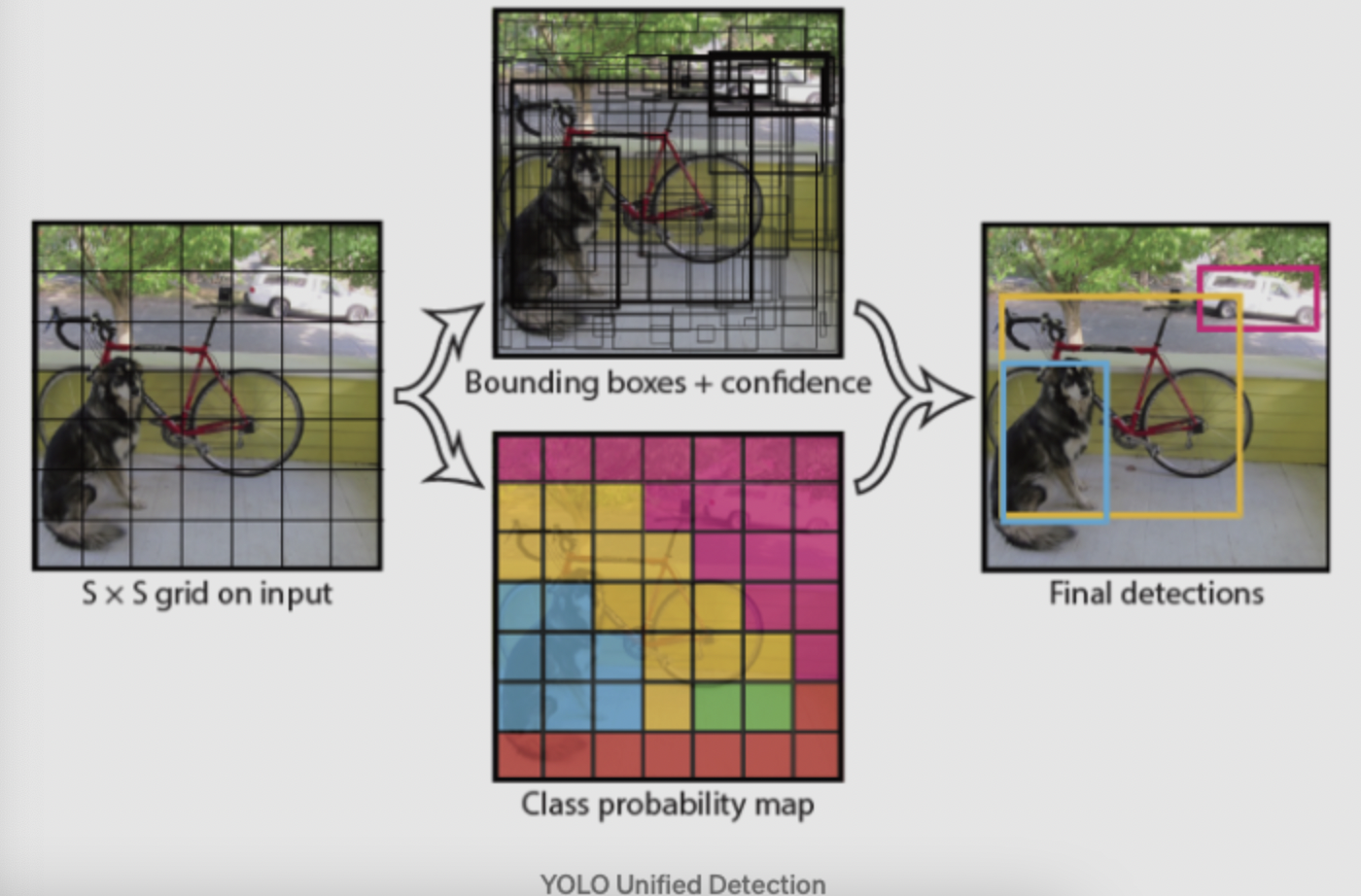
Unified Detection:YOLO将图片分为S*S的栅格,每个栅格对中心落在栅格内部的物体负责。每个栅格会预测B个bounding box,confidence信息和位置信息:x,y,w,h。
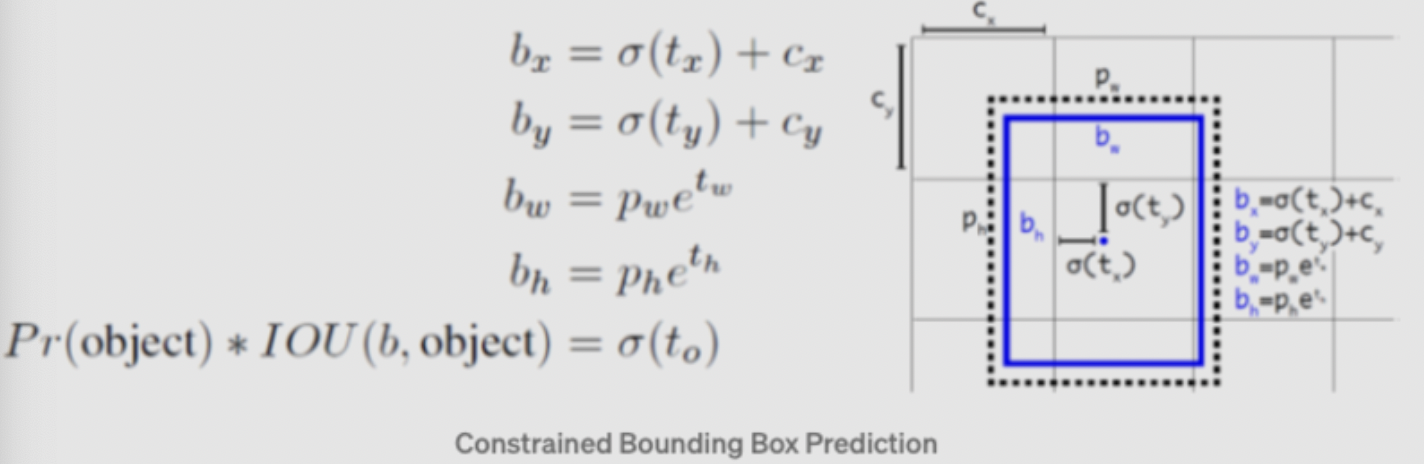
其中confidence信息表示为条件概率的形式: $confidence=Pr(Object)*IOU$ ,即如果bounding box预测无物体,则 $Pr(object)=0$ ,则confidence为0,如果预测有物体,则confidence为预测box和gt的IOU。
其中,x,y表示预测的bounding box的中心与栅格边界的相对位置,w,h表示为bounding box的width,height相对于整幅图像的比例。
另外每个grid cell还会预测c类的conditional confidence: $Pr({Class_i}|Object)$ ,infer过程中通过 $Pr({Class_i}|Object)*Pr(Object)*IOU$ 来作为bounding box的类预测confidence。
注意这里的class confidence只针对c个类,而bounding box的confidence则针对每个box:
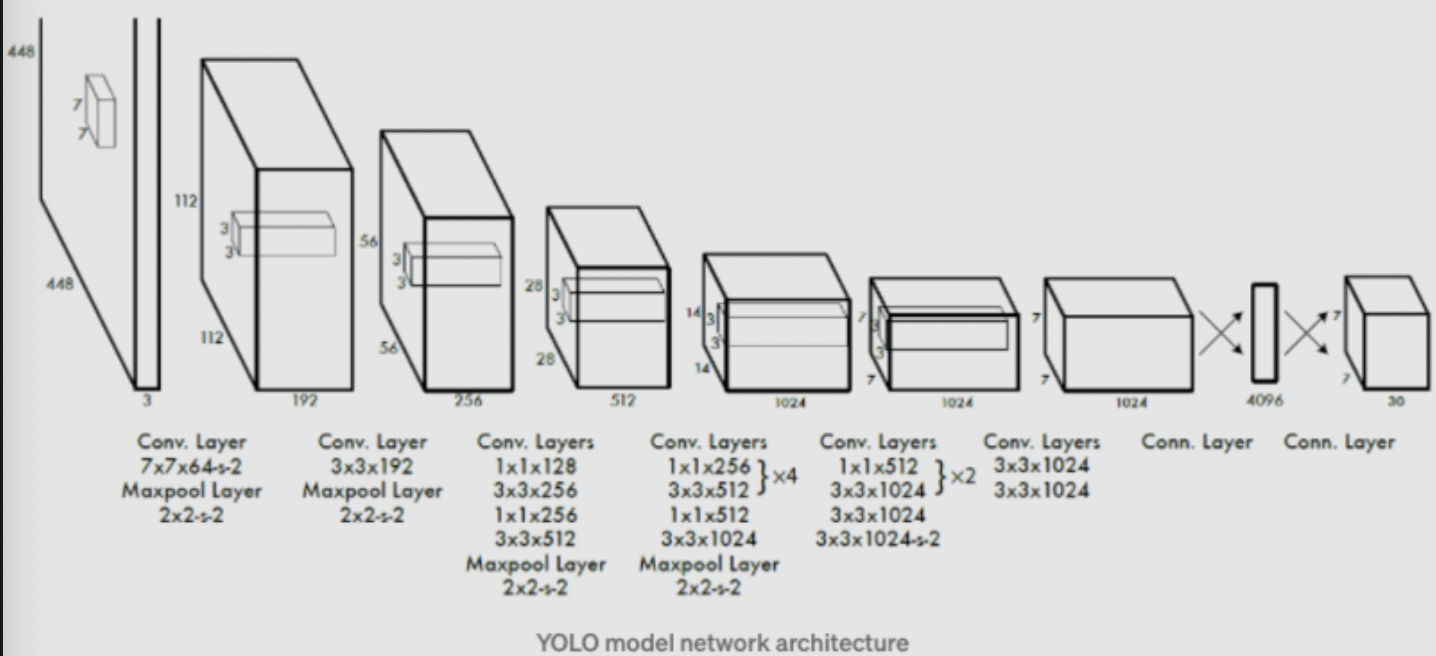
Network Design:YOLO的网络借鉴了GoogleNet,通过 $1*1$ 和 $3*3$ 的卷积层替代了Inception结构。标准的YOLO网络有24层卷积层,后接两层全连接层,而Fast Yolo则只有9层卷积层。YOLO的输出tensor大小为 $7*7*30$ 。与prediction的size相匹配。
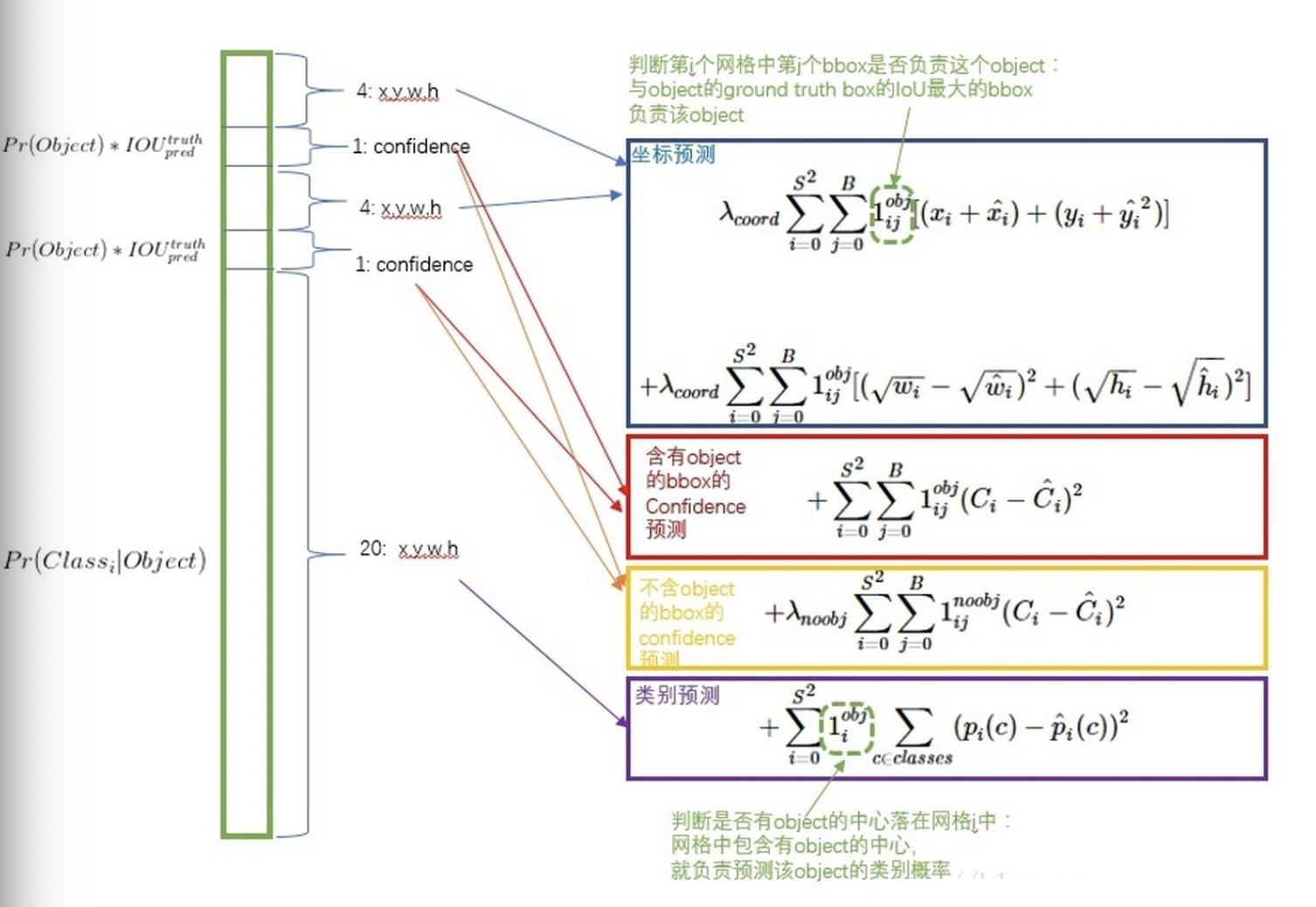
Training: 先在ImageNet 1000-class分类任务上的进行网络的Pretrain,使用上述网络中的前20层卷积层, 后接一个average-pooling层和一个全连接层。将Pretrain得到的前20层全连接层作为Detection网络的前置网络,并加入后续的4层卷积层以及两个全连接层,最后层预测得到class probility以及bounding box coordinates。其中w,h,x,y需要归一化到0-1,以保证w,h小于图片尺寸,且位置在特定的grid cell边界范围内。Loss设计Loss采用sum-squared error loss,但是对不同类的loss采用了不同的权重设计:- coordinates error需要有更高的权重
- no-object的栅格数目比重很大,其所占的loss很大,需要降低no-object的loss权重,降低对网络的贡献率
- 大物体小物体的误差容忍率应该是不一致的,小物体偏移对IOU影响更大,作者采用原本height和width的平方根代替原始值
- 训练过程中,可能存在多个box预测同一个物体,则只取IOU最大的predictor作最终的预测,最终的loss设计如下:
YOLO V2
作者的改进方案如下:
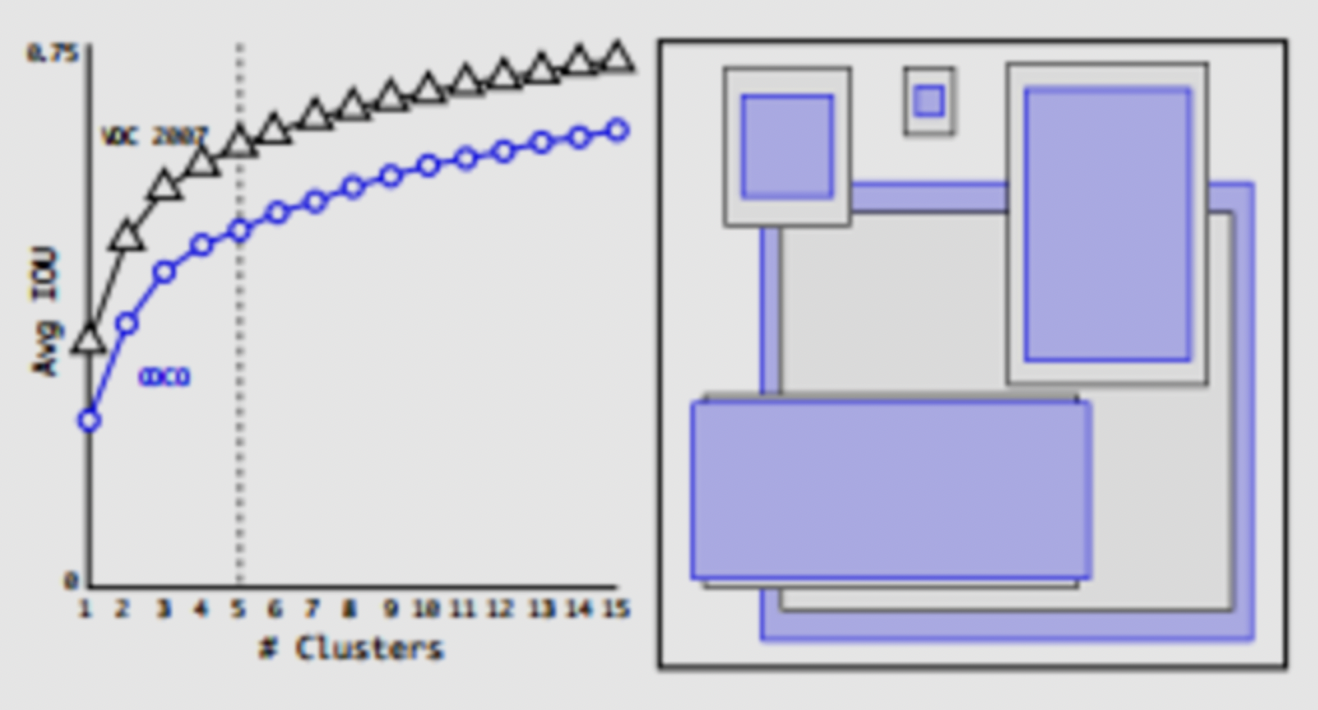
BN层:在对所有卷积层加入BN层后,提升了2%的mAPHigh Resolution Classifier: YOLOv1训练分类网络时采用的input size为224X224,但是detection网络采用的输入为448X448,意味着detection网络训练的过程中需要重新学习更大的输入尺寸。YOLOv2先将分类网络在448X448的输入下进行finetune,然后进行detection网络的finetune,提升了4%的mAPConvolutional With Anchor Boxes: 采用anchor box(k-means聚类得到)的方式进行bounding box的预测。首先移除了YOLOv1的全连接层以卷积层替代,移除最后的pooling层,增大输出的size,输入的图片size由448X448->416X416,目的是为了保持输出为13X13的奇数,以保留图片正中间的grid cell位置(作者认为这对图片中间的大物体预测有帮助)。另外box的class的预测仍然沿用之前的YOLOV1的策略,位置预测直接预测中心点和大小,其中中心点预测采用sigmoid函数限制预测bbox在对应的anchor内。该方案的收益是提高了7%的recall,但是accuracy下降:69.5mAP@81%recall->69.2mAP@88%recall。Dimension Clusters: 采用K-means进行box的聚类,相同情况下,能够比hand picked得到的box有更高的Avg IOU。
\[x = (t_x * w_a) - x_a\] \[y = (t_y * h_a) - y_a\]Direct location prediction: 默认的bounding box的center point的预测方案:该方案的问题是偏移的最大值与anchor box的大小有关,没有其他约束,导致center点的位置有可能到图像中的任意位置,导致模型训练不稳定。所以作者沿用了原先YOLO的预测位置的方式。另外作者通过Dimension Clusters和Direct location prediction的方式,提高了anchor-version 5% mAP,示意图如下:
Fine-Grained Features: 通过pass-through(stacking adjacent features into diffrent channels)的方式将前置的feature层(26X26)与原先的feature map进行concat,融合多尺度性能,能够提高1% mAP。Multi-Scale Training: 为了让YOLOv2对input_size有更强的鲁棒性,模型训练过程中每10个batches会选择一个新的image size输入:{320,352,…,608}。Faster: 设计了Darknet-19:5.58 billion operation,72.9% top1 accuracy, 91.2% top5 accuracy on ImageNet.
YOLO V3
YOLOv3的改进更多地借鉴了诸如SSD,Faster-rcnn,FPN的优点,主要改进如下:
- Predictions Across Scales:参照FPN的设计,对原本13X13的输出feature进行上采样,分别得到26X26和52X52尺寸的feature,并与浅层的featue进行concat,最后通过卷积层进行预测。K-means采用的cluster数目为9。
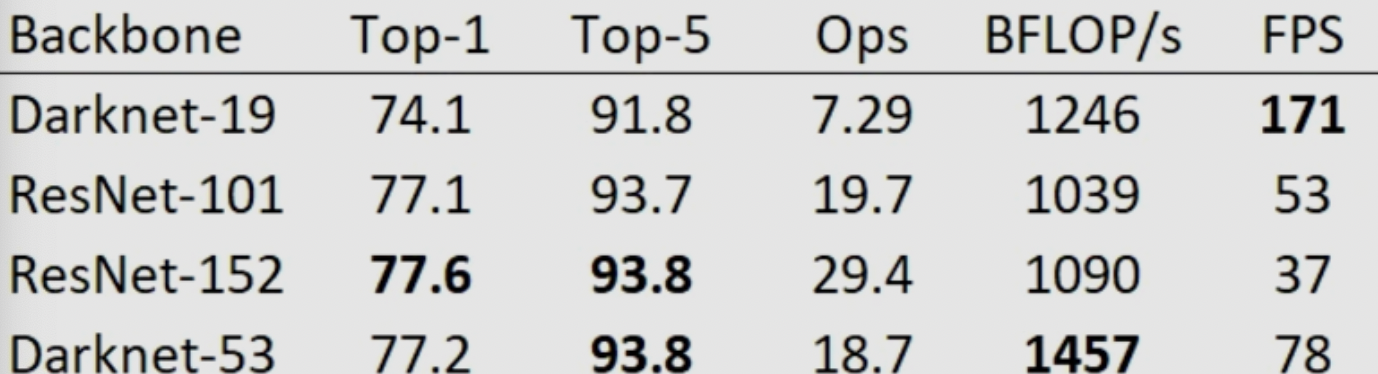
- Feature Extractor:加深了backbone的层数,并且引入Resnet的残差结构,实现了低运算量下较好的性能:
YOLO V4 && YOLO V5
YOLO V5/V4在YOLO V3基础上整合了SOTA结构,进一步提升了基于YOLO框架的One-Stage算法的性能。 参考: 知乎文章 进行简单总结:
Data Augmentation
YOLOV4:
- Random Erase:随机值/训练集平均像素替换图像区域
- Cutout:剪切方块进行mask
- Hide and Seek:以SXS方格进行图片分割,然后随机进行隐藏
- Gide Mask:采用Grid Mask的方式进行图片的Mask操作
- MixUp:图像/标签的混合叠加
- Cutmix:剪切图片并进行粘贴
- Mosaic data augmentation:四张图像按一定比例进行组合
- 自对抗训练(SAT):通过反向传播改变图片信息进行增强(这里反转不改变网络参数)
- Lable Smoothing:通过对class label进行编码,将原始的one-hot-label转换为soft-label。
YOLOV5:
- 缩放
- 色彩空间调整
- Mosaic data augmentation
Backbone
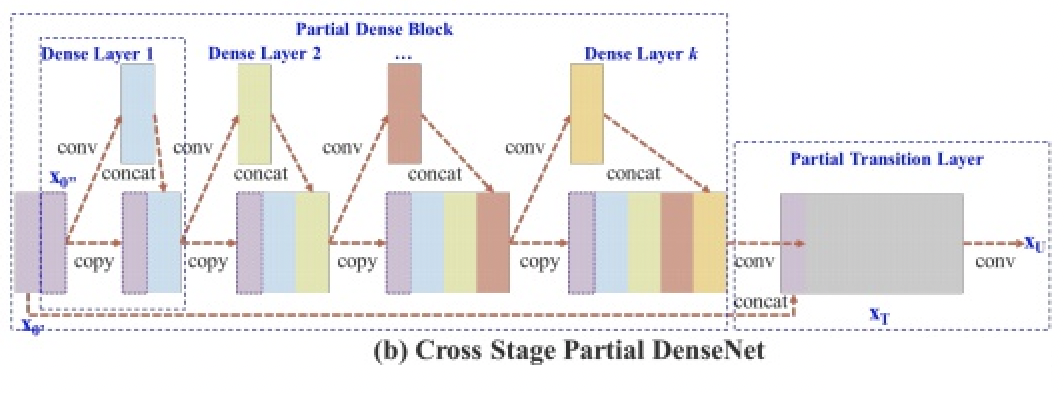
YOLOV4/YOLOV5都采用了CSPDarknet作为BackBone:
其核心在于基于Densnet的思想,通过dense block不断提取深度特征,并且通过复制前置层的操作进行网络特征重用,通过跨阶段特征融合和截断梯度流的方式来增强不同层间学习特征的可变性。
Neck
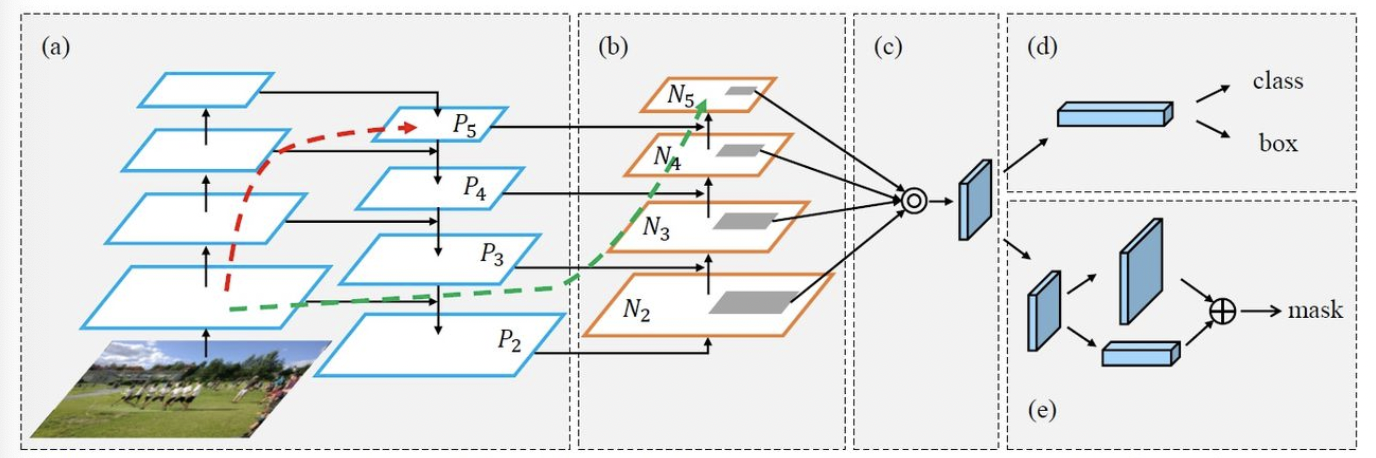
YOLOV4/YOLOV5都采用了PANET作为Neck来聚合特征,其结构如下:
其核心在于添加了自下而上路径的FPN结构,改善来低层feature的传播,同时采用了Adaptive feature pooling的方式实现各个feature map对应区域的特征聚合。
Det-Head
YOLOV4/YOLOV5采用了和YOLOV3一致的Det-Head。
- Loss YOLO系列的Loss包括:objectness loss/class probility loss/bounding bbox regression loss 其中YOLOV5采用cross-entropy/Focal loss计算分类损失,GIoU Loss作为regression loss;YOLOV4采用CIoU loss作为regression loss。
- Comparation 根据当前资料上看,两者性能十分接近。其中,YOLOV4数字上性能更好,且可定制化较高;YOLOv5的训练速度很快,且提供了一系列轻量级网络,方便部署。
Anchor Free算法
其实将Anchor Free算法和Two Stage算法并列不是很合理,因为其本质还是可以归为One Stage算法,只是在Proposal的获取层面摆脱了Anchor的束缚。Anchor Free算法的出发点在于:Anchor Based本身上的一些缺陷:
- 算法精度依赖于Anchor的设计,不同场景不同对象的大小尺寸分布对Anchor设计存在适应性,极端场景下不同Anchor设计存在较大的精度差距
- Anchor实际上存在一定冗余计算,比如:单个bbox往往对应多个anchor,但是能match的target往往只有一个,意味其他都是多余的match的框,一定程度上也会带来训练过程中的正例竞争
- NMS引入,多个anchor的设计必然会带来很多正例的match框,通常的解法是通过nms来解决,但是这种方案一方面nms有时候较为耗时,同时部分场景下,nms可能会滤掉一些正例(拥挤场景)
所以,Anchor Free算法通常网络设计更简单高效,易于部署,但是性能上限不高。本文主要介绍两种业界应用比较多的经典Anchor Free算法:FCOS和CenterNet;关于Anchor Free算法和Anchor Based算法的性能和精度差距,ATSS这篇论文阐述得比较详细,大家有兴趣可以参考下。
FCOS
FCOS发表于2019 ICCV,代码开源于 FCOS_Github,类似于 mmdetection 都集成了相关的算法。
FCOS刚发布的时候精度超越了前作的所有基于Anchor Free的算法(笔者验证了其与设计过的Anchor based算法还是有一定差距,但是差距不大)。其算法优势是避免了Anchor的超参设计,网络速度更快,同时其一些算法设计上也带来了一些思考( Centerness )。
Anchor Free算法的问题是:失去了先验的Anchor设计,如何合理地分配正负例?其实YoloV1算法框架便是没有Anchor设计的,其采用的正例的分配的方案是:如果Target的中心点落在对应的方格内(Yolov1将feature map分为7*7的格子),则认为该正例归属于该方格,应由该方格负责预测。但是该方案的问题在于:一个方格只能预测一个正例,对拥挤场景性能差;同时该方案无法适应多feature map(如 FPN )场景,在小物体上的性能表现差。
FCOS的核心思路是:不同大小的Feature map负责不同大小的物体的预测,训练时通过GT框的长宽进行分配;同时引入 Centerness 来提高匹配框的质量。 FCOS的算法框架如下: 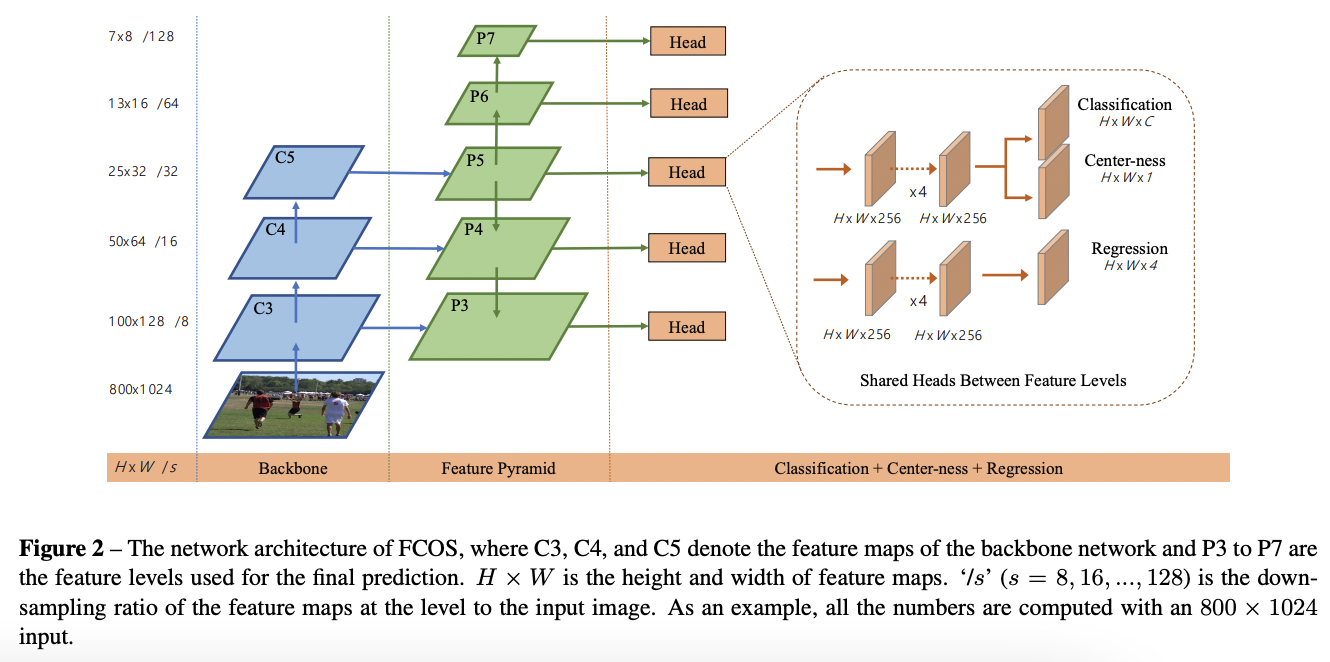
算法细节:
Backbone:采用了RetinaNet的Backbone,特点是采用了FPN设计输出不同大小的5层feature map:P3~P7,各层之间通过stride为2的卷积产生,同时进行上下层的特征融合。Anchor分配策略:目标定义:FCOS的预测策略是中心点(x,y)和偏移向量(l,t,r,b)来进行对象的预测:
- 同层分配策略:按照目标中心点(x,y)位于哪个box则由该box进行预测,对于多个目标取面积最小的。
- 不同层的分配策略:设计不同层负责的目标范围,如P3~P7对应的尺寸范围 $(m_{i-1}, m_{i})$ 为:(0, 64),(64, 128),(128, 256),(256, 512),(512,+∞)。假设目标GT为(x,y)(l,t,r,b),则根据如下公式进行分配:
Head设计:不同feature map采用共享权重的Head,Head的结构为Multi Convs + Classification/Regression/CenternessClafication + Regression: 分类任务采用C个二分类实现,loss采用
focal loss,回归任务主要预测4个偏移向量: l/t/r/b,loss采用的是IoU loss:Centerness: Centerness的出发点在于找到目标对应的最靠近中心点(质量最好)的方格进行预测回归。Centerness的定义如下:
训练过程中可以采用BCE损失:
Loss合并: 最终的Loss包含如下三部分:

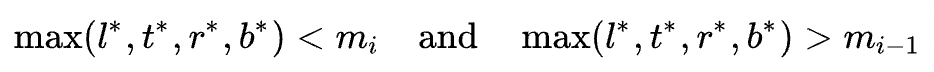
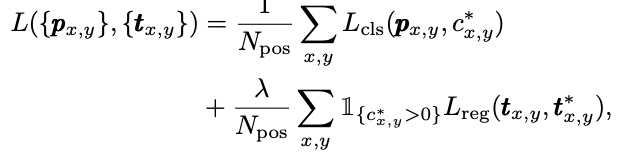
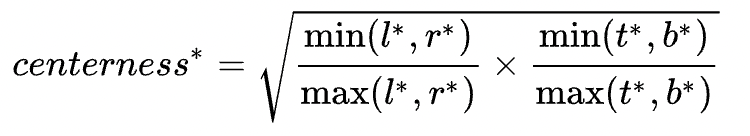
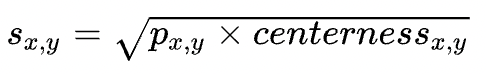
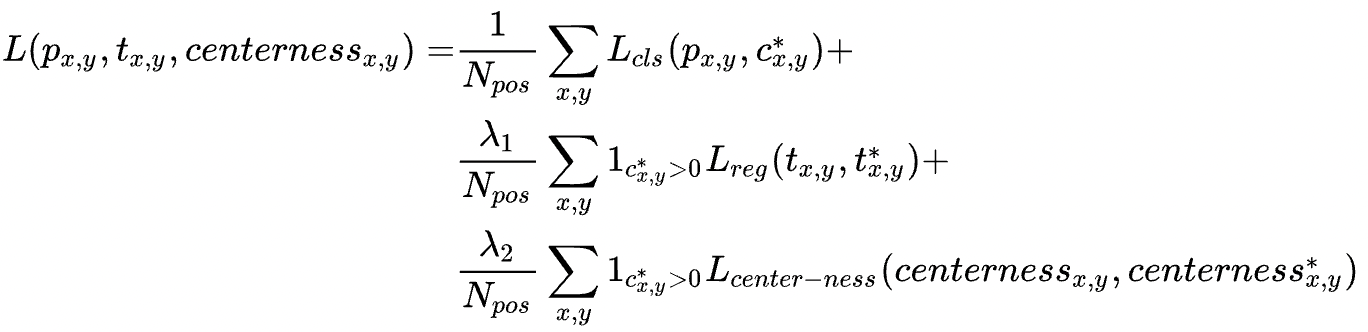
算法总结:
- 优势
- 全卷积的网络结构,整体结构非常简单高效;避免来Anchor参数设计,精度也比较可观
- Anchor多层的分配策略解决了Target冲突的问题
- Centerness的引入类似IoU branch,其带来的思考是:引入box预测质量的评估是有效的。
- 缺陷/可提升点
- 本质还是基于Anchor的目标检测方案(可以认为是单Anchor的变种),算法层面没有根本上的创新, ATSS其实更近一步思考了该类问题
- 在同尺度的密集场景存在正样本预测上的冲突(FCOS没有解决同层上的正样本的冲突问题)
- Loss层面:Centerness可以通过IoU替换(效果更好?);另外IoU loss也可以通过GIoU Loss进行替换:Generalize Focal Loss
CenterNet
CenterNet其实有两篇:CenterNet: Keypoint Triplets for Object Detection 和 Objects as Points
其中第一篇的思路来源于Keypoint的预测,类似的前作有CornerNet。其核心思路是通过两个branch进行物体中心点和左上+右下脚点的预测从而得到最终的检测框。
本文主要介绍第二篇即:Objects as Points,原因主要是该方法结构非常简单高效,拓展性很强,在其基础可拓展:2D检测/3D检测/人体姿态估计/Tracking算法(Tracking Objects as Points),且本文一定程度上去掉NMS操作(采用来max_pool的方式),有很多启发性的亮点。
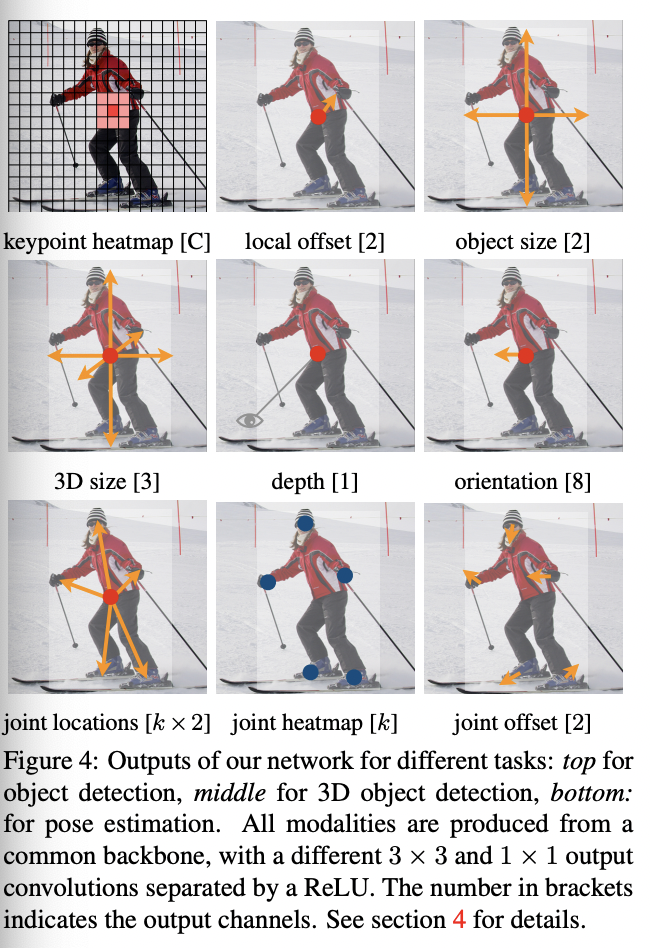
这里简述下其在2D Detection这个任务上的算法设计(其他Task其实很类似): CenterNet的核心思路是通过基于预测Key-Points的方式来得到检测框。与类似CornerNet的方式不同,Cornet的方案是通过预测中心点/框边缘点,然后再通过 grouping 的方式来进行点的关联,这样一方面带来额外的计算量,同时也带来了误差;CenterNet的方法比较简单粗暴:直接基于预测的到的中心点进行中心点偏差和检测框的宽高的预测,预测效果如下: 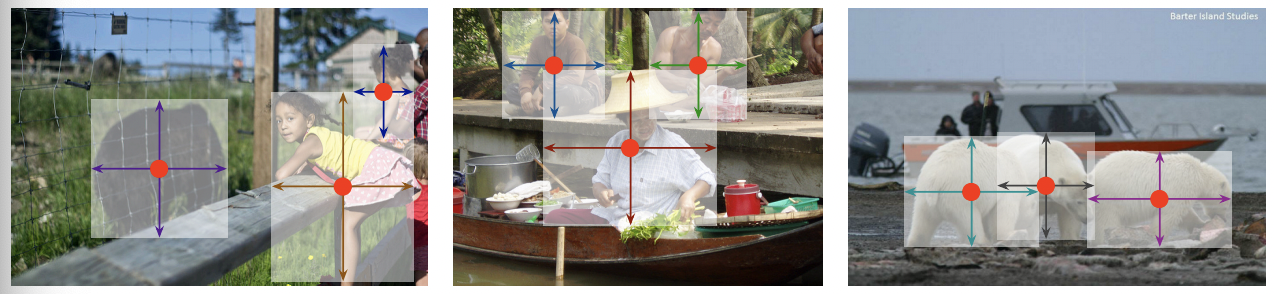
CenterNet算法细节:
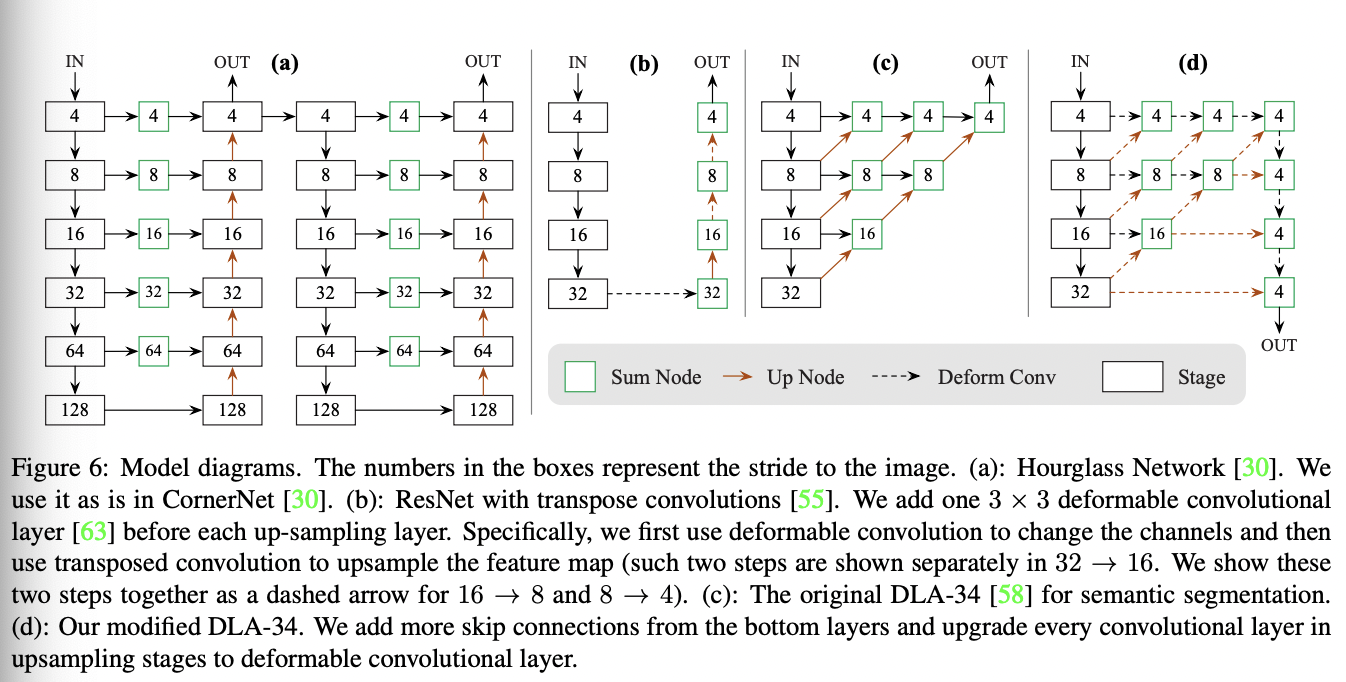
BackBone: CenterNet预测得到物体中心点是基于Heatmap得到的,所以其网络结构与Keypoints/分割网络比较接近,为encoder-decoder类型的网络;论文采用了三种BackBone:Resnet-18 with up-convolutional layers/DLA-34/Hourglass-104,精度依次变高,速度依次变慢,另外其采用较大的feature map(下采样因子为4),原因是其基于单feature map进行预测,feature map过小,无法预测小物体:正负例分配: CenterNet没有Anchor的概念,只有heatmap的heat点来预测正例。所以训练过程中需要将检测框的GT值进行转化,同样生成heatmap的GT图,可采用的高斯滤波的方式:Loss设计: CenterNet的预测值包括三个部分:中心点/中心点偏置/检测框长宽;预测中心点的偏置的原因是heatmap是下采样得到的,中心点存在误差。值得注意的是在计算中心点损失的过程中,会遇到正负例样本不平衡的问题,SSD等Anchor Based的方案通过正负例的loss比例或者Focal loss的方式来缓解正负例样本不均衡的问题。CenterNet也采用了类似的方案:对中心点偏置和长宽的loss都采用了L1 Loss:
最后合并后的loss为:
后处理: 后处理指的是预测阶段,CenterNet没有采用NMS的方案,而是通过一个3X3的max pooling得到100个heat点(排序得到),最后再通过类别score(Heat点概率)阈值得到最后的中心点,并结合中心点的偏置和长宽得到最终检测框:
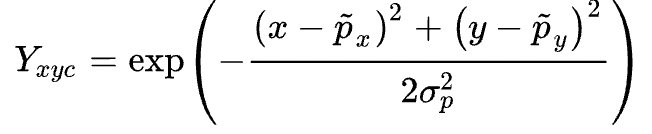
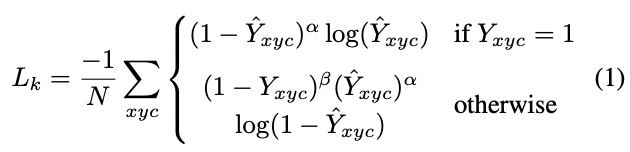
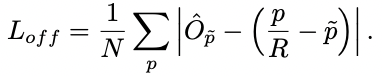
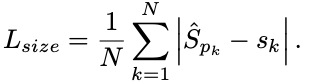
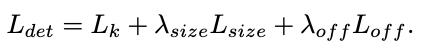
算法总结:
- 优势
- 结构非常简单直白,但是能work;且这种简单的结构具备很强的适配性,可应用于各项任务
- 几乎是全卷积/池化的操作,网络结构很高效,适合部署
- 缺陷
- 仍然受限于One Stage网络的缺陷:无法解决重叠的问题;另外由于其没有多层feature map,该现象会更明显。值得注意的是:在生成GT Heatmap的过程中,对于重叠的高斯分布点,算法采用了直接替代的方式(取重叠范围内更大的高斯点),导致其算法上限不高