投机推理概述
Paper
MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads A Hitchhiker’s Guide to Speculative Decoding
Motivation
LLM的decoding阶段通常会受限于显存带宽(memory-bandwidth-bound),因为decoding阶段单次仅生成单个token,导致计算效率偏低。
提高decoding阶段的计算效率,其中一种方式便是:提高单次inference的计算强度/减少deocding的迭代次数。其设计思路是:采用一个轻量的draft model来预测多个token,然后通过original model来refine生成的token,从而减少总的计算量,同时又不损失精度。
Key Points
MEDUSA策略是:
添加了多个head在最后一层的hidden states后,在实际的推理的过程中,连续的heads能生成连续多个token,最后再通过原始模型对多个Candidates进行确认。
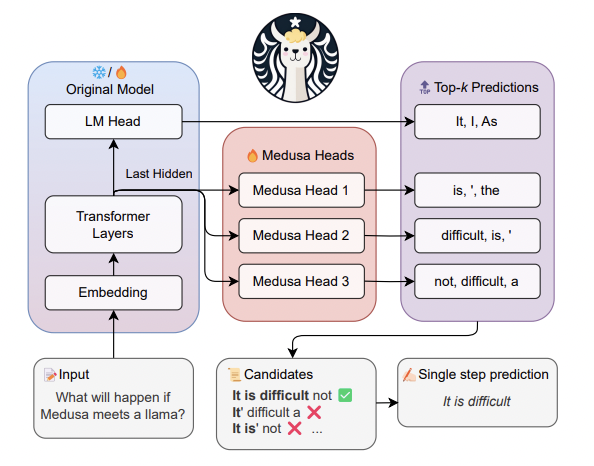
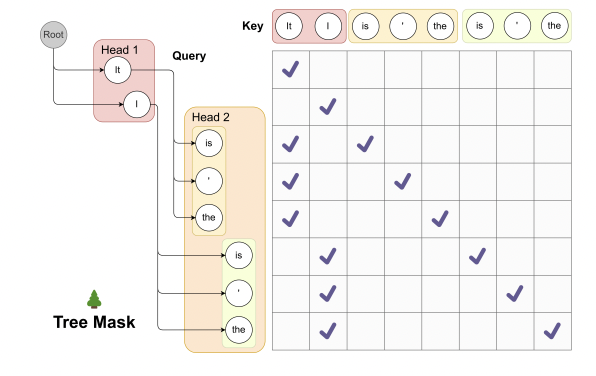
对于多个tokens的计算,采用了Tree-Attention的方式来进行Attention的计算。
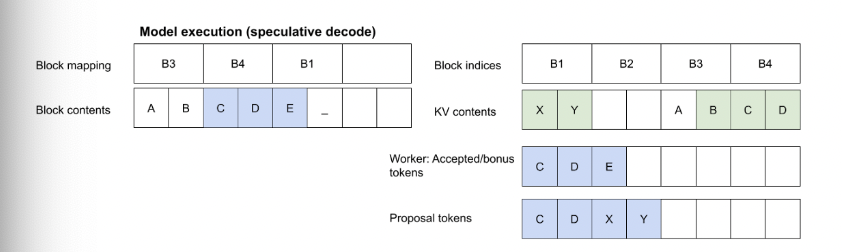
实际部署过程中的一些细节设计:
HEAD的效率问题:更多的HEAD,能够增加单次推理的token数目,如果完全被
original model接受的话,效率更高;但是更多的HEAD,对训练的难度更高,且如果draft model的预测精度不高的话,会造成一定的计算资源/显存损失,实验上看3-4 heads收益比较大,部分常见6-8heads也有比较大的收益。KV-Cache的设计:original model对多个token的验证,Lookahead scheduling设计能够减少对proposal token的KV Cache的重新计算/显存拷贝 。

Statistics
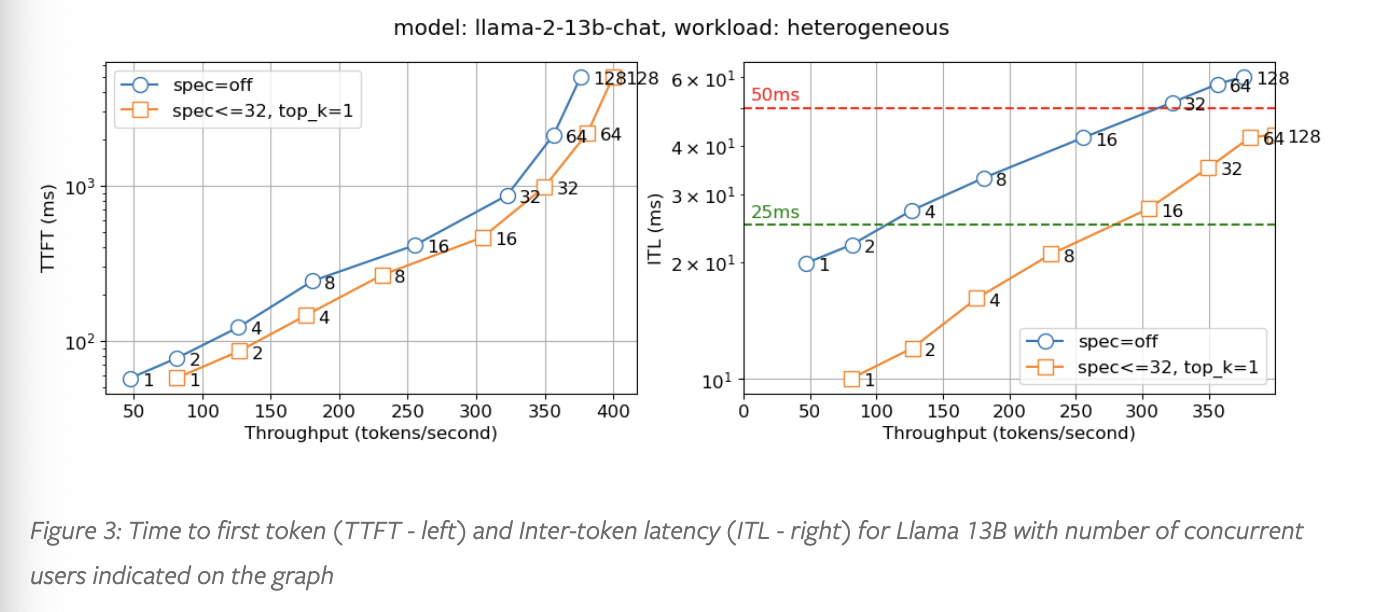
Llama2 13B的测试结果如下,在保持TTFT/ITL一致的情况下,能提升约一倍的吞吐。