前言
简述分布式通信相关知识栈(work with ChatGPT)。
总线/通信协议
PCIe
| PCIe 1.0 | PCIe 2.0 | PCIe 3.0 | PCIe 4.0 | PCIe 5.0 | PCIe 6.0 | |
|---|---|---|---|---|---|---|
| Year | 2003 | 2007 | 2010 | 2017 | 2019 | 2021 |
| Transfer per lane(Gbps) | 2.5 | 5.0 | 8.0 | 16.0 | 32.0 | 64.0 |
| x16 bandwidth(GB/s) | 4.0 | 8.0 | 15.8 | 31.5 | 63.0 | 121 |
带宽计算:
\[\text{x16 bandwidth(GB/s)} ≈\text{Transfer\ per\ lane(Gbps)} \times 16 / 8\]NVLink
NVLink,是英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个NVIDIA图形处理器之间的相互连接。当前配备并使用NVLink的产品业已发布,多为针对高性能运算应用领域,最早于2016年基于Pascal架构的GP100芯片以及基于该芯片的Tesla P100运算卡,配备有NVlink。
| NV Link 1.0 | NV Link 2.0 | NV Link 3.0 | NV Link 4.0 | |
|---|---|---|---|---|
| Year | 2014 | 2017 | 2020 | 2022 |
| Transfer per link(GB/s) | 20+20 | 25+25 | 25+25 | 25+25 |
| Link number | 4 | 6 | 12 | 18 |
| Lane number per link | 8 | 8 | 4 | 2 |
| Data rate per lan(Gbps) | 20 | 25 | 50 | 100(PAM4) |
| Total bidirectional bandwidth(GB/s) | 160 | 300 | 600 | 900 |
H100芯片采用NVLink 4.0,其中两个H00芯片通过18条NVLink互联,每条link中含2条lane,每条lane支持100Gb/s PAM4的速率,因此双向总带宽为900GB/s。
NVSwitch采用3.0,每个NVSwitch支持64个port,每个port速率为50GB/s。
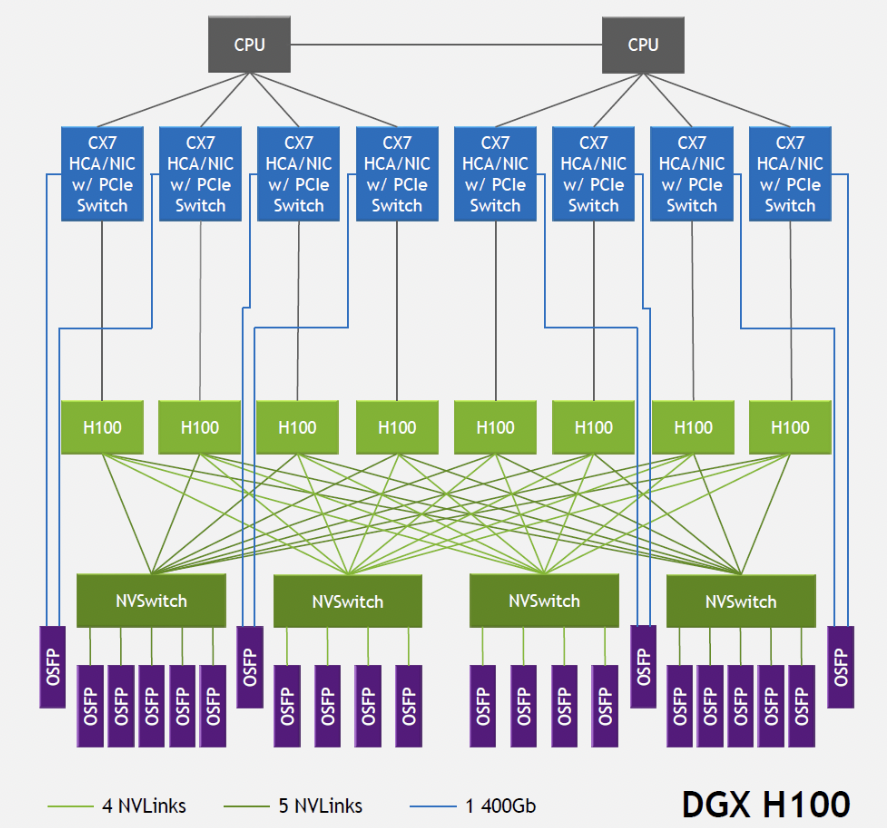
DGXH100由8颗H100芯片和4颗NVSwitch芯片构成(NVLink数目为:5+4+4+5)。连接结构如下图,图中每个NVSwitch的另一侧与5个800G OSFP光模块相连。以左侧第一个Switch为例,其与GPU相连侧的单向总带宽为4Tbps(20NVLink\200Gbps),与光模块相连侧的总带宽也为4Tbps(5\800Gbps),形成 非阻塞(non-blocking)网络 。注意,光模块中的带宽指的是单向带宽,AI芯片中一般指双向带宽。
HCCS
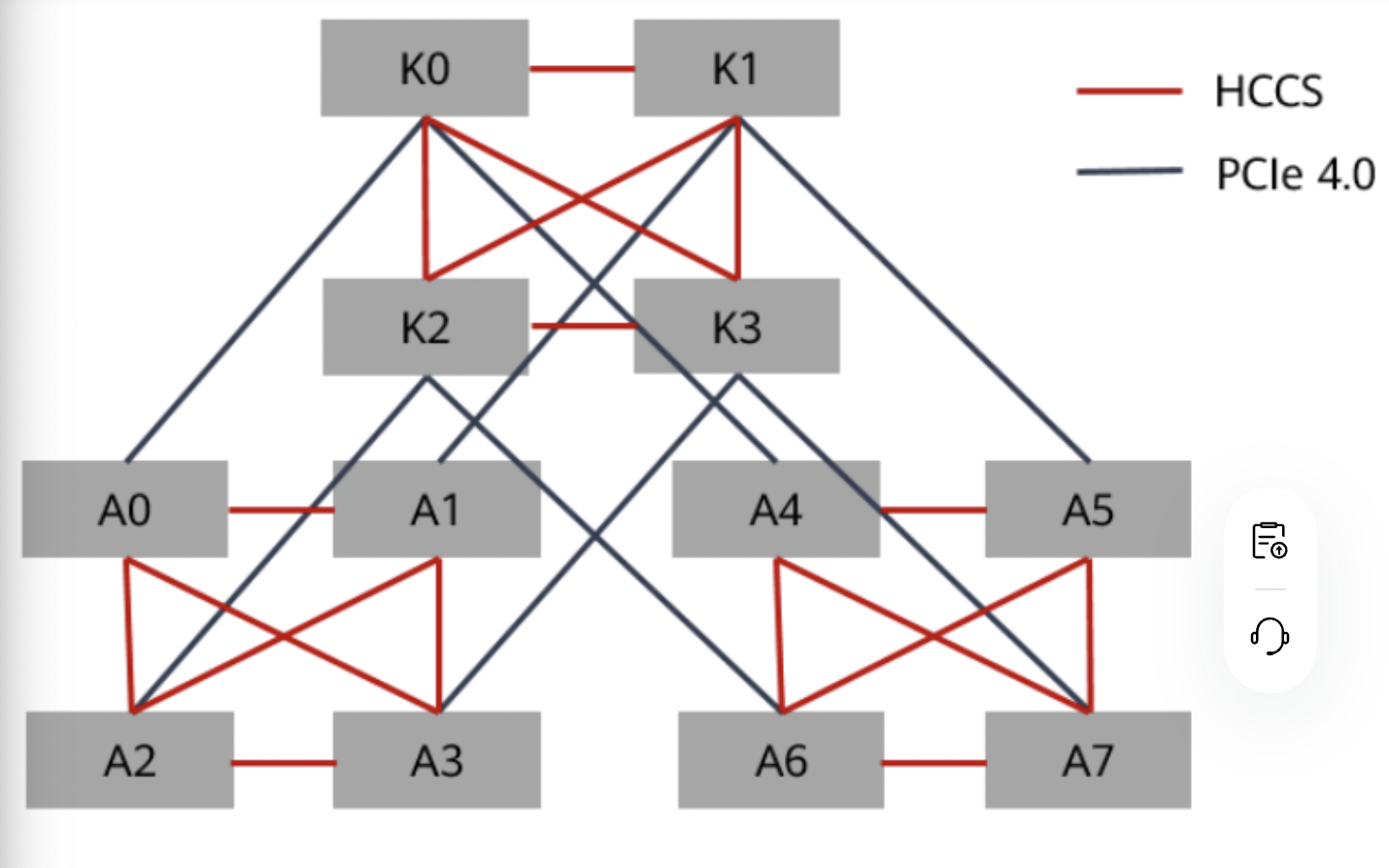
昇腾 910 AI处理器是华为研发的一款高性能AI处理器。其内部的处理器之间采用HCCS(例如:A0~A3为一个HCCS)方式连接。HCCS(Huawei Collective Communication Server)是HCCL(Huawei Collective Communication Library)的硬件形态,HCCL提供了深度学习训练场景中服务器间高性能集合通信的功能。
对于训练系列产品,每台设备具备两个HCCS环共8颗处理器(A0~A7)。每个HCCS存在4颗处理器,同一HCCS内处理器可做数据交换,不同HCCS内处理器不能通信。即同一Pod分配的昇腾 910 AI处理器(若小于或等于4)必须在同一个HCCS环内,否则任务运行失败。昇腾910 AI处理器的互联拓扑如下图,其中K0~K3为鲲鹏处理器。
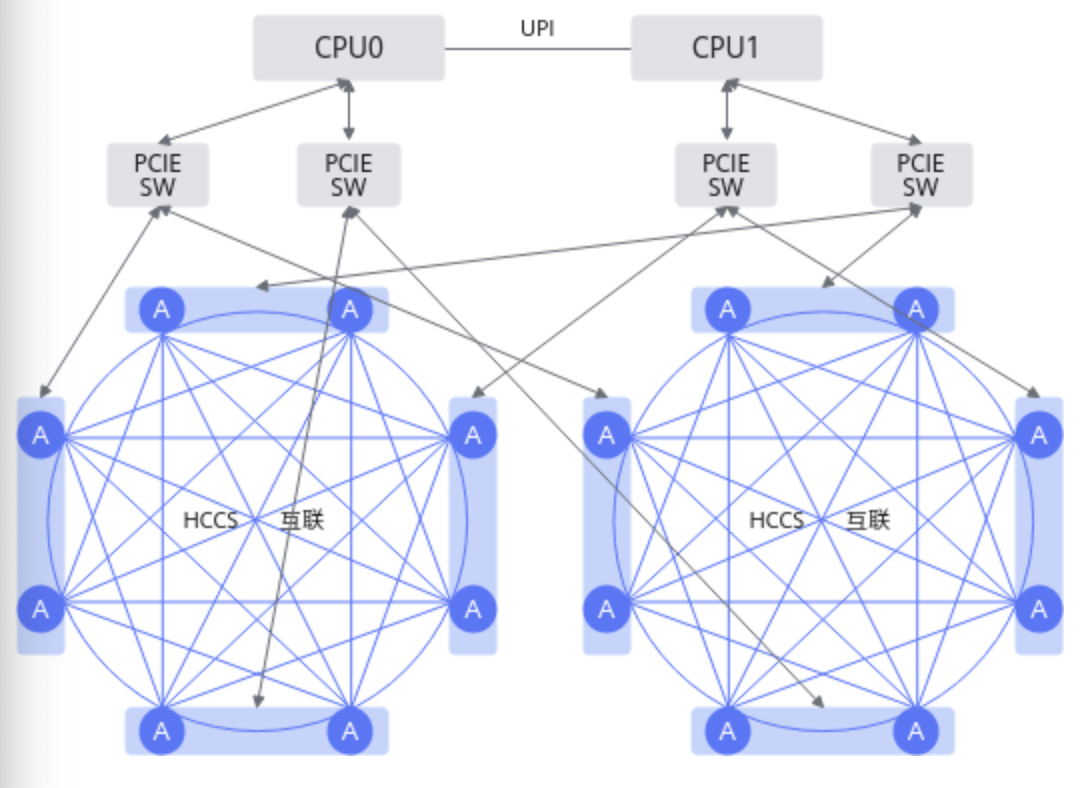
对Atlas 200T A2 Box16异构子框来说,其内部AI处理器之间采用HCCS互联的方式相连接。每台Atlas 200T A2 Box16 异构子框的AI处理器具备两个HCCS互联共16个AI处理器,每个HCCS互联存在8个AI处理器,同一HCCS互联之间可以做数据交换,不同HCCS互联之间的不能通信。即任务分配的Atlas 200T A2 Box16 异构子框的AI处理器(若小于或等于8)必须在同一个HCCS互联内,否则任务运行失败。Atlas 200T A2 Box16 异构子框的互联拓扑图如下图:
通信算法
常见的通信元语如下:
- Point-to-Point Communication:包括Send/Recv,主要完成两个通信节点的通信。
- Broadcast:将一个设备的数据广播到所有其他设备。
- AllReduce:将数据从所有设备汇总后广播到每个设备。
- AllGather:从所有设备收集数据,并将其分发到所有设备。
- ReduceScatter:归约并将结果分散到多个设备。
- All-to-All:每个节点(或进程)都向所有其他节点发送数据,同时接收来自所有其他节点的数据。最终,每个节点都会持有从所有其他节点收集的数据,也可以认为是分布式的
Transpose。
具体的通信元语可以有不同的通信算法实现,如:
- Ring:将节点组成一个环形拓扑,每个节点只与相邻的两个节点通信。每个通信步骤中,数据在环中以固定方向传递,并逐步完成规约或分发操作。每个节点的通信量为 $2 \cdot \text{DataSize} / \text{NumNodes}$,通信步数为$P-1$($P$ 为节点数)。
- Mesh:将节点按二维或多维网格排列,每个节点仅与上下左右的邻居通信。通信以行和列两个方向分步完成。$O(\sqrt{P}) $通信步数,适合大规模节点。
- HD(Hierarchical Decomposition):分层优化,将通信分为 节点内通信 和 节点间通信 两个层次。节点内通信利用共享内存或高速链路(如
NVLink),节点间通信通过网络(如InfiniBand)。能够高效利用带宽:节点内通信速度远高于节点间通信。适用多机多卡场景:深度学习分布式训练、大规模 HPC。 - Tree:将节点组织为一个树形拓扑,根节点负责汇聚和分发数据。树的形状可以是二叉树、多叉树等,适配具体通信需求。通信步数为 $O(\log P)$,适合低延迟需求的场景。
| 特性 | Ring | Mesh | HD | Tree |
|---|---|---|---|---|
| 拓扑结构 | 环形 | 多维网格 | 分层分解 | 树形 |
| 通信复杂度 | $O(P)$ | $O(\sqrt{P})$ | 与层次结构相关 | $O(\log P)$ |
| 适用场景 | 小规模通信 | 大规模分布式训练 | 多机多卡、大规模并行 | 小数据量、低延迟 |
| 实现复杂度 | 简单 | 较复杂 | 较高 | 中等 |
| 优点 | 易实现,通信均衡 | 可扩展,负载平衡 | 高效利用硬件资源 | 通信步数少,低延迟 |
| 缺点 | 随节点数增加延迟增加 | 实现复杂,通信步数较多 | 依赖硬件拓扑 | 数据分配需要精确设计 |