前言
影响LLM推理性能的因素有很多,包括但是不限于:模型配置、硬件类型、数据分布、优化算法、推理策略等。本位旨在综述各类技术点,后续会针对核心技术做详细展开。
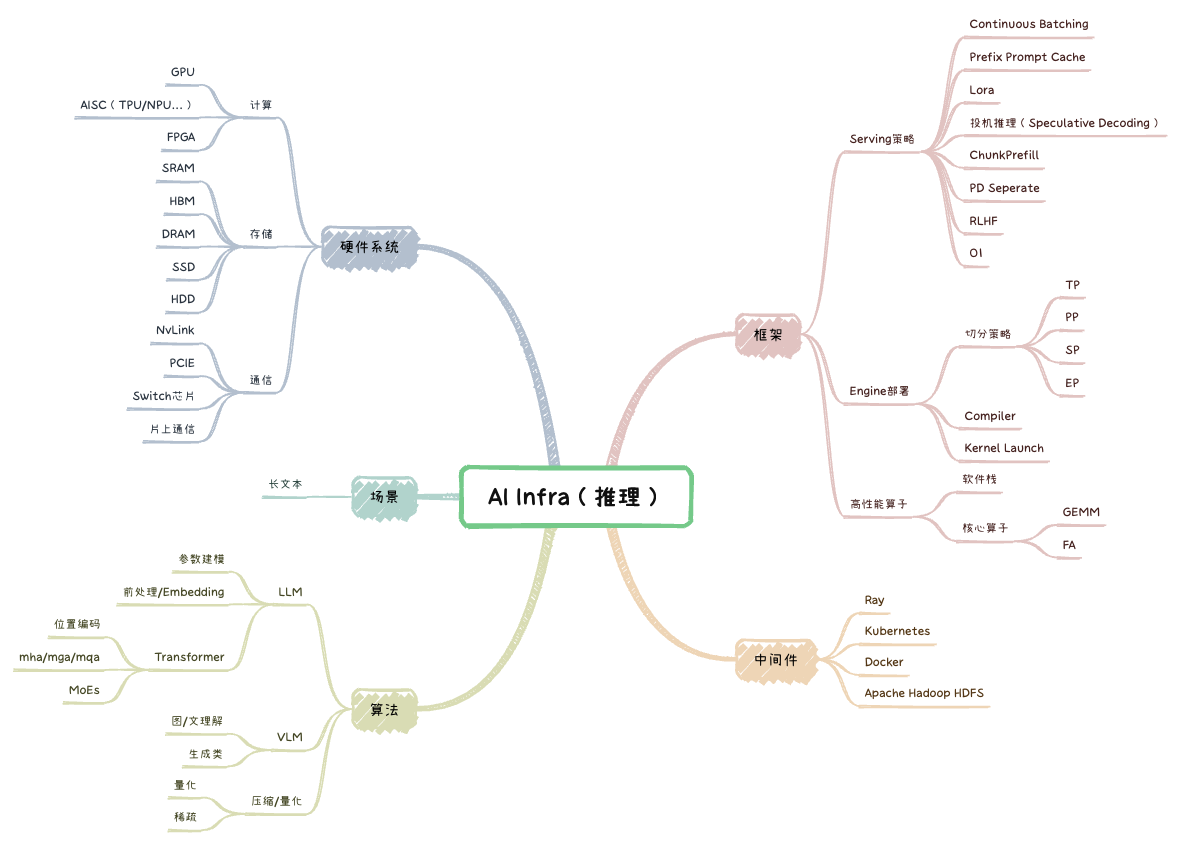
算法
LLM
参数建模
Transformer
量化
框架
开源的LLM推理框架有TensorRT-LLM、FasterTransformer、TGI、vLLM、NanoFlow、SGLANG等,以VLLM为例简单介绍下推理框架:
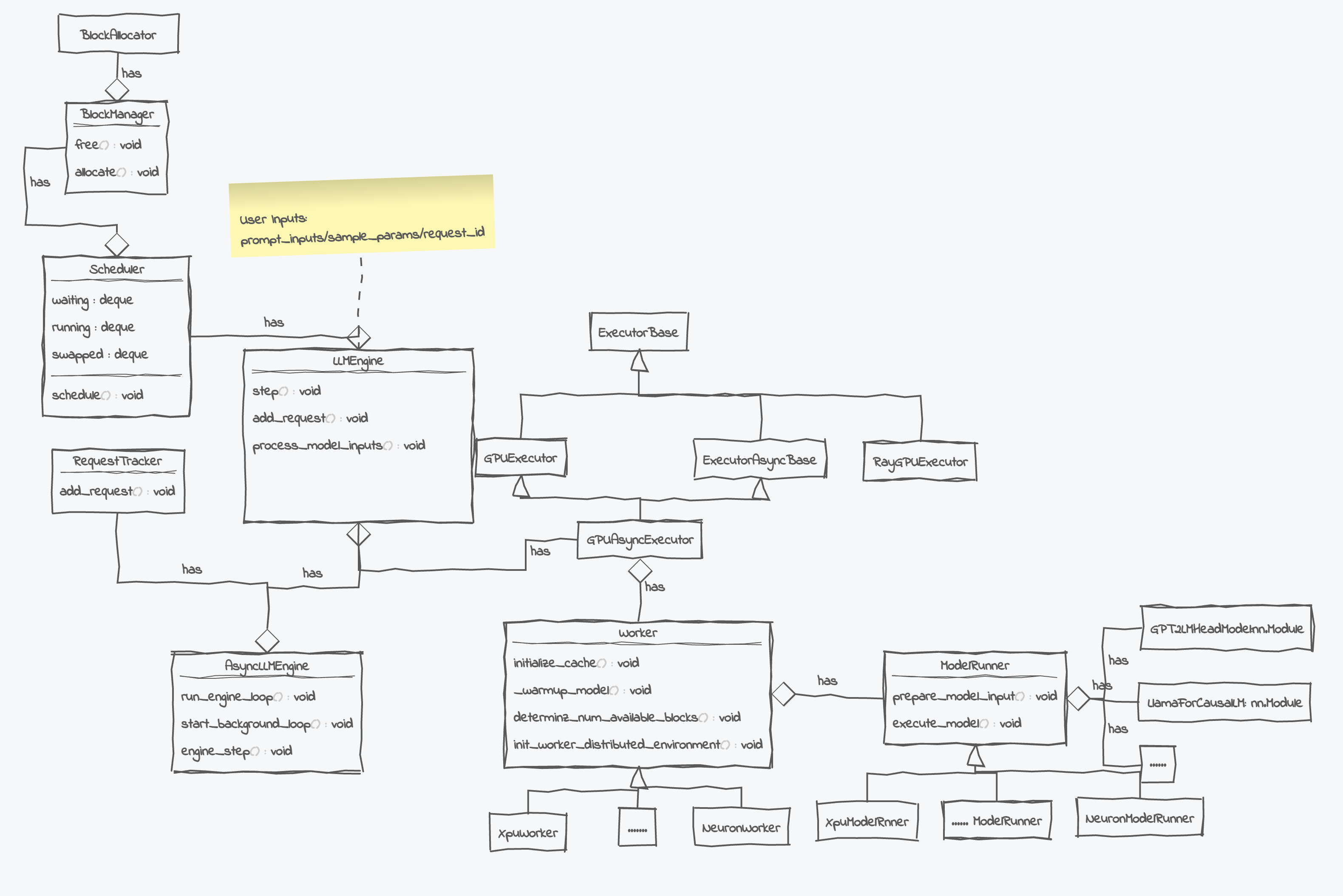
Serving策略
Engine部署
高性能算子
软件栈
算子优化
中间件(TODO)
硬件系统
场景优化
参考资料
LLM推理部署 - 量化(llm.int8,AWQ,GPTQ,SMOOTHQUANT)
CUTLASS:Fast Linear Algebra in CUDA C++
大模型训练之序列并行双雄:DeepSpeed Ulysses & Ring-Attention