前言
本文主要讨论O1/O3/R1/Kimi 1.5模型对AI INFRA,主要是推理框架/基础设施层面的上的思考和挑战。
从行为表现上看,这些模型的共同点:都具备较长的思维链路,推理成本增高的同时引起效果的明显提升(尤其是Code/Math等方面)。目前DeepSeek R1/Kimi1.5都开源了模型以及较为详细的技术报告,其中DeepSeek R1着重介绍了模型的训练过程以及过程中的不同技术路线尝试,Kimi 1.5则披露了更多工程方案上的细节。OpenAI方面没有透露官方的技术方案,只能从模型表现以及团队之前的技术路线上做一些浅显的猜测。
Long CoT技术路线
Long CoT(Long Chain-of-Thought)技术路线是一种基于思维链(Chain-of-Thought, CoT)的推理增强技术,旨在通过生成更长的推理链来提升大型语言模型(LLM)在复杂推理任务中的性能。与传统的短推理链(Short CoT)相比,Long CoT能够处理更复杂的任务,因为它允许模型在生成最终答案之前进行更深入的思考。
如下为DeepSeek R1和Kimi1.5对同样的问题的回答结果,DeepSeek R1(左)/Kimi 1.5(右):
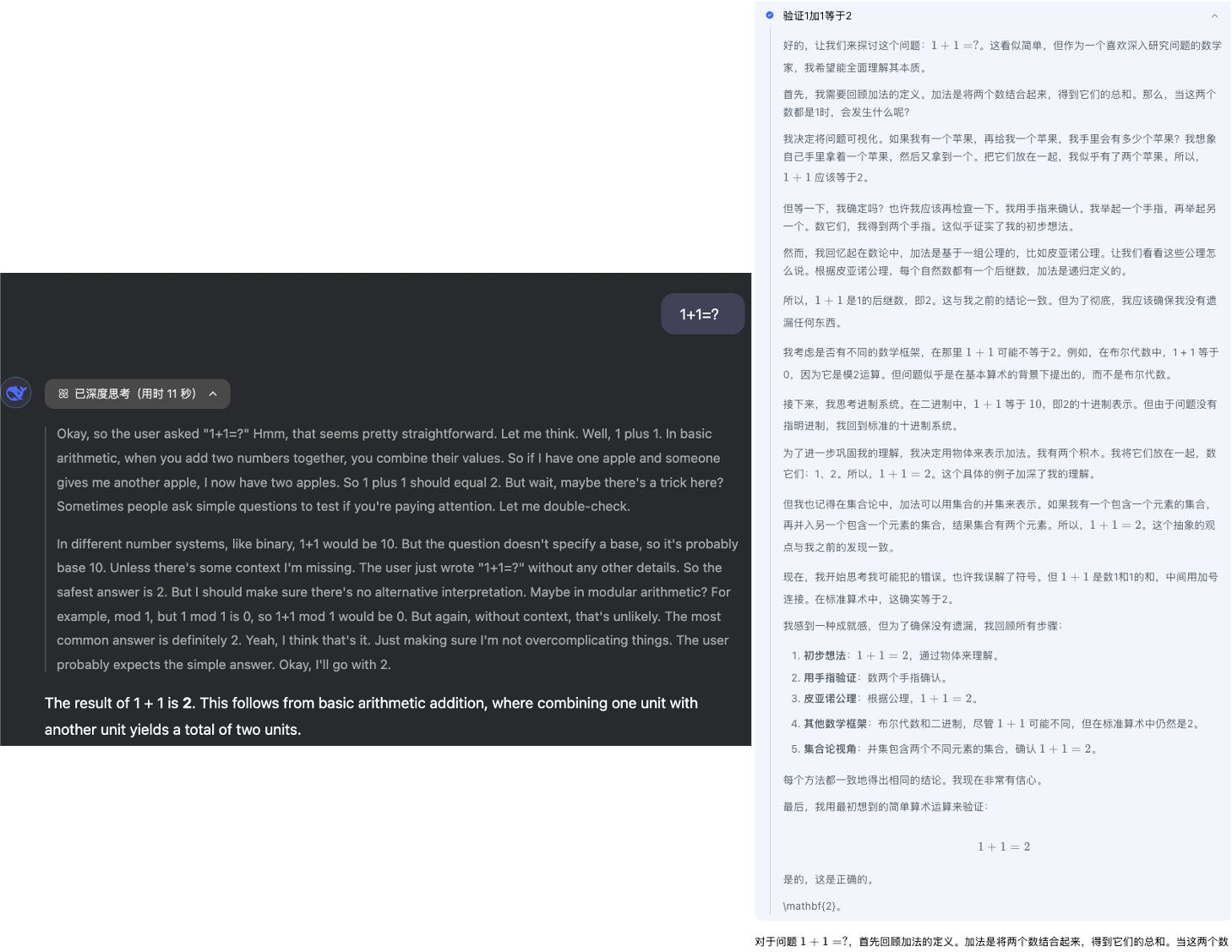
可以看到,即使是简单的1+1=?的问题,对于Long CoT模型都存在很长的中间思考过程,且从这个输出结果上来看,kimi1.5的思维链路要长的多(笔者试了一些其他数学问题,皆有类似的结论)。
O1技术路线(猜测)
从O1前身GPT4的训练过程上看:GPT4:Pre-Training+Post-Training(SFT+RLHF)->Inferecence(Token by Token),O1在此基础上增强了Long CoT的能力,可以简单表示为:O1: Pre-Training+CoT Training(CoT SFT + RLHF)+Post-Training(SFT+RLHF)->Inference(CoT+Summary),其中最核心的技术细节在CoT Training环节,该环节比较明确点是:
CoT PreTraining+SFT:
无论是Pretraining还是SFT都需要增加CoT数据进行CoT能力的补充,为后续RL训练奠定基础(R1-Zero虽然也证明了直接RL训练也会有CoT变长的现象,但是训练细节不多,个人感受容易训飞)。CoT数据可以是人工标注(成本高,如果基于PRM训练成本更高)、其他CoT模型蒸馏、人工合成(Prompt Engineering基于LLM模型来生成)。
CoT+Summary Inference:
对于CoT模型来说,
hidden CoT没有直接暴露给用户(R1/K1.5可见),所以最终的输出是包含Summary环节,即推理过程为:<Think/Reflection...><summary>,不同环节是否由不同的模型生成,当前也有争论(笔者个人倾向于单一模型)。
存在争论的点:
CoT的生成过程:
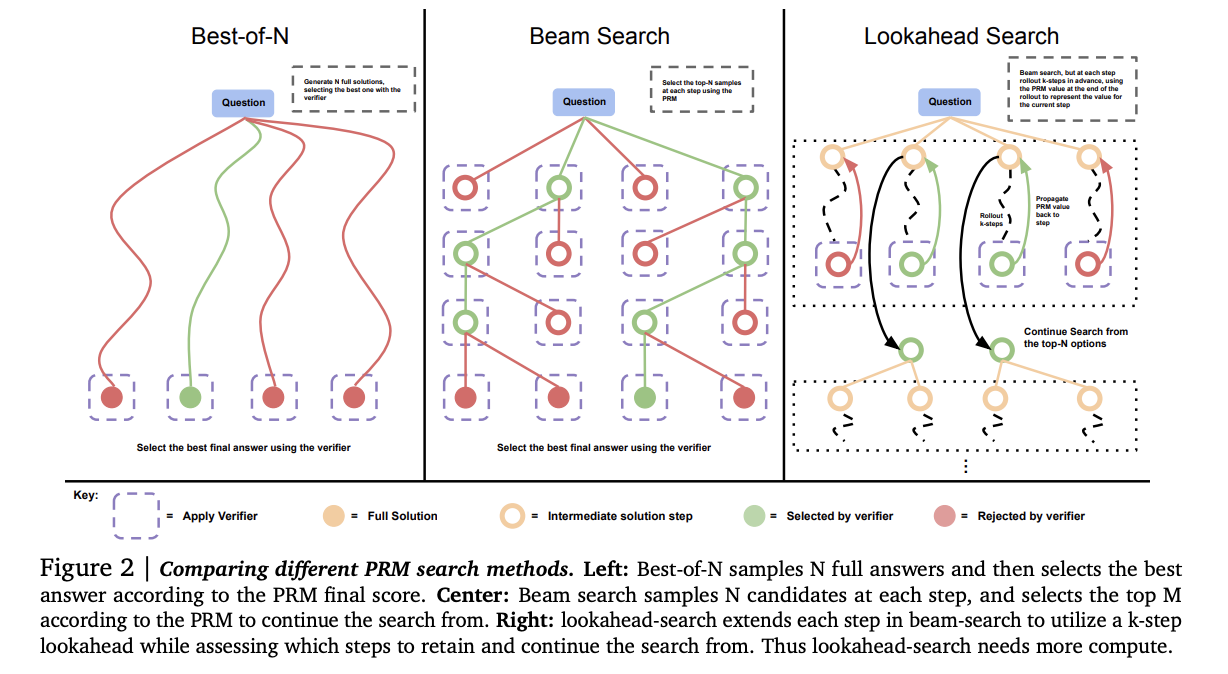
Inference-time Scaling Law && RL:
基于LLM也可以构建CoT的逻辑,思路便是:Prompt Engineering(加入Think过程)+Sampling逻辑(增大search维度)+verify(人工/verify model)。Inference-time Scaling Law中探讨了通过增加Inference时间/维度的方式来增强模型能力的方式,其基本结论是:对于简单或者中等难度的逻辑推理问题,通过inference-time 增加算力,比如树搜索等方式,比去增强模型的“预训练”阶段的逻辑推理能力来得效果要明显;而对于高难度的逻辑推理问题,则只靠inference-time很难提升,有时还是负面作用,不如去增强模型“预训练”阶段的逻辑能力。当然其是没有引入CoT过程的,即基于Next Token的Search方案:

基于CoT的SFT过程可以通过构建指令格式来实现,如Planning(规划)、Evaluation(评估)、Reflection(反思)、Exploration(探索),构建对应的warm-up数据集,便可以有效引导模型内化这些CoT的推理策略。
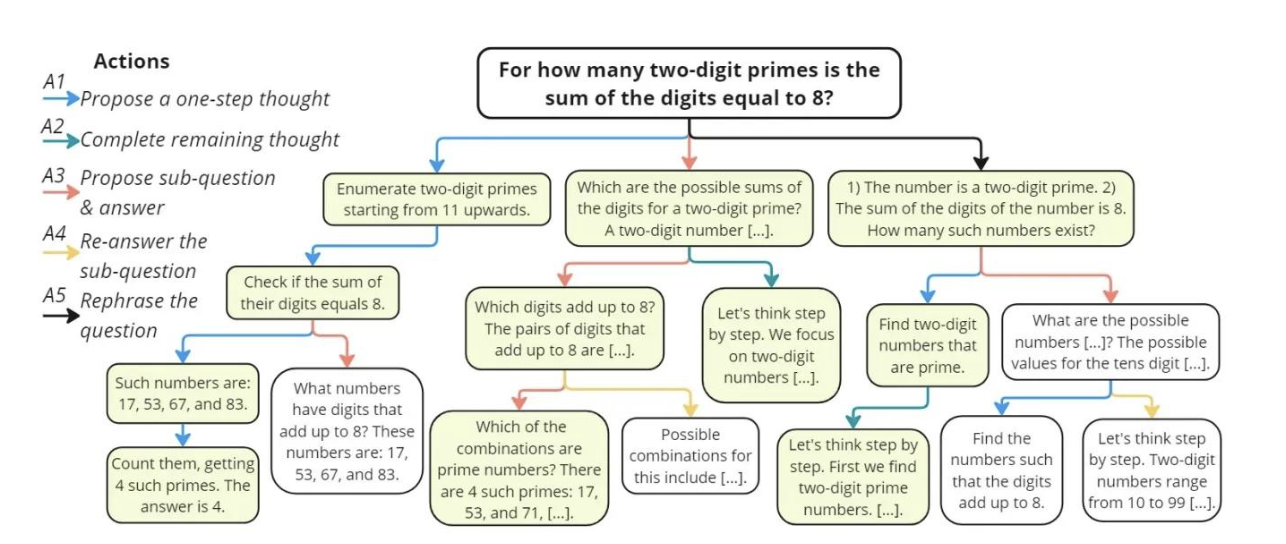
MCTS:
蒙特卡罗树搜索 (MCTS) 能够基于不同搜索策略(或称为思考因子)得到复杂的推理样本,理论上能够实现更高的模型性能上限。
但是,基于MCTS的推理链路会变得非常长,导致推理成本也会很高,且随着数据量的扩充,训练难度也会变大。且本身树Search中,会依赖每个节点的verify,即需要对每个步骤进行评判,一方面标准成本会更高,另一方面,其实很难对中间步骤进行量化评估。
CoT RLHF的训练策略:
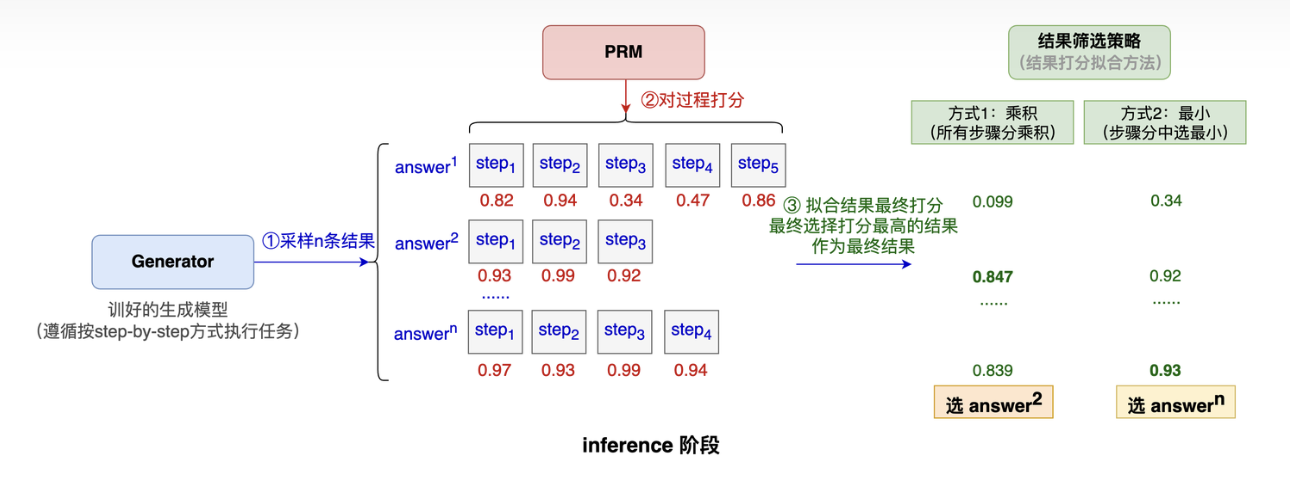
ORMorPRM:ORM(
Optimal Reward Model)和PRM(Preference Reward Model)是RLHF过程中两种构建Reward不同方式。其中,ORM只对最终生成的结果进行打分,而PRM则是为每个中间步骤提供奖励,具体可见下图,两者对比上看:ORM对训练数据要求低,尤其是一些有确定答案的数据(如math/code等),而PRM的数据标注成本很高,不仅数据量增多,且很多中间步骤的评判通常很难量化,但是PRM由于有更多的训练反馈,对提高模型上限、提高泛化性上更有优势。值得一提的是:MATH-SHEPHERD提出了一个自动化的数据标注方法:核心思路是将一个推理步骤的质量定义为“其推导出正确答案的潜力”,并通过“补全”和“估计”两个步骤来实现自动标注:
补全:对于一个给定的推理步骤 $s_i$,我们使用一个“补全器”(completer)从这个步骤开始,完成 N 个后续的推理过程。通过这些完成的推理过程,我们可以评估步骤$s_i$的潜力。
估计:基于补全步骤得到的N个完成推理过程的答案,我们来估计步骤$s_i$的质量$y_{s_i}$ :
硬估计:只要存在一个完成推理过程的答案${a_i}$等于正确答案${a^*}$,我们就认为步骤$s_i$是好的,并将其标签设置为 1。否则,标签设置为 0。
软估计:将步骤$s_i$的质量定义为,完成推理过程的答案等于正确答案${a^*}$的频率。
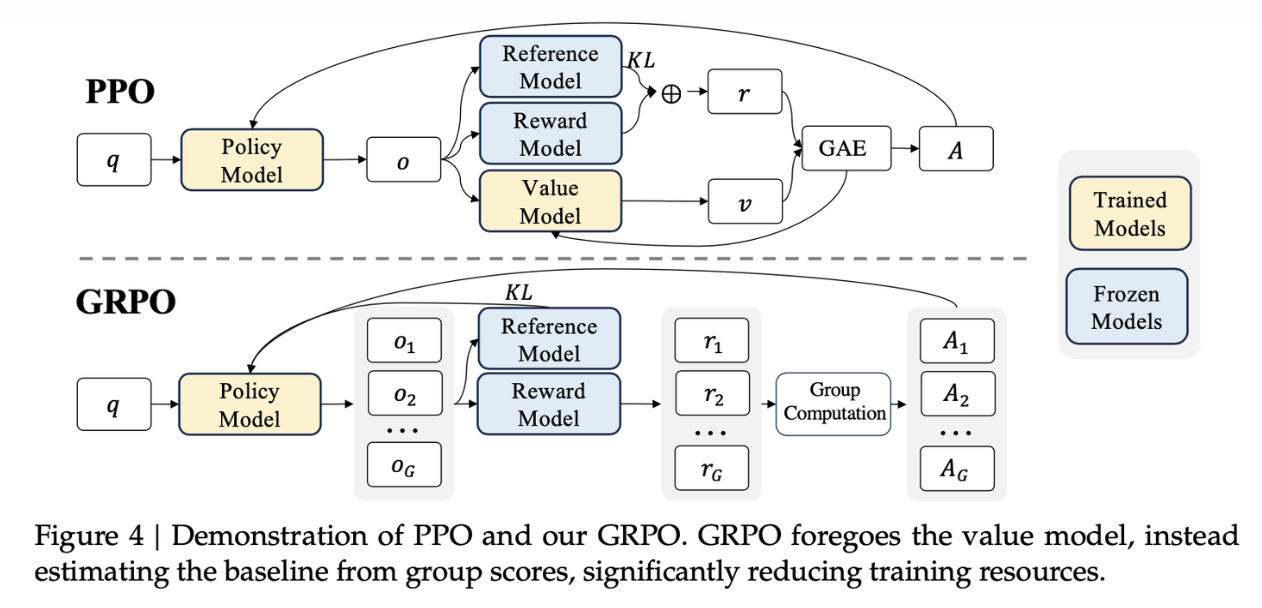
PPOorGRPO:PPO(
Proximal Policy Optimization)和GRPO(Generalized Reinforcement Learning with Policy Optimization)都为RLHF过程中的优化策略算法,PPO算法最早由2017年提出的强化学习算法,GRPO在PPO的基础上,采用群体相对优势计算和自适应 KL 约束实现更高效的优化,进一步降低了计算复杂度和资源需求,两者对比如下图。PPO算法的详细介绍可参照Blog,其核心在于重要性采样和Clip机制:
\[J_\text{PPO}(\theta) = \mathbb{E}_{q\text{~}P(Q),o\text{~}\pi_{\theta_{old}}(Q|q)} \left[ \min \left( \frac{\pi_\theta(o|q,o_{<t})}{\pi_{\theta_{old}}(o|q,o_{<t})} A_t, \text{clip}(\frac{\pi_\theta(o|q,o_{<t})}{\pi_{\theta_{old}}(o|q,o_{<t})}, 1-\epsilon, 1+\epsilon) A_t \right) \right]\]其中,优势函数$A_t$依赖于
\[J_\text{GRPO}(\theta) = \mathbb{E}[q\text{~}P(Q),\{o_i\}^G_{i=1}\text{~}\pi_{\theta_{old}}(O|q)]\\\frac{1}{G}\sum\limits^G_{i=1}\frac{1}{|o_i|}\sum\limits^{|o_i|}_{t=1} \left[ \min \left( \frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})} A_{i,t}, \text{clip}(\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}, 1-\epsilon, 1+\epsilon) A_{i,t} \right) -\beta\mathbb{D}_{KL}(\pi_\theta||\pi_{ref})\right]\]Value Model和Reward Model估计得到,GRPO优化掉了Value Model,因为Value Model的目的是为了模型当下输出的答案一个更加准确的定位,既要考核这个模型绝对意义上有多好,也要考虑相对其他回答有多好。GRPO的思路是:对每个问题,生成一批答案和reward:$r_1,…,r_G$,计算Advantage则利用这些reward之间的相对优势 $A_i=\frac{r_i-\text{mean}(r_1…r_G)}{\text{std}(r_1…r_G)}$。从而优化掉了value model,同时来引入训练后模型和reference模型的KL散度来限制两者差距:
DeepSeek R1
DeepSeekR1的模型结构和DeepSeekV3一致,其中大部分的训练/推理技巧也基本一致,可参考:【LLM技术报告】DeepSeek-V3技术报告(全文)。DeepSeekR1技术报告披露了大量的训练细节以及过程中未能生效的尝试,其工作内容主要分为三个部分:
DeepSeek-R1-Zero:
无需SFT数据,仅基于RL就实现了长CoT推理和反思的能力,其核心在奖励函数的设计,主要包含两部分:准确率奖励(直接基于math/code的结果判定)、格式奖励(
… 类似的格式规则),其思路可以表达为:关注推理的中间过程是否正确无法实现,所以只能 rule-based reward。报告中指出,随着训练过程的持续,发现模型的输出tokens明显增多,即触发了“深度思考”,同时也出现了“顿悟”时刻( aha moment):DeepSeek-R1:
基于少量高质量CoT数据冷启动->RL->SFT->全场景RL,进一步提升模型输出的可读性和准确度。
其中,冷启动的数据生成的思路包括:基于few-shot指导模型生成,以及Zero模型输出进行人工标注做细化,数据格式为:|special_token
|special_token<summary>。后续的RL训练则侧重语言一致性:一定程度降低了模型性能但是提高了可读性。第三阶段的SFT侧重点在于提升模型的综合能力,其中的关键步骤在于推理数据的生成,R1模型生成数据后基于拒绝采样,同时过滤掉混合语言、长段落和代码块的思维链,提升数据质量,同时也加入了一些不使用思维链回答的简单问答的数据(总共80w数据,Reasoning data 60w,包含具体的奖励结果,Non-Reasoning data 20w)。最后在上一阶段SFT模型基础上进行最后的RL训练,提升各场景性能外,侧重保证模型的安全性和无害性。 蒸馏:
展示了基于CoT模型蒸馏小模型提升性能的能力,其中小模型直接基于RL训练可能存在能力不足的问题:即长CoT的推理范式对小模型来说,学习难度过大。蒸馏可将「大模型的推理轨迹」直接转移给小模型,小模型只需要模仿大模型相对完备的推理流程,可以在较小训练/推理开销下取得远胜于自身独立强化学习的效果。
报告中,直接基于R1 SFT的80w数据对QWen、Llama的模型进行微调,显著提高了小模型的推理能力。值得一提的是:RL阶段的蒸馏实现,报告中未涉及,deepseek的说法是希望将 RL 阶段的深入探索留给更广泛的研究社群去完成。
失败的尝试:
PRM:
主要分为三个方面:细粒度的推理步骤难以定义;中间步骤标注/判断要求高,难度大,很难scale up;模型化的PRM容易被reward-hacking。
MCST:
困难在于两个方面:推理的搜索空间过大,训练很难到全局最优;value model训练困难。

Kimi 1.5
Kimi_1.5同样开源了其技术方案,与DeepSeek R1相比,其给出了更多的训练/部署细节。且从整体思路上,Kimi 1.5和DeepSeek R1有点不谋而合的意味:
两者都抛弃了value model,提高了训练效率,采用多个采样的方式来评估相对生成质量(kimi 1.5认为这种方式有利于生成更长的CoT,提高泛化性);两者同样没有使用PRM,仅基于最后的result计算reward;都基于固定的prompt-format的方式来指导模型进行CoT的构造,而不依赖于MCST。
细节上,kimi 1.5的训练过程包括几个部分:预训练、SFT、Long CoT SFT、RL;显然核心在于Long CoT SFT和RL过程:
RL数据生成:考虑了多样性、均衡难度(easy/moderate/difficult)、可评估性。其中数据的筛选策略为:SFT模型采样+pass率筛选的方式。
Long-CoT SFT
prompt-format:包含几个认知过程:Planning/Evaluation/Reflection/Exploration;SFT数据集基于这些关键认知过程进行构建。
RL策略:希望无需显式构建搜索树,而是训练模型近似此过程,其策略优化目标为:
\[\mathop{\text{max}}\limits_\theta\mathbb{E}_{(x,y^*)~\mathbb{D}}[\mathbb{E}_{(y,z)~\pi_{\theta}}[r(x,y,y^*)]-\tau\text{KL}(\pi_{\theta}(x)|\pi_{\theta_i}(x))]\]最终模型梯度为:
\[\frac{1}{k}\sum^{k}_{j=1}\lgroup\nabla_{\theta}\text{log}\pi_{\theta}(y_i,z_i|x)(r(x,y_i,y^*)-\mathop{r}\limits^{-})-\frac{\tau}{2}\nabla_{\theta}(\text{log}\frac{\pi_\theta(y_j,z_j|x)}{\pi_{\theta_i}(y_j,z_j|x)})^2\rgroup\]其中$\mathop{r}\limits^{-}=\text{mean}(r(x,y_1,y^),…,r(x,y_k,y^))$,为对同一个问题的多个采样的reward的均值,替代了value model。除此之外,为了保证训练的稳定性和效果,还引入其他约束:
- Length Penalty 长度惩罚:研究发现模型在RL训练过程中出现overthinking现象,导致响应长度显著增加。尽管这提升了模型性能,但过长的推理过程不仅增加了训练和推理成本,也不符合人类使用偏好。为此,研究引入长度惩罚机制来控制token长度的快速增长,提高模型的token使用效率。
- 样本采样策略优化:尽管RL算法在采样方面表现出良好特性(复杂问题能够提供更大的梯度信息),但其训练效率仍存在限制。研究表明,合理设计的优先采样方法可能带来更显著的性能提升:
- Curriculum Sampling:从简单的任务开始训练,然后逐渐过渡到更有挑战性的任务。
- Prioritized Sampling:跟踪每个问题的成功率$s_i$,并对问题的比例采样至$1-s_i$,这样成功率较低的问题会获得更高的采样概率。
- Long2short:将long-CoT模型的推理模式迁移至short-CoT模型,在token预算有限的约束下提升模型性能,方法有:模型合并、最短拒绝采样、DPO、Long2shortRL。
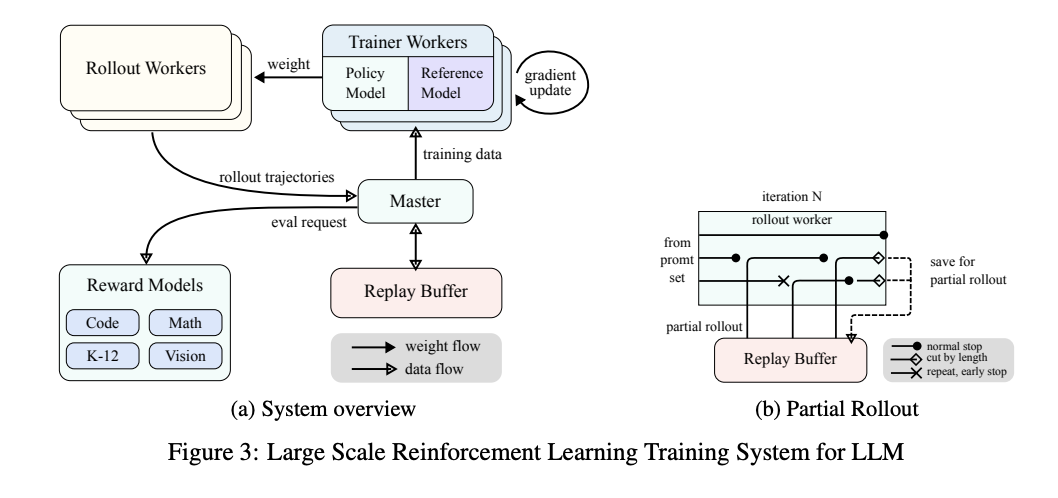
部署工程:
partial rollout
部分滚动技术(Partial Rollouts)是 Kimi k1.5 系统中用于优化长上下文强化学习训练的关键技术,有效解决了长思维链(CoT)特征处理的挑战,提升了训练效率与系统性能。
- 固定token预算:在滚动阶段,为每个滚动轨迹设置固定的输出token预算,限制其长度。
- 异步操作:滚动工作进程异步运行,当部分进程处理长轨迹时,其他进程可独立处理新的短滚动任务,使所有滚动工作进程都能积极参与训练,提高计算资源的利用率,进而提升系统整体性能。
- 迭代分段:将长响应按迭代进行分段处理(从迭代 n - m 到迭代 n)。回放缓冲区存储这些响应段,仅当前迭代(迭代 n)需要进行在线策略计算,之前的段(迭代 n - m 到 n - 1)可从缓冲区高效复用,无需重复滚动。
- 重复检测与惩罚:系统能识别生成内容中的重复序列并提前终止,减少不必要计算,同时对检测到的重复内容分配额外惩罚,有效抑制提示集中冗余内容的生成,提高训练效果。
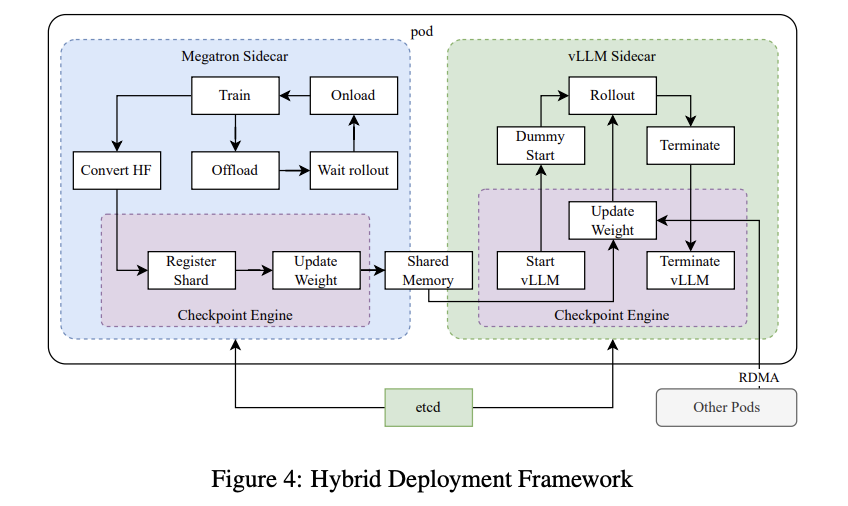
混合部署
训练和推理混合部署,利用Kubernetes Sidecar容器共享所有可用GPU,将训练和推理工作负载整合到同一个pod中。Checkpoint Engine负责管理vLLM进程生命周期,提供HTTP API以触发vLLM操作。系统采用etcd服务管理的全局元数据系统来广播操作和状态,确保整体一致性和可靠性。
AI INFAR的需求和挑战
- Data Transfer:包含中间CoT/KV/模型输入prompt/模型输出logits/checkpoints输出。
- 训推加速:混合部署下,如何进行推理/训练任务的切换;不同训练/推理任务如何异步执行。
- 数据生成:前置数据准备,本质上是离线推理任务,需要考虑如何最大化数据的吞吐,支持拒绝采样等多样采样策略。
- Evaluation:code支持Code Sandbox,支持其他web api等,如天气查询。
未来的一些想法
- 长/短 CoT的统一:无论R1/kimi 1.5都存在过长CoT的问题,DeepSeek R1加入了部分不带思维链的数据,Kimi也引入了很多缩短CoT的工作,但是使用上看,还是存在CoT过长的问题。
- 投机推理:deepseek引入了MTP,其基础上引入投机推理等特性,理论上能带来推理效率的提升/成本降低。
- 更长文本的需求:更长的CoT可能会scale up更强的性能,对AI Infra的需求也更高。
- 异构/分离部署:Prefill/Decode主流的部署方案都采用了不同的部署的方案,异构/分离部署对于降低部署成本/提供灵活性上是必然的。